







卷积神经网络(CNN)由输入层、卷积层、激活函数、池化层、全连接层组成,即INPUT-CONV-RELU-POOL-FC。
1. 卷积
1.1 单通道、一个卷积核的例子
卷积操作的作用是为了进行特征的提取,下图以 5*5 矩阵 A (一副图像的像素值),使用一个3*3的卷积核 (矩阵B) 在该 5*5 的图像上做卷积。
卷积过程:对矩阵A从左上角开始先取一个和卷积核矩阵B相同shape的子矩阵和矩阵B对应元素乘积之和,结果作为卷积结果矩阵的第一个值。

例如,滑动窗口在左上角,第一个特征值的计算,可以按照对应颜色点乘再求和得到:1*1+1*0+1*1+0*0+1*1+1*0+0*1+0*0+1*1=4。
滑动窗口向右滑动一格,覆盖的位置对应的子矩阵与卷积核矩阵点积,结果就是第二个特征值,具体计算为:
1*1+1*0+0*1+1*0+1*1+1*0+0*1+1*0+1*1=3。其他特征值的计算类似。

生成卷积之后的矩阵的大小是(5-3+1)*(5-3+1)的矩阵。

在卷积的过程中,会有下面几个参数:
- 深度depth:每一层神经元个数,决定输出的depth厚度。同时代表滤波器个数。
- 步长stride:决定滑动多少步可以到边缘。
- 填充值zero-padding:在外围边缘补充若干圈0,方便从初始位置以步长为单位可以刚好滑倒末尾位置,通俗地讲就是为了总长能被步长整除。
