







1.word独立生成目录页码
2.word从正文第一页开始自动生成目录
3.word自动生成目录,出现部分文字后面省略号疏密不一致的问题
1.word独立生成目录页码
(1). 一般而言,我们写好的文档会是这样的
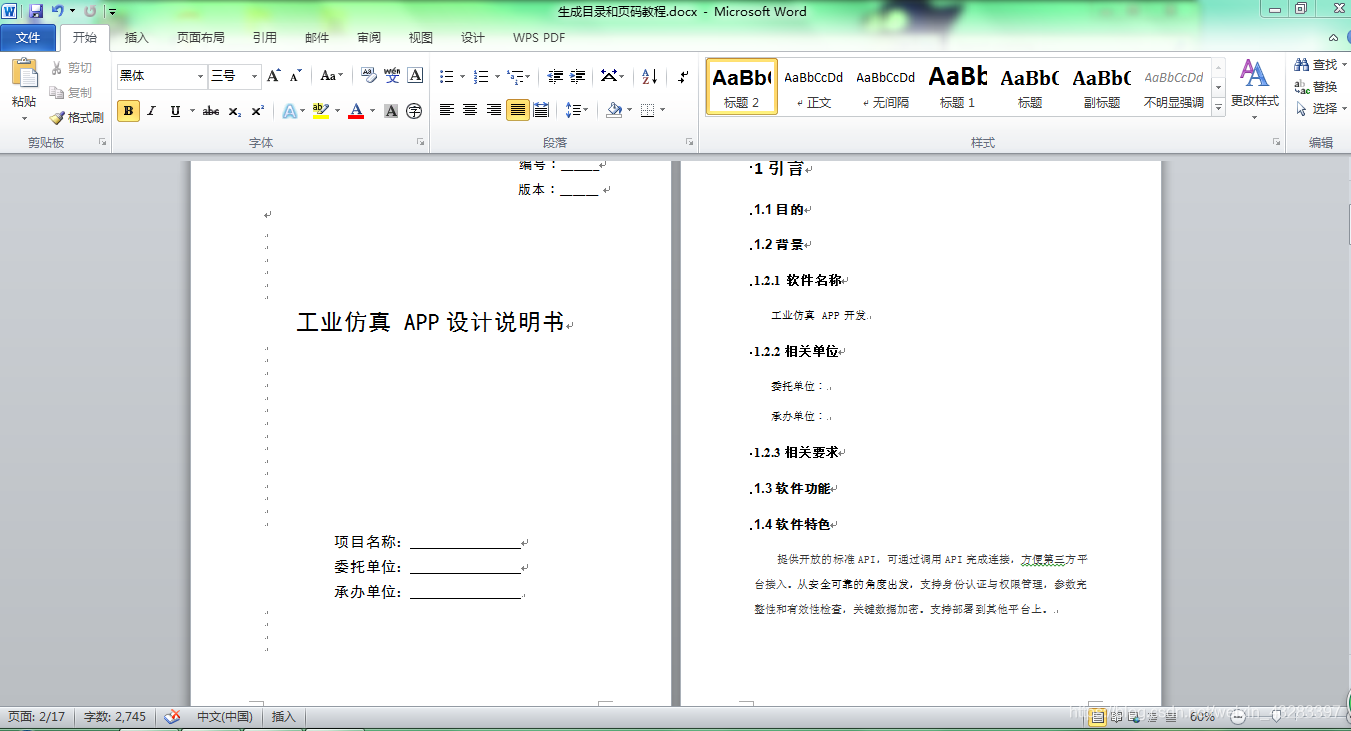
