







前提和数据:
(三类鸢尾花)class:
-- Iris Setosa
-- Iris Versicolour
-- Iris Virginica
每一类50个属性数据,每项数据包括四个数据项,分别是
1. sepal length in cm
2. sepal width in cm
3. petal length in cm
4. petal width in cm
最后一项为该数据所属的鸢尾花种类
给出部分截图:
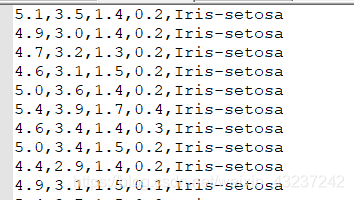
由于文件数据项是用逗号“,”隔开,可直接改成csv格式文件,不行就fopen打开,(我这里是直接导入数据的)
数据处理:
导入数据,分别导入三个50 * 4 的数值矩阵,对应鸢尾花三个种类,且重新命名矩阵为X、Y、Z
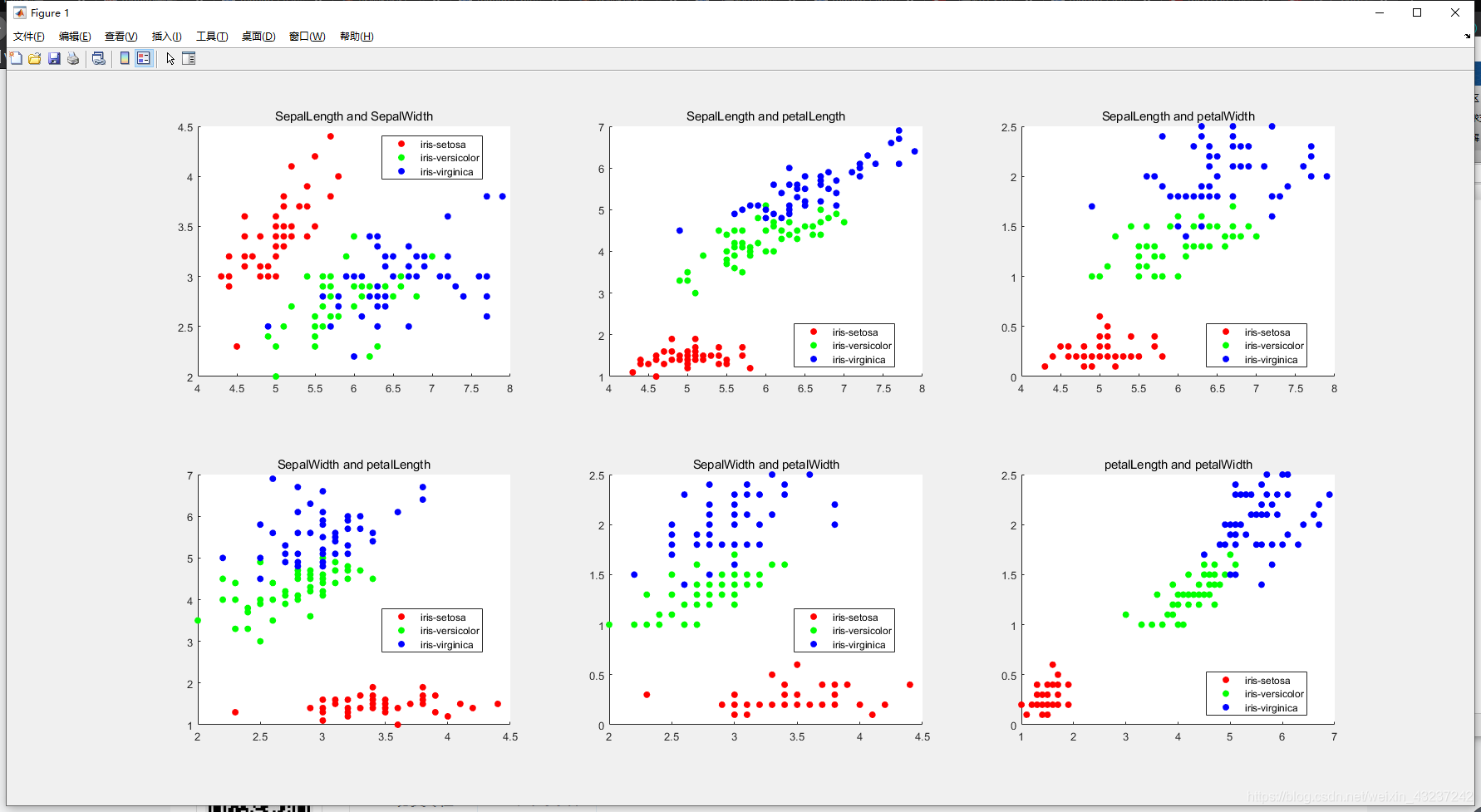
一、散点图绘制(matlab代码):
data = ["SepalLength", "SepalWidth", "petalLength", "petalWidth"];
ans = 1:4;
com = combntns(ans, 2); %四个数据选两个排列组合,相当于C(2,4) = 6;
for i=1:6
subplot(2, 3, i) %2*3的图标
scatter(X(:, com(i, 1)), X(:, com(i, 2)), 'fill', 'r');
hold on
scatter(Y(:, com(i, 1)), Y(:, com(i, 2)), 'fill', 'g');
hold on
scatter(Z(:, com(i, 1)), Z(:, com(i, 2)), 'fill', 'b');
title([data(com(i,1)) + ' and ' + data(com(i, 2))]);
%标题
legend('iris-setosa', 'iris-versicolor', 'iris-virginica', 'location', 'best');
%图标
end;输出截图:
二、K近邻(KNN)对鸢尾花分类:
K-近邻分类算法部分知识点:
K-近邻分类算法:给定一个训练集,对新输入的测试实例在这个集合中找K个与该实例最近的邻居,然后判断这K个邻居大多数属于某一类,于是新输入的实例就被划分为这一类。
k-近邻算法的三个核心要素:
- k值的选取
- 邻居距离的度量
- 分类决策的制定
距离度量
- 欧式距离(最常用)坐标点的平方根
- 汉明距离
- 曼哈顿距离
- 闵氏距离
K的取值
k太小:容易受到异常值的影响
k太大:计算成本太高
以鸢尾花为实例进行分析:
前提描述:
用knn算法实现一个鸢尾花的分类器
四个特征为 :花瓣长度、宽度 花萼的长度和宽度
标签为 :花的类别 0、1、2
1、加载数据
from sklearn import datasets
iris = datasets.load_iris()
# 查验数据规模。
iris.data.shape
# 查看数据说明。
print(iris.DESCR)
#print(iris)2、分割训练数据和测试数据
# 提取特征与标签
# 特征为 :花瓣长度、宽度 花萼的长度和宽度
# 标签为 :花的类别 0——setosa、1——versicolor、2——virginica
x = iris['data']
y = iris['target']
#print(x, y)
from sklearn.model_selection import train_test_split
#从使用train_test_split,利用随机种子random_state采样20%的数据作为测试集。
