







 本文提出了一种新型网络结构FocalNets,通过替换自注意力机制为FocalModulation,利用深度卷积提取多尺度上下文并控制查询与上下文的交互。实验表明,FocalNets在保持高效的同时在图像分类、对象检测和分割任务上表现出色,优于类似计算成本的SoTA模型。
本文提出了一种新型网络结构FocalNets,通过替换自注意力机制为FocalModulation,利用深度卷积提取多尺度上下文并控制查询与上下文的交互。实验表明,FocalNets在保持高效的同时在图像分类、对象检测和分割任务上表现出色,优于类似计算成本的SoTA模型。
摘要
我们提出了
焦点调制网络
(简称
FocalNets)
,其中
自注意(
SA
)被
Focal Modulation
替换,这种机制
包括三个组件:(
1
)通过
depth-wise Conv
提取分级的上下文信息,同时编码短期和长期依赖;(
2
)
门控聚合,基于每个
token
的内容选择性的聚集视觉上下文;(
3
)通过点乘或者仿射变换将汇集的信息
注入
query
。大量实验表明,
FocalNets
表现出非凡的可解释性,并且在图像分类、对象检测和分割任务上优于具有类似计算成本的SoTA
对应物(例如,
Swin
和
Focal Transformer)
。Focal Net主要是在
block
中加入了
Multi-level
的特征融合机制,类似于目标检测中常见的
FPN
结构,同时学习粗粒度的空间信息和细粒度的特征信息。提高网络性能。
1、介绍
Transformer
虽然效果好,但是效率低。为了提升其效率,已经提出了许多模型。
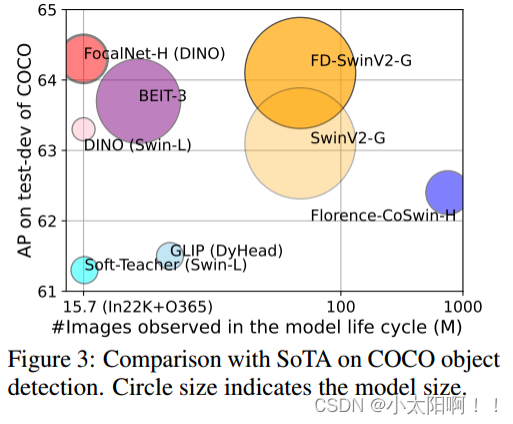
在这项工作中,我们旨在回答一个基本问题,有没有比
SA
更好的办法来建模依赖输入交互?我们首先分析了当前SA
的高级设计。在图
2
中,
2
左侧,我们展示了
ViTs
和
Swin Transformer
中提出的红色查询令牌及其周围橙色令牌之间常用的(窗口式)注意。然而,是否有必要进行如此繁重的互动和聚合?在这项工作中,我们采取了另一种方法
,
首先围绕每个
query
集中聚合上下文,然后用聚合的上下文自适应地
调制
query
。如图
2
右侧所示,我们可以简单地应用查询不可知的焦点聚合
(例如,深度卷积)来生成不同粒度级别的汇总token
。然后,这些汇总的
token
被自适应地聚合到调制器中,调制器最终被注入到query中。这种更改仍然能够实现依赖于输入的令牌交互,但通过将聚合与单个查询解耦,显著简化了过程,因此仅凭几个特性即可实现轻量级交互。我们的方法受到焦点注意力
[95]
的启发
,
焦点注意力执行
多个级别的聚合来捕捉细粒度和粗粒度的视觉上下文
。然而,我们的方法
在每个查询位置提取调制器,
并使用一种简单的方式进行查询
-
调制器交互
。我们将这种新机制称为
Focal Modulation
,用它取代
SA
来构建一个无注意力的架构,简称Focal ModulationNetwork
或
FocalNet。
2、相关工作
self-attention
:
Transformer
通过将图像分割成一系列视觉标记而首次引入视觉。
我们的焦点调制与
SA
有很大不同,它首先聚合来自不同粒度级别的上下文,然后调制单个查询令牌,为令牌交互提供了一种
无注意力的机制
。对于上下文聚合,我们的方法受到
[95]
中提出的焦点关注的启发。然而,焦点调制的上下文聚合是在每个查询位置而不是目标位置执行的,然后是调制而不是关注。这些机制上的差异导致了效率和性能显著提高。另一项密切相关的工作是Poolformer
,它使用池来总结局部上下文,并总结简单的减法来调整单个输入。尽管效率不错,但它在性能上落后于像Swin
这样的流行视觉变换器,正如我们将要展示的那样,捕捉不同层次的局部结构是至关重要的。
MLP
结构。
Visual MLP
可分为两组:(
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 655
655

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









