






摘要
知识蒸馏是一种很有前途的学习紧凑模型的方法,可以利用从复杂的教师网络中继承的信息进行目标检测。本文提出了现有KD方法在目标检测器中的不足,如忽略知识选择、粗糙特征模仿掩码等。为了解决这些问题,提出了一种新的KD框架,通过Logit模仿和特征模仿(LMFI)来训练有效的目标检测。首先,提出了一种新的logit模拟方法来提取分类和定位头。一方面,本文首先提出了对单类目标检测分类logit的模拟。另一方面,利用教师预测和ground truth的定位知识,分阶段动态引导学生对回归输出的学习。其次,设计自适应积极教师选择策略(APTS),在蒸馏过程中获取优质教师样本,减少劣质知识的传播。此外,一个soft度量和细粒度掩模被启发式地引入以位置明智的方式调和教师和学生特征之间的差异。大量实验表明,LMFI在目标检测方面优于最先进的KD框架。它可以显著提高各种检测器在不同基准上的性能。
介绍
目标检测的发展仍然面临着巨大的障碍,例如小尺度和严重遮挡,这对检测精度提出了挑战。近年来,越来越多的研究致力于应对这些挑战。例如,为了检测小尺度物体,一些模型增加了输入分辨率,纳入上下文信息,并进行尺度感知训练。虽然带来了高精度,但具有大量卷积操作的复杂网络变得更加繁琐,这使得它们不适合工业应用。如今,人们提出了许多学习紧凑模型的方法,如剪枝、量化、低秩分解和知识蒸馏。前三种研究主要集中在最小化性能退化的情况下减小模型参数。而他们总是需要定制化的平台,忽视了知识转化的重要性。知识蒸馏是Hinton提出的一种有效的知识蒸馏。KD实现了模型压缩,并通过将过度参数化的教师模型和知识传递给轻量级的学生,找到了模型大小和预测精度之间的权衡。一般的蒸馏框架是为提示学习和模拟分类logit而设计的。由于正负样本的不平衡以及分类和定位的混合知识,直接迁移到检测模型。
针对上述问题,人们开展了一些利用知识蒸馏学习高效目标检测器的研究。Yan根据RPN的比例对正面和负面实例进行抽样。特征模仿方法关心局部邻近目标区域,或者用从解耦特征和解耦建议中提取的知识同时考虑目标和背景区域。为了转移定位知识,chen提出使用教师预测作为伪边界盒回归的上界。Zheng等将边界框转换为概率分布,设计了一种定位蒸馏方法。图1说明了知识蒸馏改进目标检测的有效性。知识蒸馏为我们提供了一种有前途的高级方法来训练具有优越精度的轻量级检测模型。然而,仍然有一些问题尚未探索。首先,在通用知识蒸馏中,分类logit被温度t软化,并被softmax层激活。然而,像行人检测这样的任务只包含一个对象类别,并且每个边界框的预测分数由sogmoid函数归一化。对于这种单类目标检测,需要一种特殊的方法来提取语义信息。其次,传统的教师有界回归损失在一定条件下学习基础ground truth标签,但不直接从教师预测中获取知识。LD针对模糊边界调节回归模式,限制了其对不同检测器的适用性。第三,现有的pipeline并不能抑制低质量的教师样本,这无疑会给知识注入大量的噪音。最后但并非最不重要的是Guo等人和Wang等人生成与对象相关的二进制掩码来提取知识,该方法是粗粒度的,没有考虑点差异。
