from sklearn.decomposition import PCA
from sklearn.ensemble import RandomForestClassifier as RFC
from sklearn.model_selection import cross_val_score
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
data = pd.read_csv(r".\digit recognizor.csv")
X = data.iloc[:,1:]
y = data.iloc[:,0]
X.shape#(42000, 784)
pca_line = PCA().fit(X)# 不指定参数时默认min(x.shape)
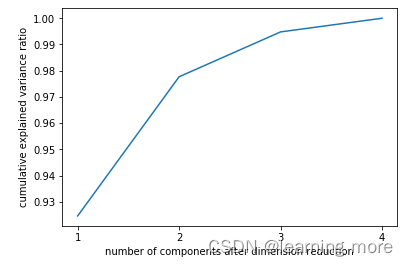
plt.figure(figsize=[20,5])# 可解释性方差累计贡献率
plt.plot(np.cumsum(pca_line.explained_variance_ratio_))
plt.xlabel("number of components after dimension reduction")
plt.ylabel("cumulative explained variance ratio")
plt.show()
#======【TIME WARNING:2mins 30s】======#
score =[]for i inrange(1,101,10):
X_dr = PCA(i).fit_transform(X)
once = cross_val_score(RFC(n_estimators=10,random_state=0),X_dr,y,cv=5).mean()# 使用的是降维数据
score.append(once)
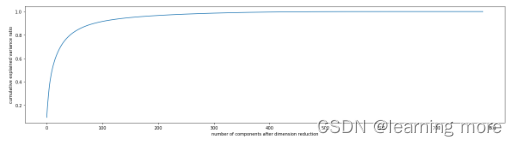
plt.figure(figsize=[20,5])
plt.plot(range(1,101,10),score)
plt.show()
score =[]for i inrange(10,25):
X_dr = PCA(i).fit_transform(X)
once = cross_val_score(RFC(n_estimators=10,random_state=0),X_dr,y,cv=5).mean()
score.append(once)
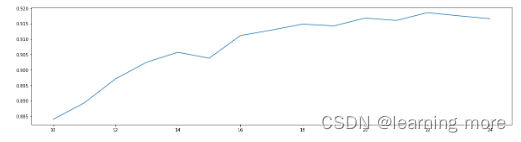
plt.figure(figsize=[20,5])
plt.plot(range(10,25),score)
plt.show()
X_dr = PCA(22).fit_transform(X)#======【TIME WARNING:1mins 30s】======#
cross_val_score(RFC(n_estimators=100,random_state=0),X_dr,y,cv=5).mean()#0.946524472295366from sklearn.neighbors import KNeighborsClassifier as KNN
cross_val_score(KNN(),X_dr,y,cv=5).mean()#KNN()的值不填写默认=5 0.9698566872605972#======【TIME WARNING: 】======#
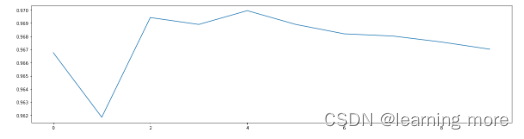
score =[]for i inrange(10):
X_dr = PCA(22).fit_transform(X)
once = cross_val_score(KNN(i+1),X_dr,y,cv=5).mean()
score.append(once)
plt.figure(figsize=[20,5])
plt.plot(range(10),score)
plt.show()






























 760
760











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