#x_train是训练数据特征, x_test为测试数据特征, y_train为训练数据标签, y_test为测试数据标签
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=1/5, random_state=0)
3、加载k近邻分类器以及预测(标准化数据)
# 对训练和测试的特征数据进行标准化。
#from sklearn.preprocessing import StandardScaler
#ss = StandardScaler()
#x_train = ss.fit_transform(x_train);
#x_test = ss.transform(x_test)
#print(x_test)
# 从sklearn.neighbors里选择导入KNeighborsClassifier,即K近邻分类器。
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier()
knn.fit(x_train, y_train)
y_pred = knn.predict(x_test)
#y_pred为预测测试数据标签4、 准确性评测和预测数据分析
print("预测正确分类准确率:", knn.score(x_test, y_test)*100, "%")
# 依然使用sklearn.metrics里面的classification_report模块对预测结果做更加详细的分析。
from sklearn.metrics import classification_report
print("预测结果的详细分析:")
print (classification_report(y_test, y_pred, target_names=iris.target_names))参考博客:使用K近邻(KNN)对鸢尾花分类
我的运行代码:
import matplotlib.pyplot as plt
def debug():
print("--------------------bug---------------------")
from sklearn import datasets
iris = datasets.load_iris()
iris.data.shape
print(iris.DESCR)
#print(iris)
debug()
# 提取特征与标签
# 特征为 :花瓣长度、宽度 花萼的长度和宽度
# 标签为 :花的类别 0——setosa、1——versicolor、2——virginica
x = iris['data']
y = iris['target']
#print(x, y)
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=1/5, random_state=0)
#x_train是训练数据特征, x_test为测试数据特征, y_train为训练数据标签, y_test为测试数据标签
print("训练样本长度:" , len(x_train))
print("测试样本长度:" , len(x_test))
#from sklearn.preprocessing import StandardScaler
#ss = StandardScaler()
#x_train = ss.fit_transform(x_train);
#x_test = ss.transform(x_test)
#print(x_test)
#标准化数据后预测准确率达100%,为体现差异,固未将数据标准化
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier()
knn.fit(x_train, y_train)