为了解决上述问题,我们提出了一个具有教师选择策略的新的logit模仿和特征模仿框架,简称LMFI。其中,logit模仿模块在分类logit和定位logit两个方面起作用。其中,我们特别设计了一种提取一类对象检测语义知识的方法;探索了一种创新的定位蒸馏方法,以缓解回归边界不准确的问题,最大限度地利用教师输出和基础ground truth标签。考虑到教师模型的一些预测可能提供错误的指导,我们优化策略,保留有价值的教师样本进行蒸馏。特征模仿是另一种改进训练的方法,通过减少教师和学生之间中间特征的差异。Wang等人发现直接应用提示学习会损害模型性能,因此我们使用损失引导掩模对特征距离给与更大的容忍度。本文的主要贡献总结如下:
(1)对于一类目标检测器,我们设计了一种适应sigmoid函数激活的分类logit的模拟方法。为了模拟本地化logit,来自教师输出的对象坐标和标签指导学生模型的学习,遵循一个精心设计的分段函数。
(2)为了避免从教师检测器中学习到无效信息,提出了一种自适应积极教师选择(APTS)策略,该策略在蒸馏过程中抑制定位或分类质量差的教师样本。(可以学习一下)
(3)我们探索通过掩码引导特征模仿(MGFI)提取细粒度知识。教师和学生特征在相应空间位置上的差异通过soft度量来测量,并通过学生样本的检测损失来重新加权。
相关工作
局部关注学习
为了为目标检测提取知识,将对局部特征和样本进行区分。在教师模型中应忽略低质量的知识,而应重视学生模型的误差预测。在本节中,我们介绍了局部注意的一些应用。包括多实例学习、显著目标检测、图像重建等。
基于注意力的深度机器学习提出了与注意力机制相对应的排列不变聚合算子,并探索每个实例对bag标签的贡献。Bi将航拍场景分类作为MIL问题来研究局部语义。提出的可训练多实例池是基于注意力的,这集中在与场景标签相关的局部语义,直接输出bag级概率。全新的全谷物一种方案(AGOS)框架首次将经典的MIL扩展到多鼓舞配方。它增强了微分扩展卷积特征中的判别信息,突出了MIL攻势下多粒表示中的关键实例、基于局部-全局双感知(LGDP)的深度MIL框架(Bi)由强调局部尺度关键实例的局部金字塔感知模块(LPPM)和提供全局尺度空间权重分布的全局感知模块(GPM)组成。
卷积门控递归单元驱动的多维动态图神经网络(CGRU-MDGN)挖掘脑电图信号的局部空间特征,用卷积层代替GRU的全连接层,同时考虑闹电图信号的局部空间特征和时间序列信息。相关上下文驱动网络(RCNet)被提出用于显著目标检测。它提高了特征的相关性,有效避免了网格化问题和局部信息丢失。通过多层次特征的自适应交互来捕获重要信息。Hwang提出通过最小化边缘和纹理信息的损失来有效地重建高分辨率图像。他们强调字代表的低频特征,从分离的网络中提取全局和局部特征并融合它们。ADE-Net(基于注意力的双掩码分割网络)(Kong)整合了空间和语义信息,关注关键像素区域,丰富了像素级早期火灾检测的特征表示。在我们的框架中,学生模型在选择教师样本后模仿Logits,并使用基于损失的注意力模仿特征。
所提出的方法
蒸馏框架如图2所示,教师和学生模型基于同一检测器,但骨干不同。

