






摘要
现有的最先进的KD方法用于目标检测,大多基于特征模仿,通常观察到比预测模仿更好。文中指出,ground truth目标与蒸馏目标之间的不一致是蒸馏预测模拟效率低下的主要原因。为了缓解这个问题,我们提出了一个简单而有效的蒸馏方案,称为CrossKD,它将学生检测头的中间特征传递到教师的检测头。由此产生的cross-head预测,然后被迫模仿教师的预测。这种升华的方式使学生的head不再接收来自ground truth注释和教师预测的相互矛盾的监督信号,大大提高了学生的检测性能。
1、介绍
根据检测器的蒸馏位置,现有的KD方法大致可分为两类:预测模仿和特征模仿。预测模仿(如图a)指出教师预测的smooth分布比ground truth的Dirac分布更适合学生学习。换句话说,预测模仿迫使学生模仿老师的预测分布。而特征模仿(如图b)遵循FitNet提出的思想,该思想认为中间特征比教师的预测包含更多的信息。它旨在加强师生对之间的特征一致性。
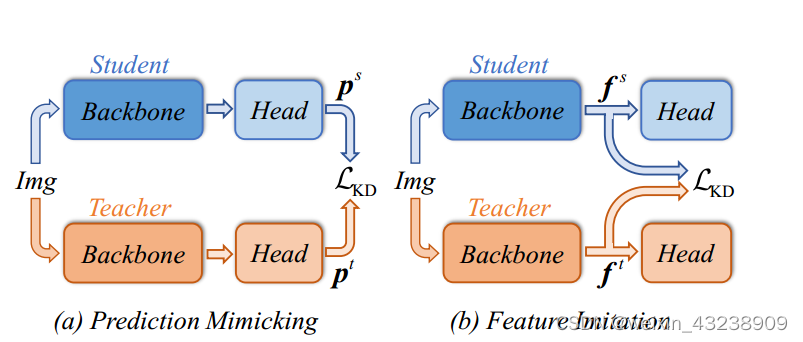
然而,观察到预测模拟比特征模拟效率更低。比如,Zheng等提出了一种定位蒸馏(LD)方法,通过转移定位知识来改进预测模型,将预测模拟推向了一个新的高度。尽管知识追赶先进的特征模仿方法,如PKD,但LD表明预测模仿具有转移特定任务知识的能力,这有利于学生从正交方面进行特征模仿。这促使我们进一步探索和改进预测模仿。
通过观察,我们发现预测模仿需要面对ground truth目标和蒸馏目标之间的冲突,这是以往工作所忽视的。当用预测模仿训练检测器时,学生的预测被迫同时模仿ground turht和教师的预测。然而,教师预测的蒸馏目标通常与分配给学生的ground truth目标有很大的差异。如图2所示,教师在绿色圈出的区域中产生了一个不准确的类概率,这与ground truth目标相冲突。因此,学生检测器在蒸馏过程中经历了一个矛盾的学习过程,我们认为这是阻碍预测模仿获得更高性能的主要原因。

为了解决目标冲突问题,本文提出了一种新的cross-head知识蒸馏(简称CrossKD)。如图c所示,我们建议将中间特征从学生的头部馈送到教师的头部,从而产生cross-head预测。然后,在新的cross-head预测和教师的原始预测之间进行KD操作。尽管它很简单,但CrossKD提供了以下两个优点。