(2). 给文档的各级标题添加 标题样式 ,根据需要设置的标题等级依次选用不同的样式。
首先添加”一级标题“(也可以直接在段落中设置)。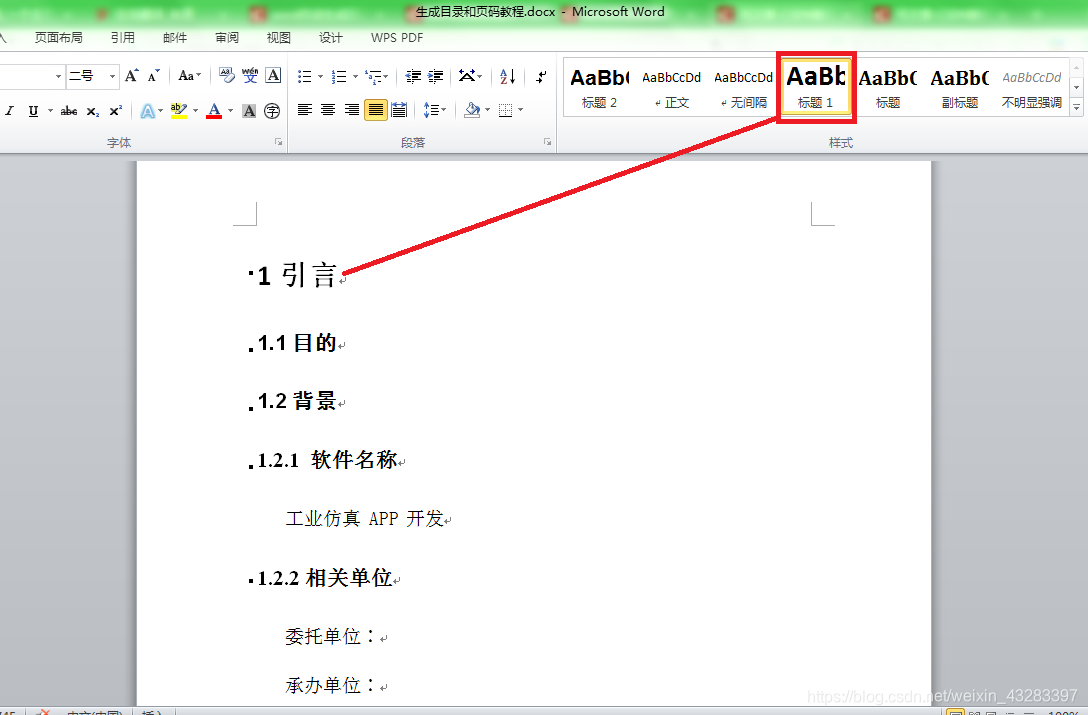
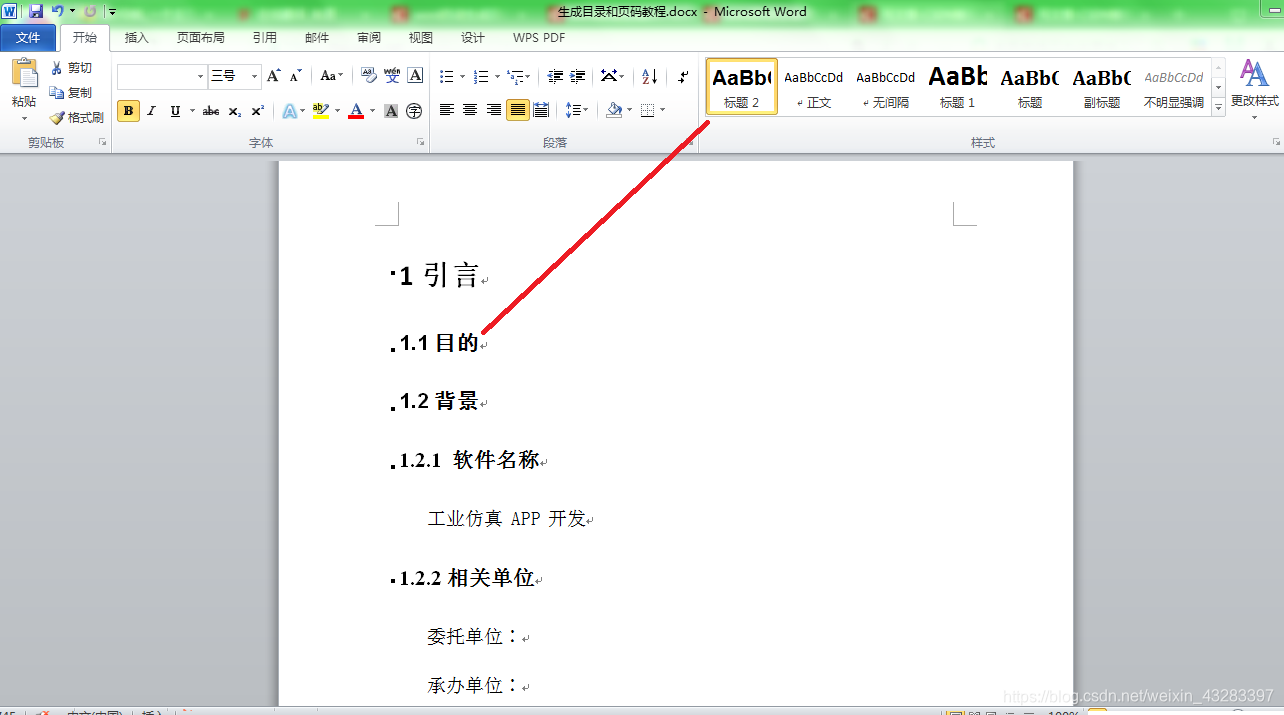
(3). 然后按添加一级标题的方法添加”二级标题“、三级标题等。