y_pred = knn.predict(x_test)
#y_pred为预测测试数据标签
for i in range(len(x_test)):
print("实际分类:", y_test[i], ", 预测分类:", y_pred[i])
print(y_test)
print(y_pred)
print("预测正确分类准确率:", knn.score(x_test, y_test)*100, "%")
# 依然使用sklearn.metrics里面的classification_report模块对预测结果做更加详细的分析。
from sklearn.metrics import classification_report
print("预测结果的详细分析:")
print (classification_report(y_test, y_pred, target_names=iris.target_names))
输出如下:
--------------数据说明----------------
--------------------bug---------------------
训练样本长度: 120
测试样本长度: 30
实际分类: 2 , 预测分类: 2
实际分类: 1 , 预测分类: 1
实际分类: 0 , 预测分类: 0
实际分类: 2 , 预测分类: 2
实际分类: 0 , 预测分类: 0
实际分类: 2 , 预测分类: 2
实际分类: 0 , 预测分类: 0
实际分类: 1 , 预测分类: 1
实际分类: 1 , 预测分类: 1
实际分类: 1 , 预测分类: 1
实际分类: 2 , 预测分类: 2
实际分类: 1 , 预测分类: 1
实际分类: 1 , 预测分类: 1
实际分类: 1 , 预测分类: 1
实际分类: 1 , 预测分类: 2
实际分类: 0 , 预测分类: 0
实际分类: 1 , 预测分类: 1
实际分类: 1 , 预测分类: 1
实际分类: 0 , 预测分类: 0
实际分类: 0 , 预测分类: 0
实际分类: 2 , 预测分类: 2
实际分类: 1 , 预测分类: 1
实际分类: 0 , 预测分类: 0
实际分类: 0 , 预测分类: 0
实际分类: 2 , 预测分类: 2
实际分类: 0 , 预测分类: 0
实际分类: 0 , 预测分类: 0
实际分类: 1 , 预测分类: 1
实际分类: 1 , 预测分类: 1
实际分类: 0 , 预测分类: 0
[2 1 0 2 0 2 0 1 1 1 2 1 1 1 1 0 1 1 0 0 2 1 0 0 2 0 0 1 1 0]
[2 1 0 2 0 2 0 1 1 1 2 1 1 1 2 0 1 1 0 0 2 1 0 0 2 0 0 1 1 0]
预测正确分类准确率: 96.66666666666667 %
预测结果的详细分析:
precision recall f1-score support
setosa 1.00 1.00 1.00 11
versicolor 1.00 0.92 0.96 13
virginica 0.86 1.00 0.92 6
accuracy 0.97 30
macro avg 0.95 0.97 0.96 30
weighted avg 0.97 0.97 0.97 30
三、K-Means聚类算法对鸢尾花聚类
K-Means聚类算法:
k-means算法的思想比较简单,假设我们要把数据分成K个类,大概可以分为以下几个步骤:
1、随机选取k个点,作为聚类中心;
2、计算每个点分别到k个聚类中心的聚类,然后将该点分到最近的聚类中心,这样就行成了k个簇;
3、再重新计算每个簇的质心(均值);
4、重复以上2~4步,直到质心的位置不再发生变化或者达到设定的迭代次数。