- KD损失不影响部分学生头部的权重更新,避免了原始ground truth检测损失与KD损失之间的冲突。
- 由于cross-head预测和教师的预测都是通过共享教师的部分头产生的,因此cross-head预测与教师预测相一致。
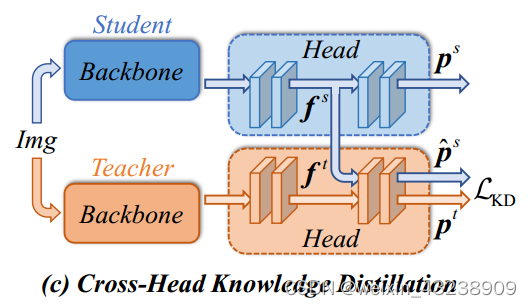
这缓解了师生对之间的差异,提高了预测模仿训练的稳定性。这两个优点使我们的CrossKD能够有效地从教师的预测中提取知识,从而产生比以前更先进的特征模仿方法更好的性能。
2、方法
2.1Preliminaries
先回顾一下两种主要的蒸馏pipelines:特征模仿和预测模仿。
Feature Imitation
feature imitationde提出的目的是加强师生潜在特征的一致性。它的目标可以表述为:
和
表示学生和教师的中间特征,通常是FPN特征。
用于测量
和
之间的距离,例如,均方误差或Person相关系数。
是在整个图像区域R中的每个位置r产生一个权值的区域选择原则。为了避免大的噪声干扰模型收敛,不同的方法可以使用不同的区域选择原则
来选择有效的蒸馏区域,并平衡前景和背景样本的权重。最后,损失将由|S|归一化,|S|是
在整个中间特征上的累积。
特征模仿由于其优异的性能,已成为KD检测方法的主流。然而,他可能会迫使学生模仿老师不必要的噪声,这可能会对最终结果产生负面影响。
Prediction Mimicking
与特征模仿不同的是,prediction模仿旨在通过最小化师生预测之间的差异来转移暗知识。他的目标可以描述为:
和
是由学生和教师的检测头分别产生的预测向量。区域选择
因工作的不同而不同。
是计算
和
之间差异的损失函数。如分类用KL Divergence,回归用L1 损失和LD。如LD所述,由于预测的物理意义明确,预测模仿可以为学生提供特定于任务的知识。
Cross-Head知识蒸馏
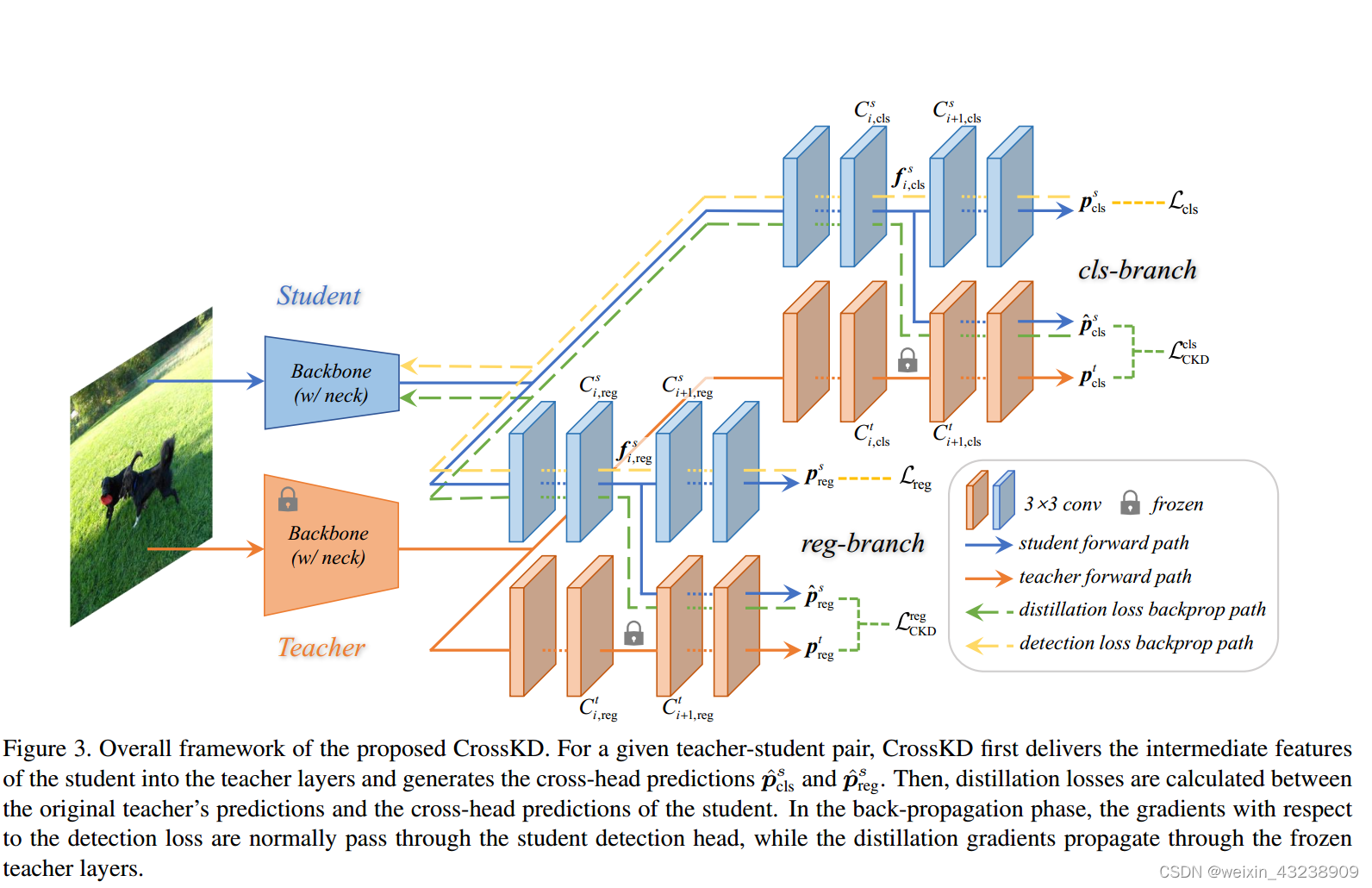
总体框架如图3所示。像许多以前的预测模仿方法一样,我们的CrossKD对预测进行蒸馏过程。不同的是,CrossKD将学生的中间特征传递给教师的检测头,并生成cross-head预测来进行蒸馏。给定一个密集检测器,如RetinaNet,每个检测头通常由一系列卷积层组成,表示为{