(4). 光标定位到封皮空白处,选择 页面布局 – 分隔符 —下一页,生成一页空白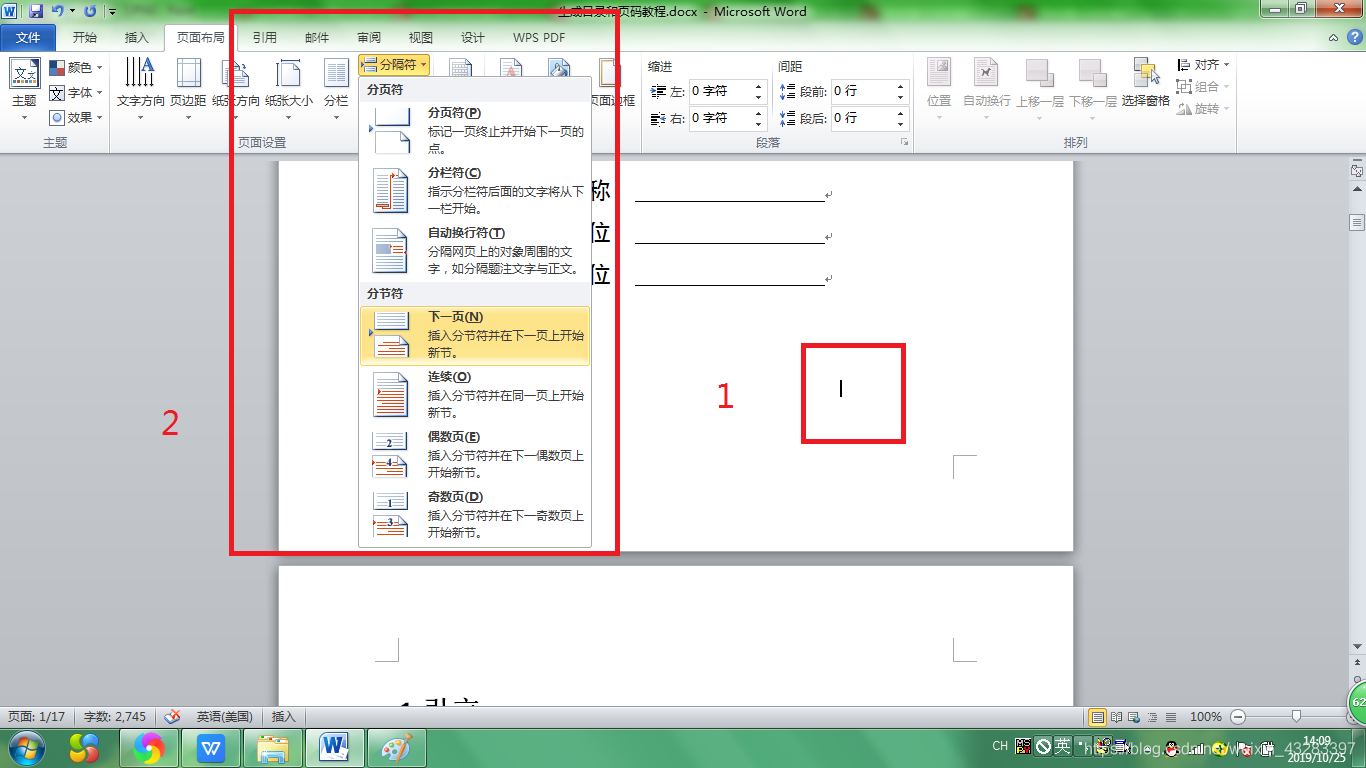
(5). 在正文第一页,双击页脚,取消“链接到前一条页眉”,然后选择页码 – 设置页码格式
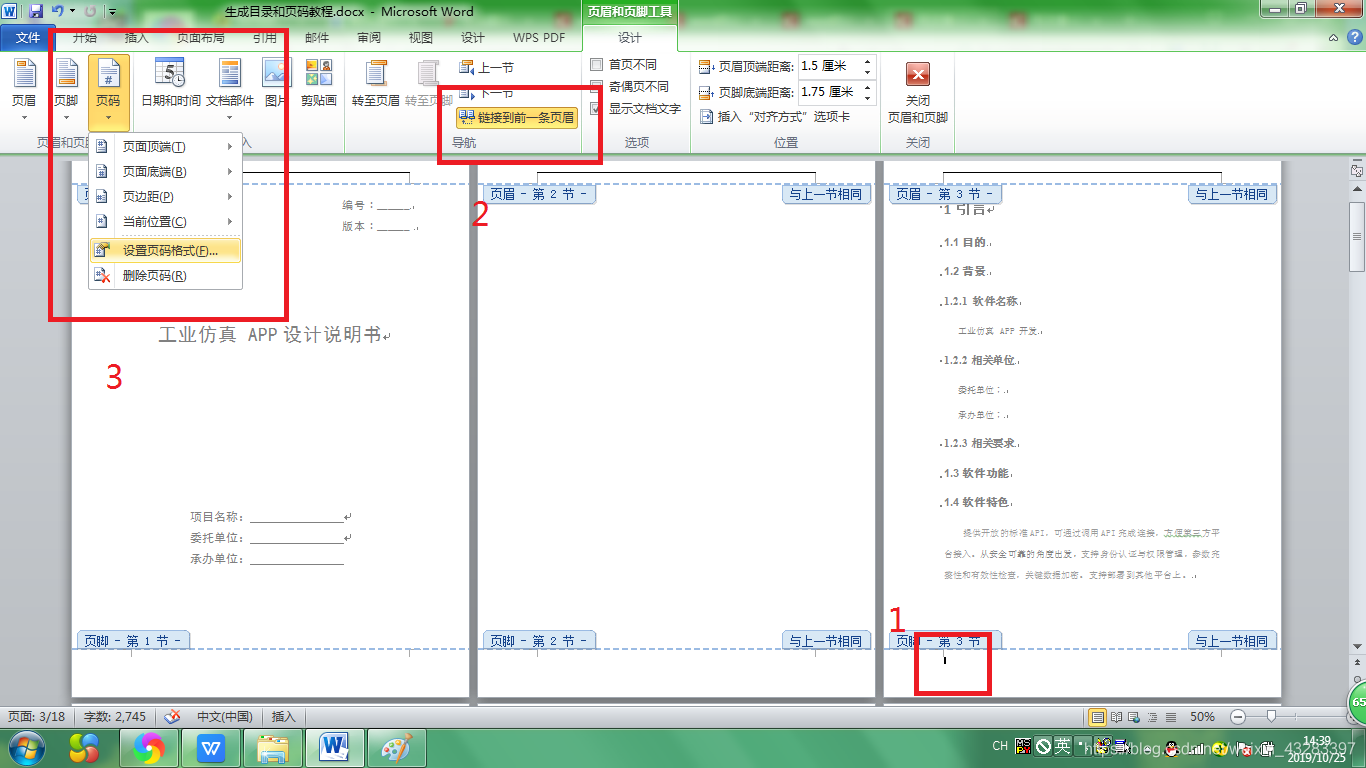