为了对齐训练样本,教师和学生特征大小在每个相应的级别保持一致。此外,我们的LMFI从常见模块中提取知识,例如模型neck,分类头和定位头,而没有讨论某些检测器的特殊设计。
Logit模拟分类
对于分类的logit模拟是知识蒸馏中的一种经典的语义知识转移技术。对于多类目标检测,分类Logits由softmax激活。考虑到教师和学生的pre-softmax激活情况 ,一般用温度T软化。教师
,一般用温度T软化。教师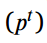 和学生
和学生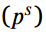 的软预测定义为:
的软预测定义为:

其中,C是类别数量,T设置为2。对于第i个学生样本,分类Logits由教师通过KL散度预测来模拟:

在单一对象类别的检测任务中,检测器只输出一个Logit来表示每个边界框的置信度,通过Sigmoid函数将其归一化为(0,1)。为了提取这些检测器的语义知识,我们也设置了温度T调节师生之间的输出差距,分类的logit模仿损失计算为:
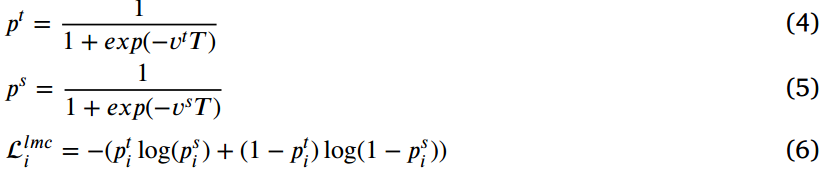
 表示分类头中教师和学生模型的输出对数,
表示分类头中教师和学生模型的输出对数,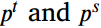 是它们的预测分数。具体来说,本文将T设为1.5,并乘以输出logit。如果
是它们的预测分数。具体来说,本文将T设为1.5,并乘以输出logit。如果 有不同的符号,这意味着师生对样本是积极还是消极的有不同的观点。在这种情况下,温度T增大了
有不同的符号,这意味着师生对样本是积极还是消极的有不同的观点。在这种情况下,温度T增大了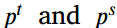 之间的差距,从而增加了
之间的差距,从而增加了 的分数,更加关注样本。否则,T会根据sigmoid的特征缩小
的分数,更加关注样本。否则,T会根据sigmoid的特征缩小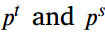 的区别。
的区别。
无论何种类型的目标检测器,LMC都存在正样本和负样本之间的不平衡,这与分类任务中的知识蒸馏不同。为了减少大量负样本对LMC的影响,我们将含有正样本和负样本的输入图像的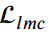 分别计算为DeFeat:
分别计算为DeFeat:
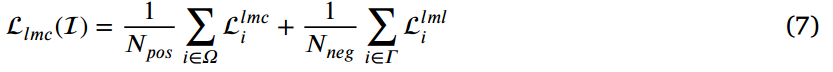
其中 为正样本集,
为正样本集, 为负样本集,
为负样本集, 表明
表明 的元素数量。
的元素数量。
Logit模拟定位
通常,参数化的一个边界框的坐标可以表示为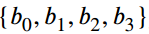 ,如中心坐标和大小为
,如中心坐标和大小为 的盒子或四条边的距离
的盒子或四条边的距离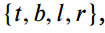 采样点由logit的定位预测。在知识蒸馏中,提供了两组边界框坐标作为参考,一组来自ground truth,另一个组来自teacher的输出,这两组边界框坐标传递了带有标注偏差和回归误差的边界信息。在遮挡等复杂场景中,物体边界是模糊的,检测器和注释器对边界坐标的感知总是不同的。
采样点由logit的定位预测。在知识蒸馏中,提供了两组边界框坐标作为参考,一组来自ground truth,另一个组来自teacher的输出,这两组边界框坐标传递了带有标注偏差和回归误差的边界信息。在遮挡等复杂场景中,物体边界是模糊的,检测器和注释器对边界坐标的感知总是不同的。
对于对象边界的第i个坐标,为了得到学生模型的理想回归目标,我们首先将标注坐标 与教师的回归输出
与教师的回归输出 进行比较:
进行比较:

将 的区间定义为合理回归区间,其中
的区间定义为合理回归区间,其中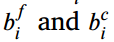 分别表示区间的下界和上界。对于学生模型的ith预测坐标,LML的损失表示为:
分别表示区间的下界和上界。对于学生模型的ith预测坐标,LML的损失表示为:

根据方程可知,当 偏离较大时,我们采用L2损失使其接近合理区间。当位于区间内时,无论从标签还是教师的预测,它都将被自适应边界近似(ABA)引导到它所识别的坐标。此外,我们用一个参数
偏离较大时,我们采用L2损失使其接近合理区间。当位于区间内时,无论从标签还是教师的预测,它都将被自适应边界近似(ABA)引导到它所识别的坐标。此外,我们用一个参数 来平衡L2损失和ABA,该参数在不同的模型中差异很大。例如,FCOS利用从阳性样本到边界框四面的绝对距离作为回归结果,因此应该设置为一个小值。如图3所示,
来平衡L2损失和ABA,该参数在不同的模型中差异很大。例如,FCOS利用从阳性样本到边界框四面的绝对距离作为回归结果,因此应该设置为一个小值。如图3所示, 远离合理区间或在合理区间的中间时,
远离合理区间或在合理区间的中间时,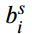 将增大。而无论从区间内还是区间外,当
将增大。而无论从区间内还是区间外,当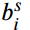 接近
接近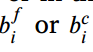 时,损失都减小。
时,损失都减小。
根据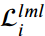 ,得到单个输入
,得到单个输入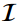 的定位蒸馏损失:
的定位蒸馏损失:

其中 表示正样本的集合,而
表示正样本的集合,而 是
是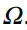 的元素号。坐标值通常设置为4,对于一些特殊的行人探测器,例如CSP,它将变为3。与以前的Logit模拟定位相比,我们充分利用了教师输出和标签的边界信息,同时不改变定位头的结构。
的元素号。坐标值通常设置为4,对于一些特殊的行人探测器,例如CSP,它将变为3。与以前的Logit模拟定位相比,我们充分利用了教师输出和标签的边界信息,同时不改变定位头的结构。
适应性积极教师选择
在学生检测器的学习过程中,生成大量的训练样本,并通过一定的策略将其分配为正负和忽略。例如基于IoU的和基于ATSS的。在LMFI中,师生对的特征大小在每个预测水平上对齐,学生样本将根据空间位置与相应的教师进行匹配。可以推断,并不是所有阳性样本都会参与蒸馏,因为他们的老师可能会因为输出无界而错误地回归。因此,我们提出了一种自适应积极教师选择(APTS)算法来保留值得学习的教师样本。
算法1描述了整个选择过程。我们首先找出每个对象g及其对应的教师样本 在所有预测水平上的正样本。然后,我们计算了
在所有预测水平上的正样本。然后,我们计算了 的预测框和ground truth
的预测框和ground truth 之间的交集(IoU)
之间的交集(IoU) 。将教师样本的最终置信度
。将教师样本的最终置信度 与目标类别上
与目标类别上 的预测分数
的预测分数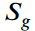 相乘得出教师样本的最终置信度
相乘得出教师样本的最终置信度 ,考虑到分类和定位精度,更能反应样本质量。平均置信度
,考虑到分类和定位精度,更能反应样本质量。平均置信度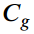 可以作为阈值来抑制
可以作为阈值来抑制 中的无效样本进行蒸馏。可以推断,选择结果对
中的无效样本进行蒸馏。可以推断,选择结果对 比较敏感,如果他们的置信度在阈值之下,将会忽略一些有价值的教师样本。因此,我们设置另一个阈值
比较敏感,如果他们的置信度在阈值之下,将会忽略一些有价值的教师样本。因此,我们设置另一个阈值 ,以降低
,以降低 的影响。通过APTS,将所选择的与所有ground truth G相对应的教师样本
的影响。通过APTS,将所选择的与所有ground truth G相对应的教师样本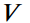 用于Logit模拟,其中包含较少的噪声信息,对学生模型的学习具有积极的指导作用。
用于Logit模拟,其中包含较少的噪声信息,对学生模型的学习具有积极的指导作用。
掩码指导的特征模仿
根据Guo等(2021)的研究,来自内部或外部对象的特征对于知识蒸馏都是必不可少的,不同的区域应该具有不同的重要性。一般算法通过均方误差(MSE)计算特征距离,但这种点对点对应过于严格和刚性。在logit模拟中,教师和学生的样本根据他们的空间位置进行匹配。同样,学生模型对其教师的特征模仿也可以是空间对应的。
在本文中,我们使用Person Correlation Coefficient(OCC)来度量师生对在同一水平上的特征向量的相似性,如图5所示。对于学生某一水平的中间特征 ,首先使用1x1卷积的自适应层对齐特征维度,缩小语义差距后再进行模仿:
,首先使用1x1卷积的自适应层对齐特征维度,缩小语义差距后再进行模仿:

与传统的提示学习相比,PCC的去中心化操作使得特征模仿的损失 对特征映射分布偏差的容忍度更高:
对特征映射分布偏差的容忍度更高:

N是特征金字塔层的数量。分别表示在第n特征层的位置(i,j)上来自教师和被适应学生的特征向量。维度l是向量的长度。 基于PCC计算l-tuple向量综上所述的差异。
基于PCC计算l-tuple向量综上所述的差异。
精心制作的掩码通常是为了达到特定的学习效果。例如,掩码自动编码器(MAE)掩码去掉大量随机的图像补丁子集。它可以用完整的编码补丁和掩码token以像素为单位重建原始图像。以前的工作倾向于用二值掩码来模拟物体区域附近的特征或物体与背景的解耦特征。但是,基于区域的掩码是粗粒度的,二进制值不能反映各个局部区域的重要性。此外,Li等人的PFI是隐式的,只考虑分类图。对于每个位置的样本,检测损失意味着预测值与ground truth之间的差异,其中损失值较大的点映受到更多关注。因此,我们用学生样本的检测损失重新加权。
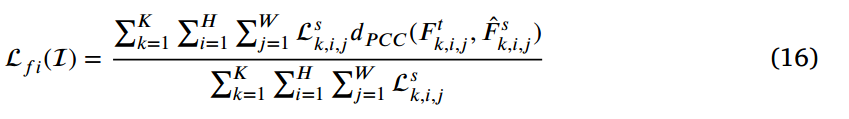
K表示预测级别的数量,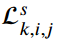 表示k层次上(i,j)的检测损失之和,主要由分类损失
表示k层次上(i,j)的检测损失之和,主要由分类损失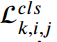 和边界框损失
和边界框损失 组成。我们的mask引导特征模仿更加关注近目标区域和硬样本,这将增强学习阶段重要知识的提炼。
组成。我们的mask引导特征模仿更加关注近目标区域和硬样本,这将增强学习阶段重要知识的提炼。
最终的损失函数
最后,我们将任务损失与我们提出的蒸馏损失结合起来训练学生模型。总损失可以表示为:
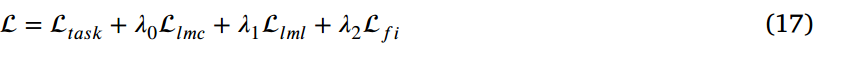















 285
285











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









