








添加微信公众号可以索取资料
添加QQ群一起分享技术:895467044
先来看看对比一下以前的join,如果对于普通的关系型数据库,我们很容易就想到join应该怎么做的,先来两个场景。
场景一
加入要计算某天对于第7天的留存率,那么对于传统关系型数据库来说,我们只需要计算出留存用户,然后和当天的用户活跃数去做个比值就OK了。
insert into retention_user
select a.id,b.id
from a left join b on a.id = b.id;
where a.dt = date_add(b.dt,-7)
这样就假设筛选出了一个临时的留存用户表,采用的是left join。左边a.id是当天所有用户,而b.id是七天后a中的用户仍然活跃的用户
select count(b.id)/count(a.id)
from retention_user;
场景二
对于一个订单日志,和付款日志表,需要筛选出在下单后的20分钟内付款的数目
select *
from a join b on a.id=b.id where a.ordertime>=b.paytime-1200000;
Regular Join
但是对于上面两个场景,都是简单的认为这个表是有界的,全局的,静态的。也就是说,每次操作都能够对全局的数据进行join。
但是呢,如果是我们的实际情况,比如饿了吗,点单流不断的涌入,付款流也可能不断地涌入,场景二中,我们的数据就变成无界的了(当然从时间上,这种无界的数据流也可以成为有界的数据流,即对时间上20分钟做一个划分而已,当然对于传统关系型数据库去做那种批处理的话,只要筛选出对应时间段即可了,就像上面场景二一样。
但是呢,如果这时候新过来一个数据,是不是又得进行一次计算呢,又得加载所有数据,又得计算一次,因为你不知道哪些数据已经计算过了,哪些数据没有计算过。对吧
上面这种对于全局的数据进行join,在Flink Dynamic Table中叫Regular Join,而在流中的话,这些数据都是以Flink Stream状态形式缓存中,这种“缓存”对吧,还是无界的,你机器再好缓存这么多还是不理想吧。而且有些数据可能根本就已经过期了
所以,这种方式Regular Join,就是不筛选出任何过期的数据了,但是使用情况不理想,所以一般很少用
/**
* 创建环境变量
* */
StreamExecutionEnvironment fsenv = StreamExecutionEnvironment.getExecutionEnvironment();
EnvironmentSettings fsSetting = EnvironmentSettings.newInstance().useOldPlanner().inStreamingMode().build();
StreamTableEnvironment fsTableEnv = StreamTableEnvironment.create(fsenv,fsSetting);
fsenv.setParallelism(1);
/**
* 读取流
* */
DataStreamSource<orderEntity> orderDataStreamSource = fsenv.addSource(new orderEntitySource());
DataStreamSource<payEntity> paymentDataStreamSource = fsenv.addSource(new payEntitySource());
/**
* 流转成Table
* */
Table orderTable = fsTableEnv.fromDataStream(orderDataStreamSource);
Table payTable = fsTableEnv.fromDataStream(paymentDataStreamSource);
/**
* 5分钟=5*60秒=300 000毫秒
* Regular Join
* select * from orderTable join payTable on oid=payid
* where orderTable.orderTime>=payTable.payTime-300000
* */
Table selectResult = orderTable.join(payTable, "oid=payid").where("orderTime>=payTime-6000000");
fsTableEnv.toRetractStream(selectResult, Row.class).print();
try {
fsenv.execute("Regular Test");
} catch (Exception e) {
e.printStackTrace();
}
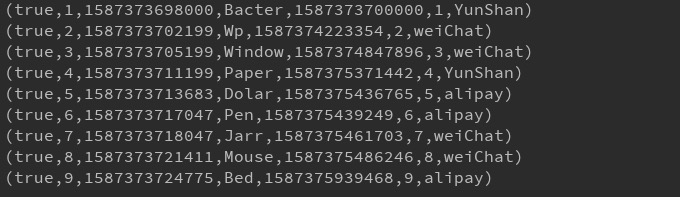
就是这样的执行效果
Time-Window Joins
如果说Regular Join不去丢失过期的缓存数据的话,那么Time-Window Joins,就会适当的丢弃当前窗口外的数据,也就是说,类似于我们在流中使用Window进行计算,当Window触发时就计算当前Window的所有数据,然后进行Join
这种流可以限制上界或者下界
SELECT *
FROM
Orders o,
Shipments s
WHERE
o.id = s.orderId AND
s.shiptime BETWEEN o.ordertime AND o.ordertime + INTERVAL '4' HOUR
比如这样一个查询,它是不会和所有数据进行比对的,只会保存过去4小时,或者未来4小时的数据
上面SQL和下面这个图是限制了order的time上界。

下面这个图就限制了pay的下界了

/**
* 创建环境变量
* */
StreamExecutionEnvironment fsenv = StreamExecutionEnvironment.getExecutionEnvironment();
EnvironmentSettings fsSetting = EnvironmentSettings.newInstance().useOldPlanner().inStreamingMode().build();
StreamTableEnvironment fsTableEnv = StreamTableEnvironment.create(fsenv,fsSetting);
fsenv.setParallelism(1);
fsenv.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
/**
* 读取流
* */
DataStreamSource<orderEntity> orderDataStreamSource = fsenv.addSource(new orderEntitySource());
DataStreamSource<payEntity> paymentDataStreamSource = fsenv.addSource(new payEntitySource());
/**
* 流转成Table
* */
Table orderTable = fsTableEnv.fromDataStream(orderDataStreamSource,"oid,productname,orderTime.rowtime");
Table payTable = fsTableEnv.fromDataStream(paymentDataStreamSource,"payid,paytype,payTime.rowtime");
orderTable.printSchema();
payTable.printSchema();
/**
* 5分钟=5*60秒=300 000毫秒
* Regular Join
* select * from orderTable join payTable on oid=payid
* where orderTable.orderTime>=payTable.payTime-300000
* */
// Table selectResult = orderTable.join(payTable, "oid=payid").where("orderTime>=payTime-6000000");
// fsTableEnv.toRetractStream(selectResult, Row.class).print();
Table selectResult = orderTable.join(payTable).where("oid=payid && orderTime>=payTime-50.minutes && orderTime<=payTime").select("oid,productname,paytype,orderTime");
fsTableEnv.toAppendStream(selectResult,Row.class).print();
try {
fsenv.execute("Regular Test");
} catch (Exception e) {
e.printStackTrace();
}
**注意,使用fromDataStream的时候,需要将我们的时间中的时间注册为某个事件类型,比如处理时间或者事件事件,我这里用的是事件时间,即time.rowtime,如果是处理时间的话就是time.proctime。
Temporal Table
这个有点儿广播设计的感觉,就是一个公用的,不断更新的数据,而且很小,可以给其他表共享的一种感觉。
比如,我们的汇率转换表,它反正数据只有那么多,就只是在更新,它是完全可以保存全局的对吧。
但是呢,Temporal Table和上面的概念还是有一些区别,它存在一个版本的问题,也就是它可能每隔一段时间就要更新一次,而过去的那些数据完全可以不要了,因为以后计算不需要了,就像汇率转换表一样,可能在昨天是这个样子的,而今天货币贬值或者升值,情况又不一样了,所以我们今天去换算就不需要用昨天的转换了,就只需要今天了。
















 2503
2503











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