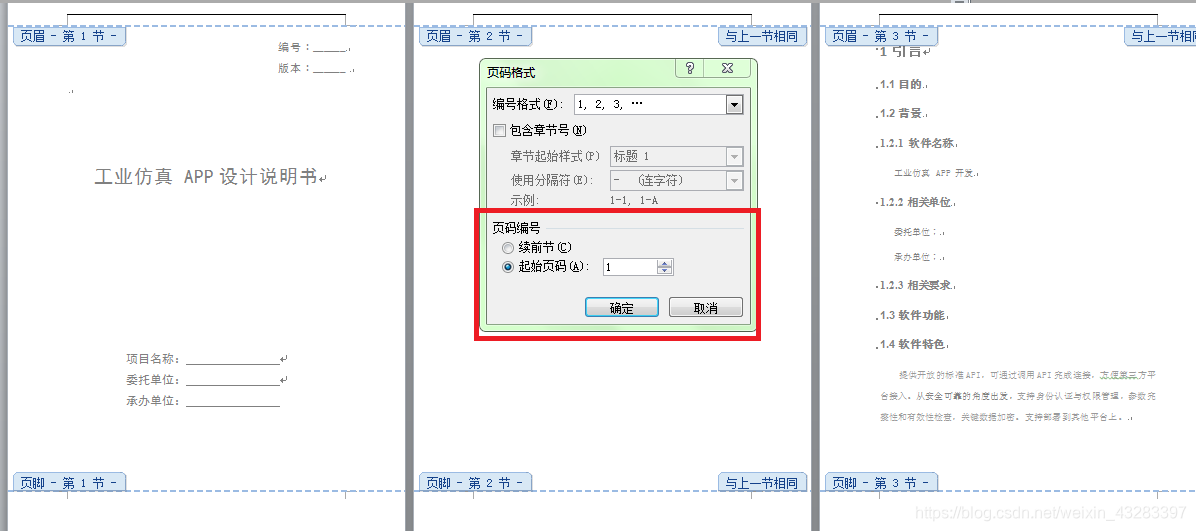
(6). 然后,页码–页面底端–确定
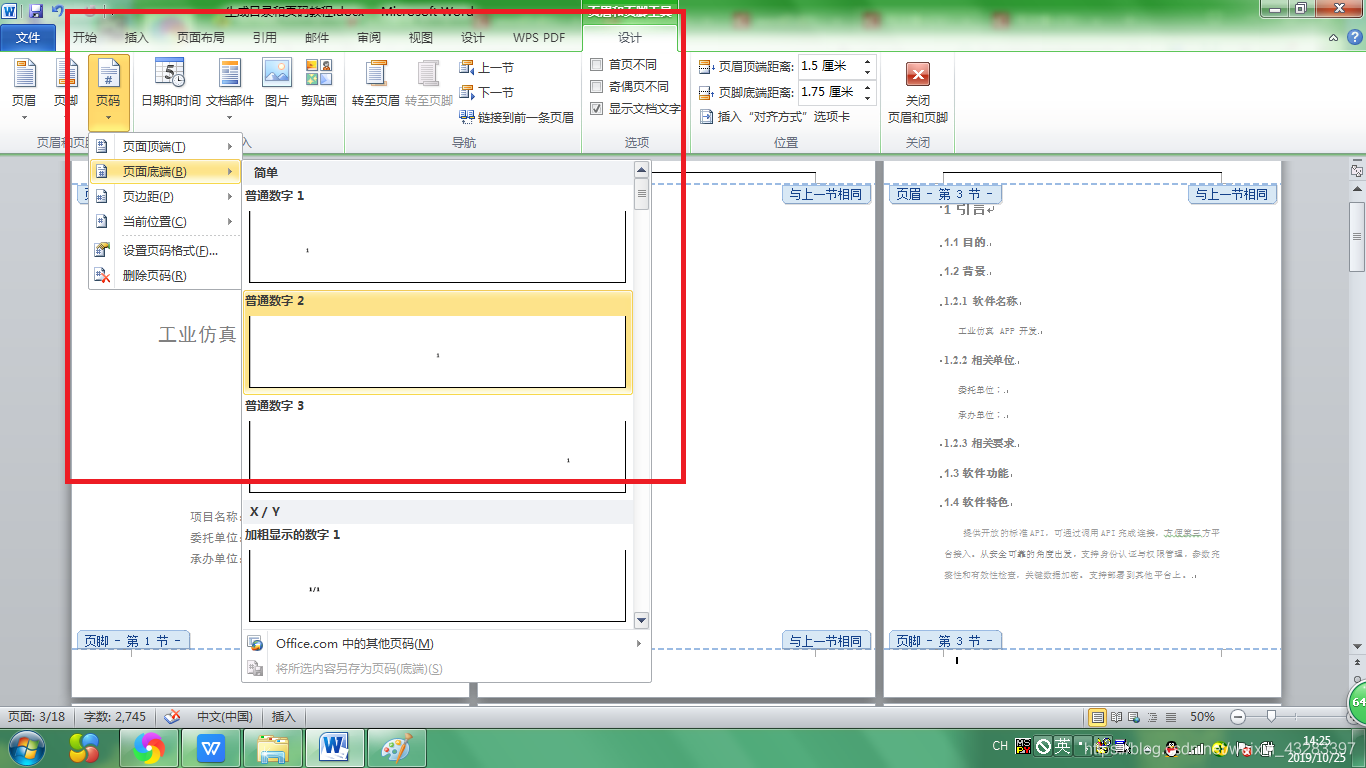
(7).生成页码如下图所示

2.word从正文第一页开始自动生成目录
(1).目录生成有两种,一种是直接选择现有的模板