鸢尾花聚类(python)
依次给出去掉标签的散点图,鸢尾花散点图,用去掉标签数据聚类生成的散点图
用sepal length 和 sepal width 这两个属性作为聚类数据时
代码如下:
import matplotlib.pyplot as plt
import numpy as np
from sklearn.cluster import KMeans
from sklearn.datasets import load_iris
import pandas as pd
def debug():
print("------------------------bug-----------------")
iris = load_iris()
x = iris['data']
y = iris.target
#绘制无标签散点图
plt.scatter(x[:, 0], x[:, 1], c='blue', marker = 'o', label = 'point')
plt.xlabel('sepal length')
plt.ylabel('sepal width')
plt.legend(loc = 2)
plt.show()
# 绘制sepal散点图
X1 = iris.data
plt.scatter(X1[y==0, 0], X1[y==0, 1], color='r', marker='+', label='setosa')
plt.scatter(X1[y==1, 0], X1[y==1, 1], color='g', marker='x', label='versicolour')
plt.scatter(X1[y==2, 0], X1[y==2, 1], color='b', marker='o', label='virginica')
plt.xlabel('sepal length')
plt.ylabel('sepal width')
plt.title('point_sepal')
plt.legend(loc=2)
plt.show()
#K-Means聚类,k=3
km = KMeans(n_clusters=3)
km.fit(x)
pred = km.labels_
#得到聚类标签
#绘制无标签数据聚类后的散点图
x0 = x[pred == 0]
x1 = x[pred == 1]
x2 = x[pred == 2]
plt.scatter(x0[:, 0], x0[:, 1], c = "r", marker='+', label='label0')
plt.scatter(x1[:, 0], x1[:, 1], c = "g", marker='x', label='label1')
plt.scatter(x2[:, 0], x2[:, 1], c = "b", marker='o', label='label2')
plt.xlabel('sepal length')
plt.ylabel('sepal width')
plt.title('K-Means_sepal')
plt.legend(loc=2)
plt.show()
输出截图如下:
无标签散点图 有标签散点图 无标签数据聚类散点图
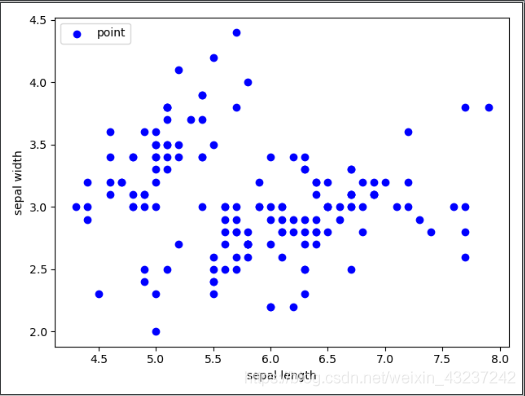
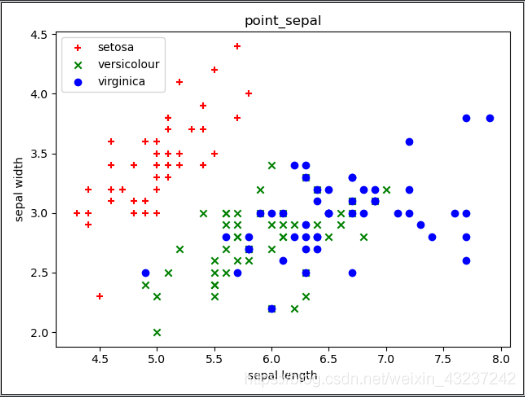
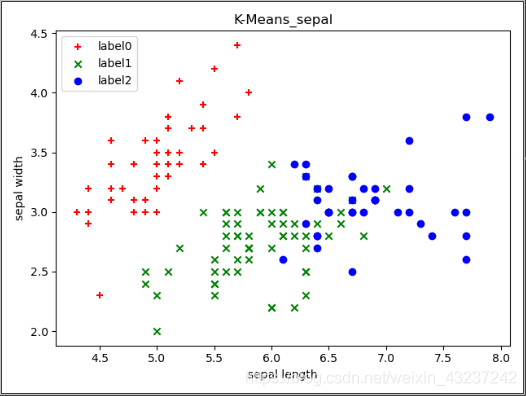
我们发现聚类结果和原标签散点图还是有一些差异的,,,所以接下来我们换后面的两个属性petal length 和 petal width 再试一遍。
用 petal length 和 petalwidth 这两个属性作为聚类数据时:
python代码如下:
import matplotlib.pyplot as plt
import numpy as np
from sklearn.cluster import KMeans
from sklearn.datasets import load_iris
import pandas as pd
def debug():
print("------------------------bug-----------------")
iris = load_iris()
x = iris['data']
y = iris.target
#绘制无标签散点图
plt.scatter(x[:, 2], x[:, 3], c='r', marker = 'o', label = 'point')
plt.xlabel('petal length')
plt.ylabel('petal width')
plt.legend(loc = 2)
plt.show()
# 绘制petal散点图
X2 = iris.data
plt.scatter(X2[y==0, 2], X2[y==0, 3], color='r', marker='+', label='setosa')
plt.scatter(X2[y==1, 2], X2[y==1, 3], color='g', marker='x', label='versicolour')
plt.scatter(X2[y==2, 2], X2[y==2, 3], color='b', marker='o', label='virginica')
plt.xlabel('petal length')
plt.ylabel('petal width')
plt.title('point_sepal')
plt.legend(loc=2)
plt.show()
#K-Means聚类
km = KMeans(n_clusters=3)
km.fit(x)
pred = km.labels_
#得到聚类标签
#绘制无标签数据聚类后的散点图
x0 = x[pred == 0]
x1 = x[pred == 1]
x2 = x[pred == 2]
plt.scatter(x0[:, 2], x0[:, 3], c = "r", marker='+', label='label0')
plt.scatter(x1[:, 2], x1[:, 3], c = "g", marker='x', label='label1')
plt.scatter(x2[:, 2], x2[:, 3], c = "b", marker='o', label='label2')
plt.xlabel('petal length')
plt.ylabel('petal width')
plt.title('K-Means_sepal')
plt.legend(loc=2)
plt.show()
输出截图如下:
无标签散点图 有标签散点图 无标签数据聚类散点图
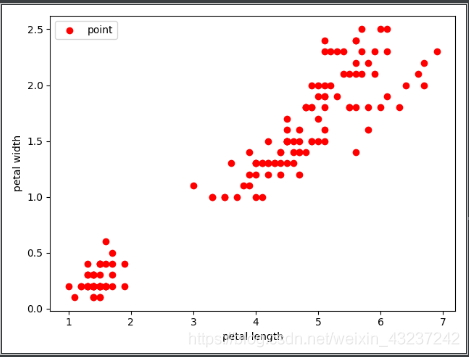
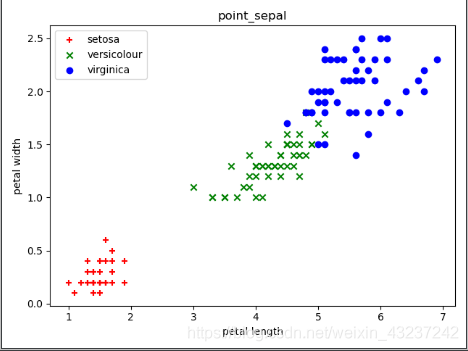
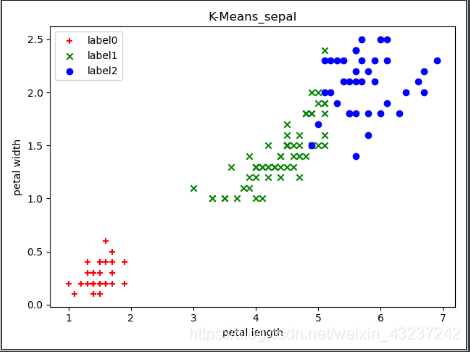
显然,用 petal length 和 petal width 这两个属性作为聚类数据时的聚类效果更好一些。
参考博客:利用python内置K-Means聚类算法实现鸢尾花数据的聚类
#鸢尾花的数据分析到此就告一段落了。。。。
#如有任何代码错误或数据处理不当问题,请评论告知,非常感谢。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