}。为了简单起见,我们假设每个检测头中总共有n个卷积层(例如,在RetinaNet中有5个卷积层,四个隐藏层和一个预测层)。我们用
表示
生成的特征映射,
表示
的输入特征映射。预测P是由最后一个卷积层
生成的。因此,对于给定的师生对,教师和学生的预测可以表示为
和
。
除了教师和学生的原始预测外,CrossKD还把学生的中间特征传递到教师检测头的(i+1)卷积层到
层,从而得到cross-head预测
。给定
,不计算
和
之间的KD损失,计算cross-head预测
和教师
的原始预测之间的KD损失作为crossKD的目标,其描述如下:
式中、|S|分别为区域选择原则和归一化因子,我们没有计算复杂的,而是遵循默认操作作为训练密集检测。在分类分支中,
是一个常数函数,其值为1.在回归分支中,
是在前景区域产生1,背景区域产生0的指标。根据每个分支的不同任务(例如分类和回归),我们执行不同类型的
。
通过执行CrossKD,检测损失和蒸馏损失分别应用于不同的分支,如图3所示,检测损失的梯度穿过学生的整个头部,蒸馏损失的梯度通过冻结的教师层传播到学生的潜在特征,这启发式地增加了教师和学生之间的一致性。与直接关闭师生对之间的预测相比,CrossKD允许部分学生的检测头与检测损失相对,从而更好地优化ground truth目标。
2.2 Optimization Objectives
训练的总损失可以表示为检测损失和蒸馏损失的加权和,表示为:
,
是计算学生预测和相应的ground truth目标之间的检测损失,额外的CrossKD损失表示为
、
。这是cross-head预测和教师预测之间进行的。
我们使用不同的距离函数在不同的分支中传递特定任务的信息。在分类分支中,我们将教师预测的分类分数作为软标签,直接使用GFL中提出的Quality Focal Loss(QFL)来拉近师生距离。对于回归,在密集目标检测器中主要有两种回归形式。第一种回归形式直接从anchor boxes(如RetinaNet或ATSS)或点(例如FCOS)回归边界框。在这种情况下,我们直接使用GIoU作为
。在另一种情况下,回归形式预测一个向量来表示框位置的分布(例如GFL),它比边界框的Dirac分布包含更丰富的回归信息。为了有效地提取位置分布的知识,我们采用了KL散度,如LD来转移定位知识。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