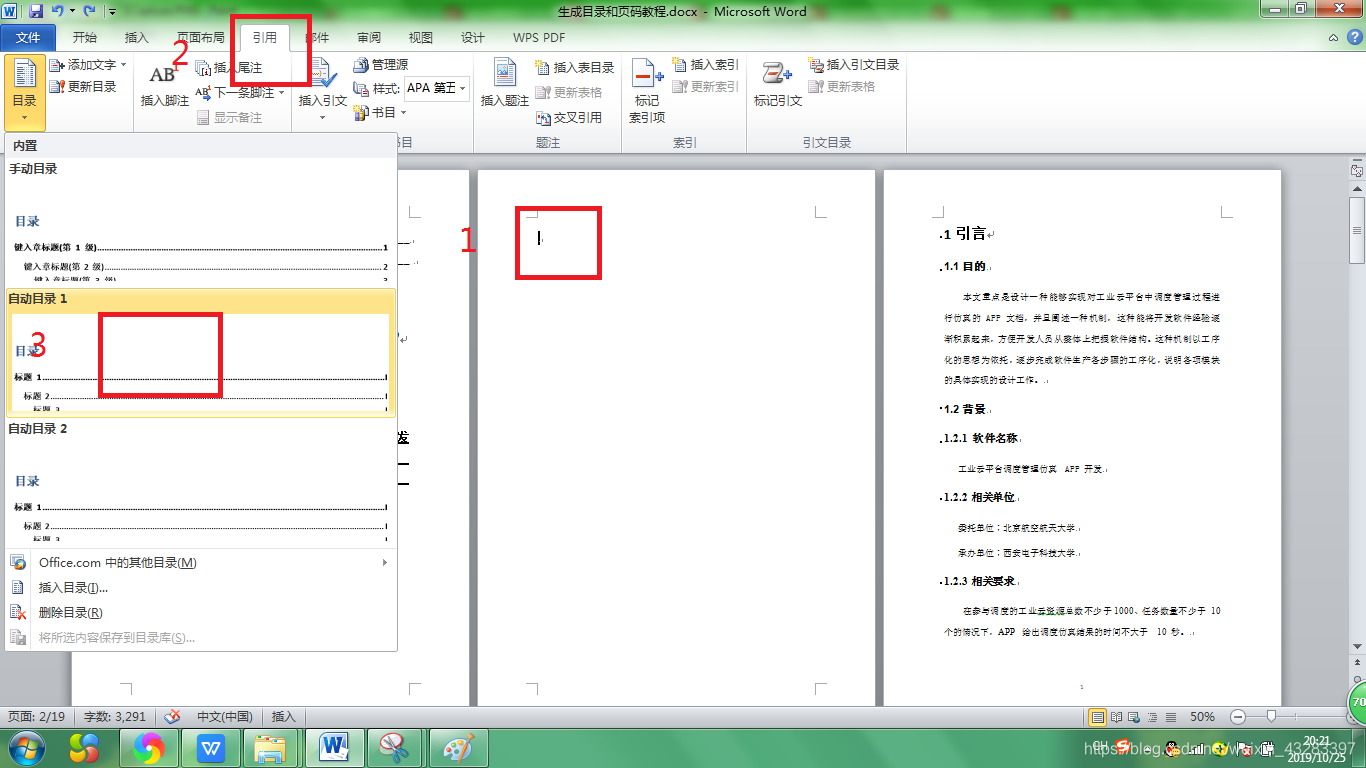
(2).效果为:
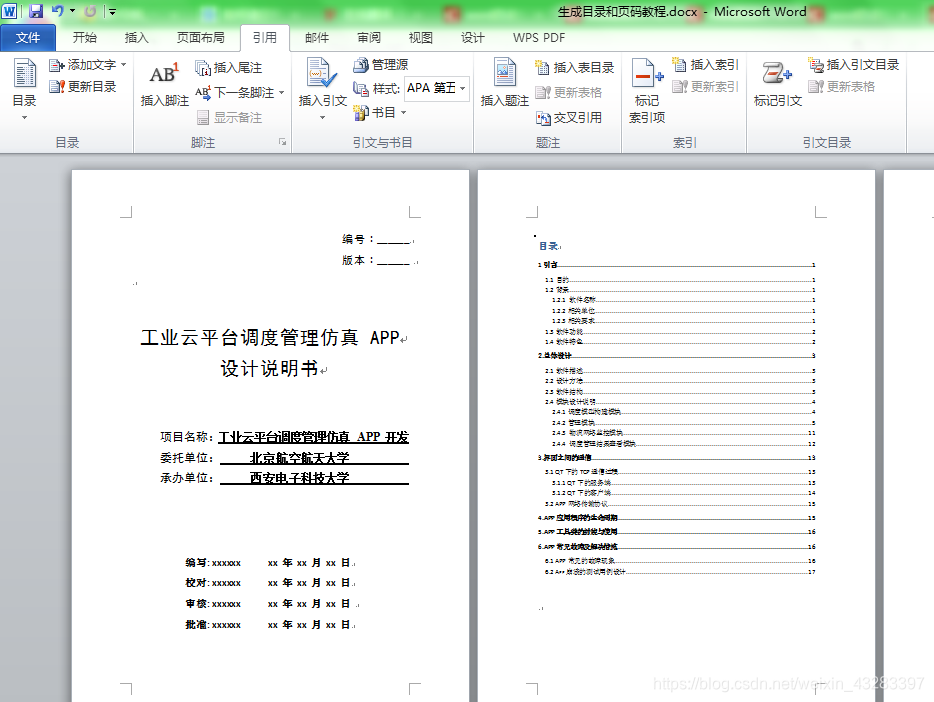
(3).但我们经常遇到的目录级别不止三层,需要自定义生成的目录级别,但目录二字无法生成,所以需要先写上(不写的话不利于后面的排版),然后选择 引用 – 目录 – 插入目录:
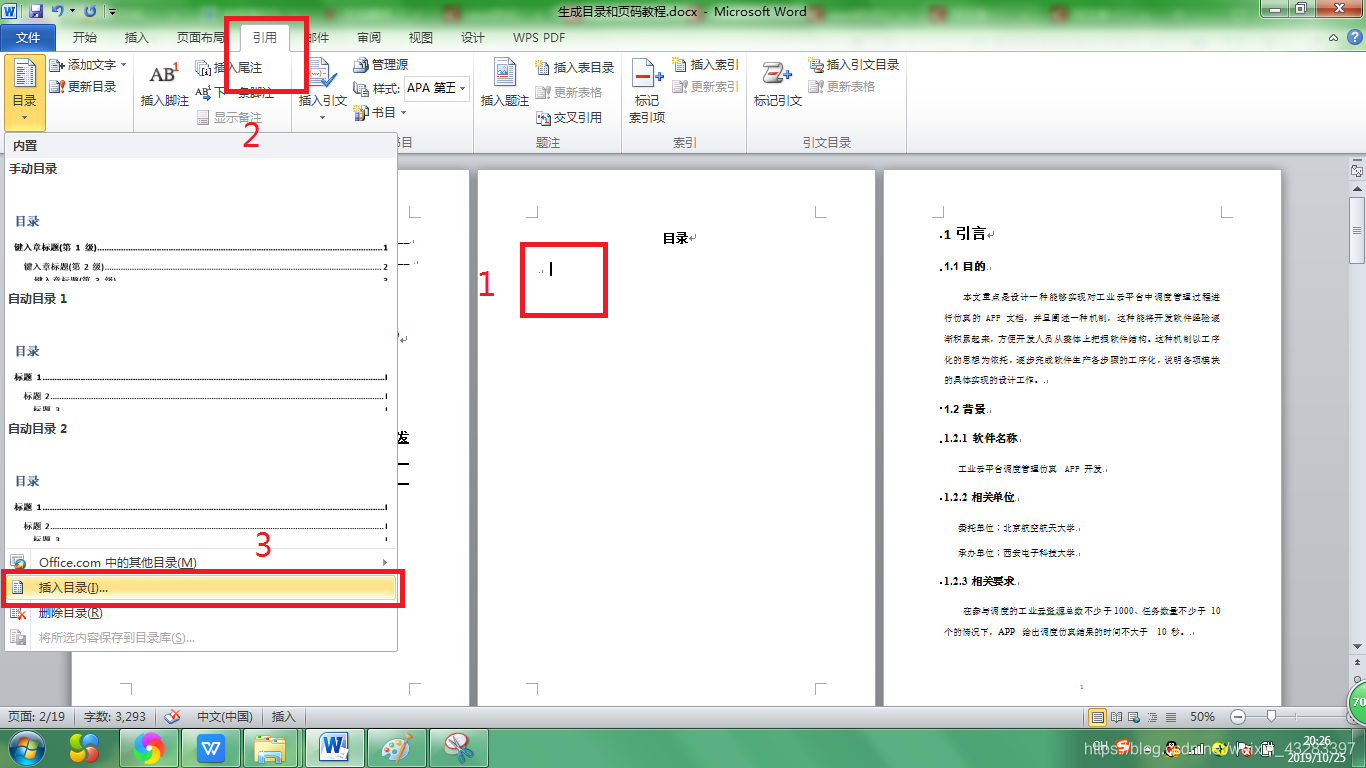
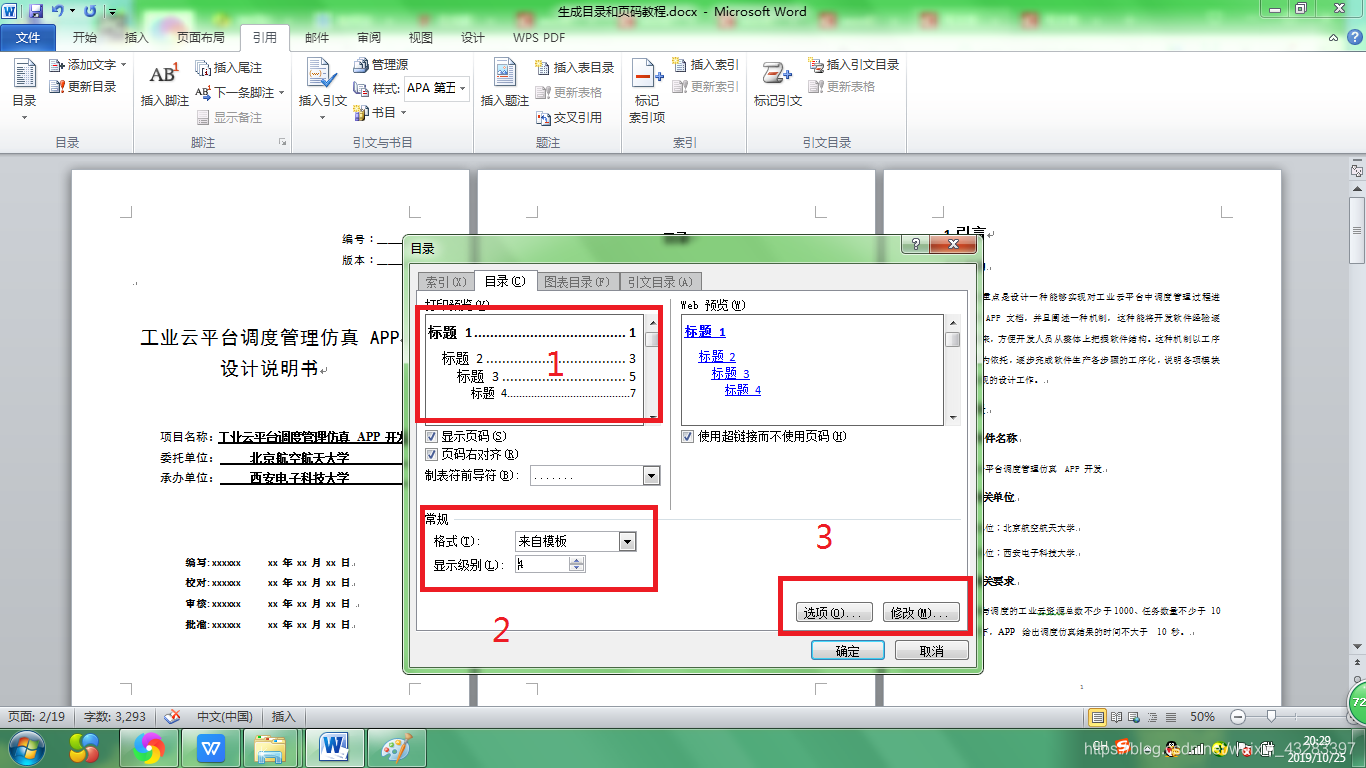
(4).通过预览窗口可以看到效果,通过常规功能区可设置格式,一般都为 来自模板 ,并且选择需要显示的目录数
(5).效果为:
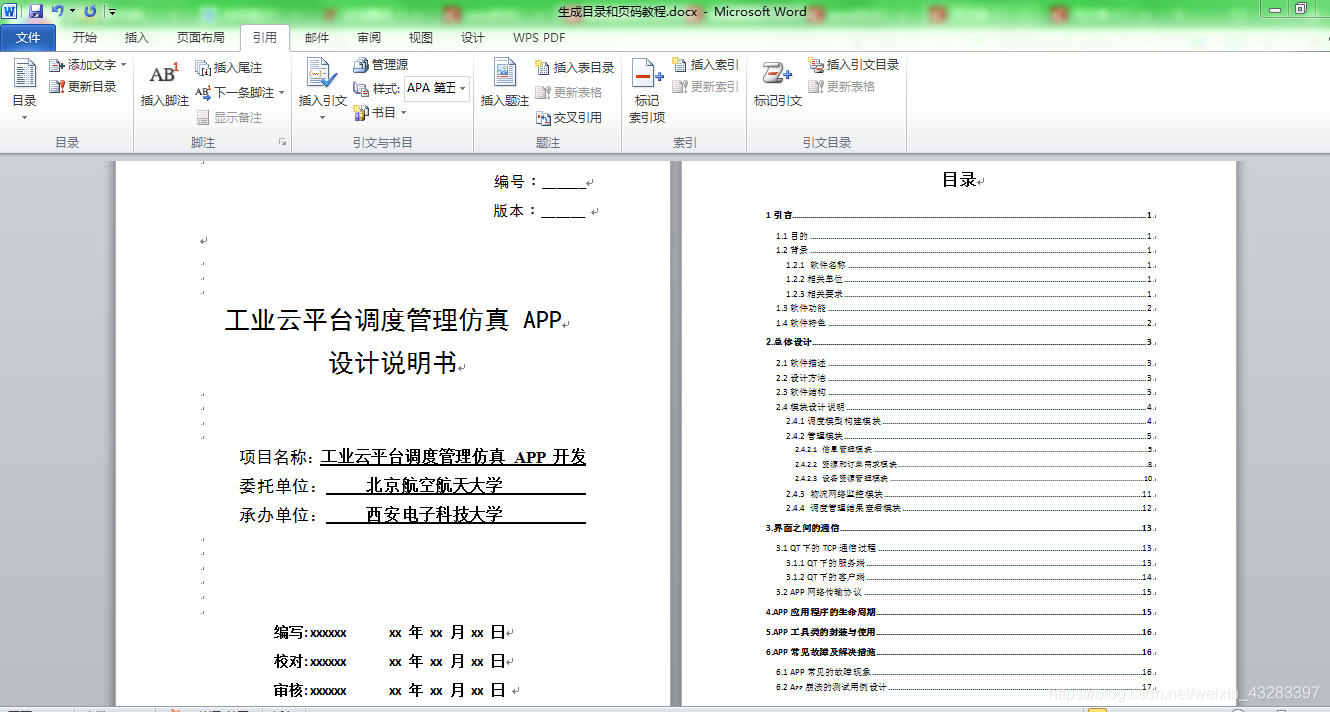
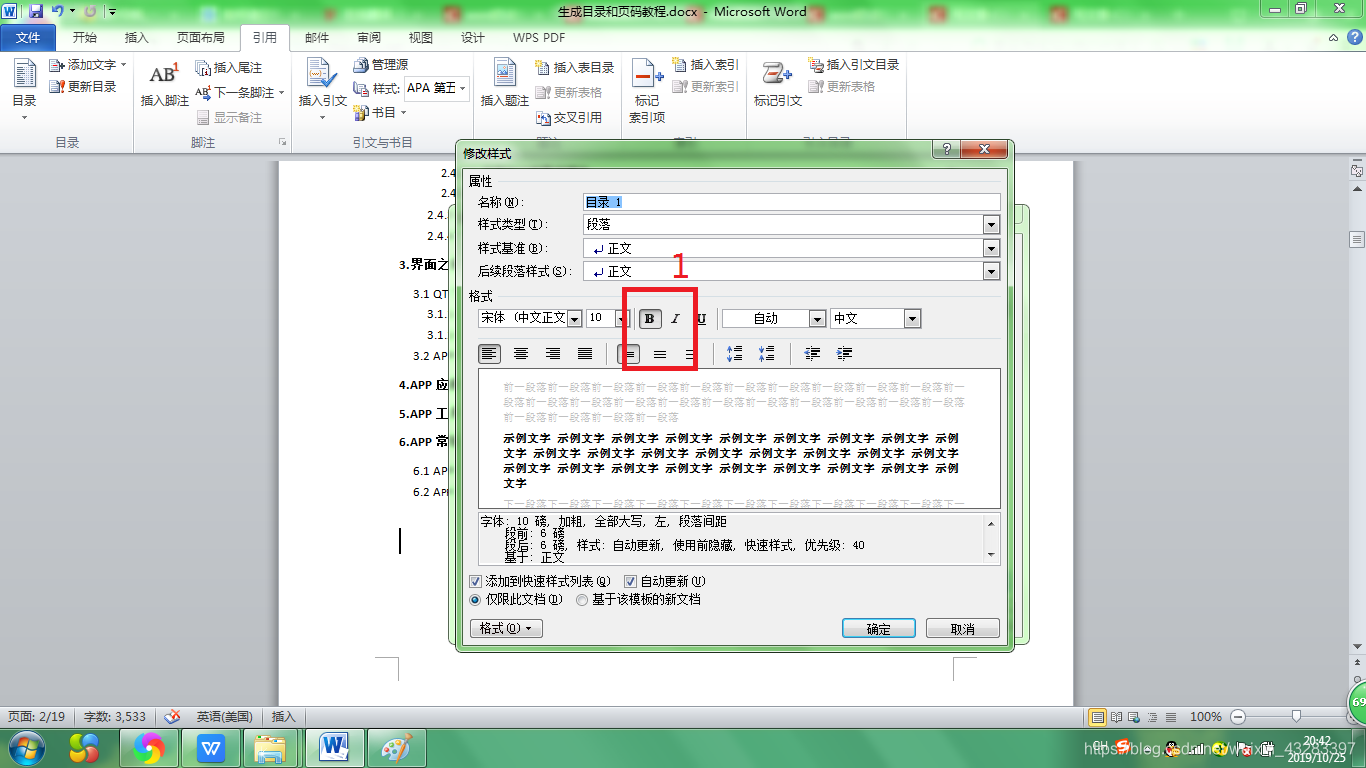
(6).在这里,一级标题为 加粗体 ,如果需要修改,点击 修改 按钮

(7).在这里我们选择将加粗标记去除掉就好了
3.word自动生成目录,出现部分文字后面省略号疏密不一致的问题

这是由于省略号被设置成了宋体或者其他字体,导致省略号是中文习惯,间隔偏大。
选中目录,将其设置成Times New Roman即可解决问题。



















 1143
1143

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