滤波器是负责通过执行卷积运算从实际图像中提取特征的。现有多种滤波器用于提取图像的不同特征,从而产生特征图。特征图的深度是所用滤波器的个数。如果使用5个滤波器来提取特征,并产生5个特征图,那么特征图的深度为5。 ----- 《Hands-On Reinforcement Learning…》
1.2 多通道、多卷积核的例子
下述动图中,左边是输入,中间部分是两个不同的滤波器Filter w0、Filter w1(即核函数),最右边则是两个不同的输出。
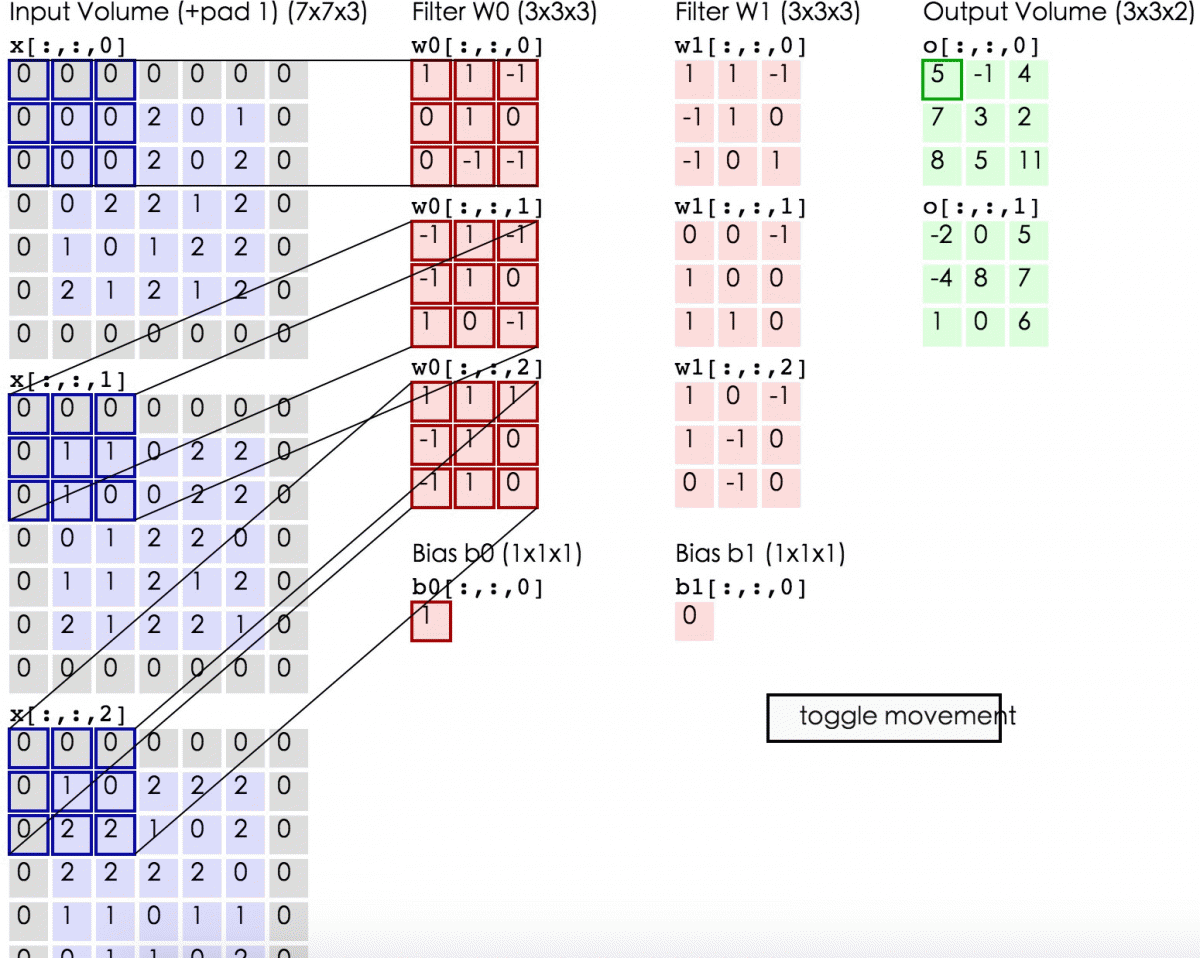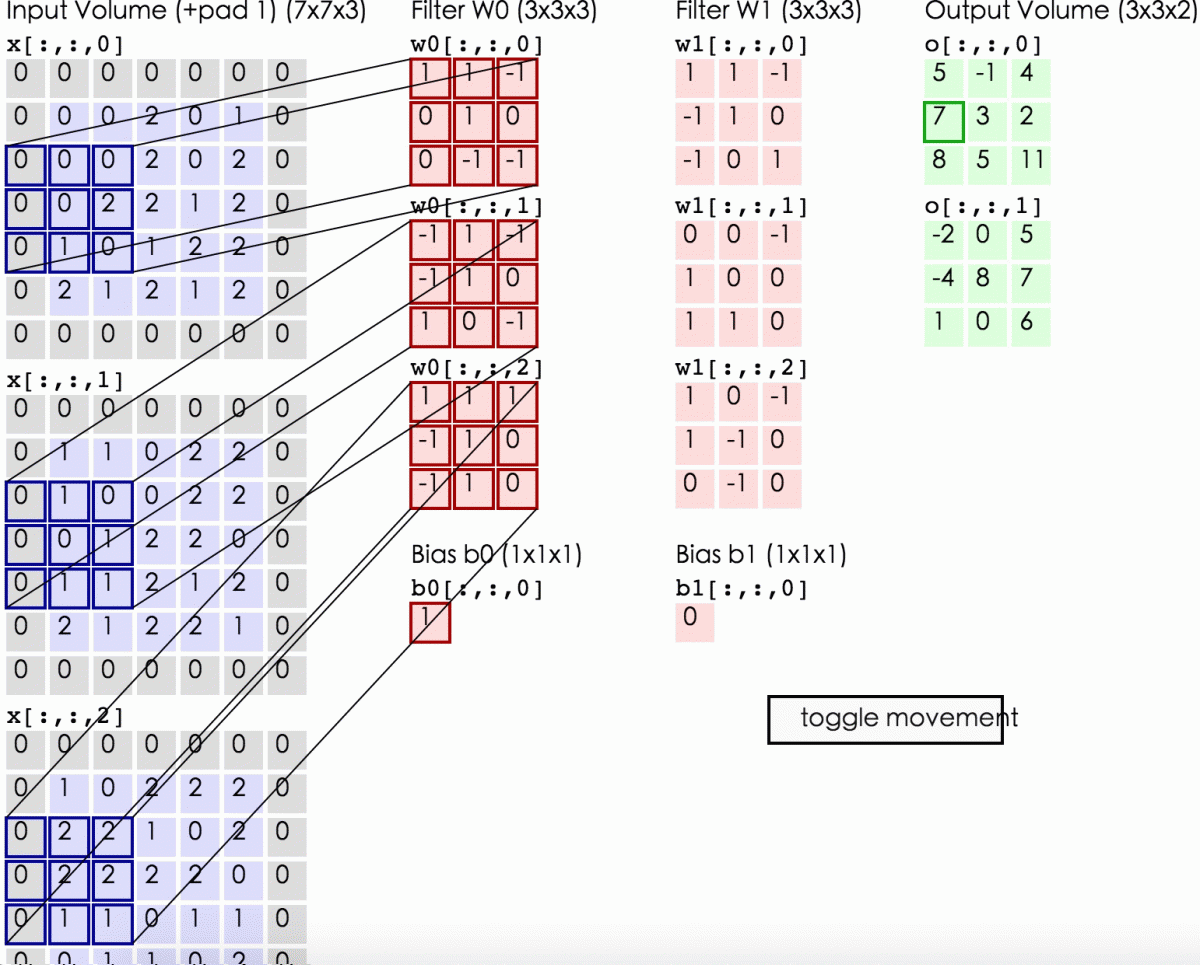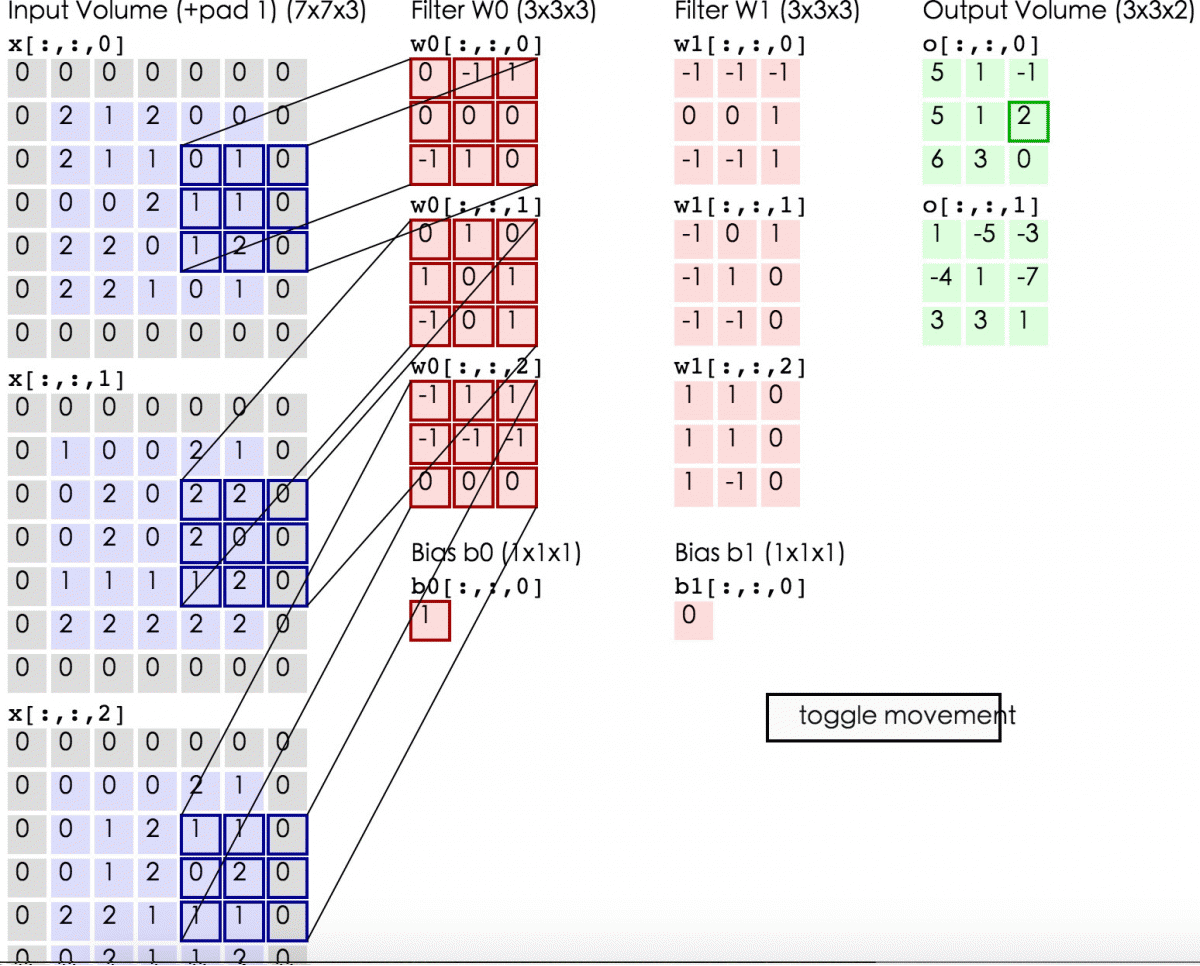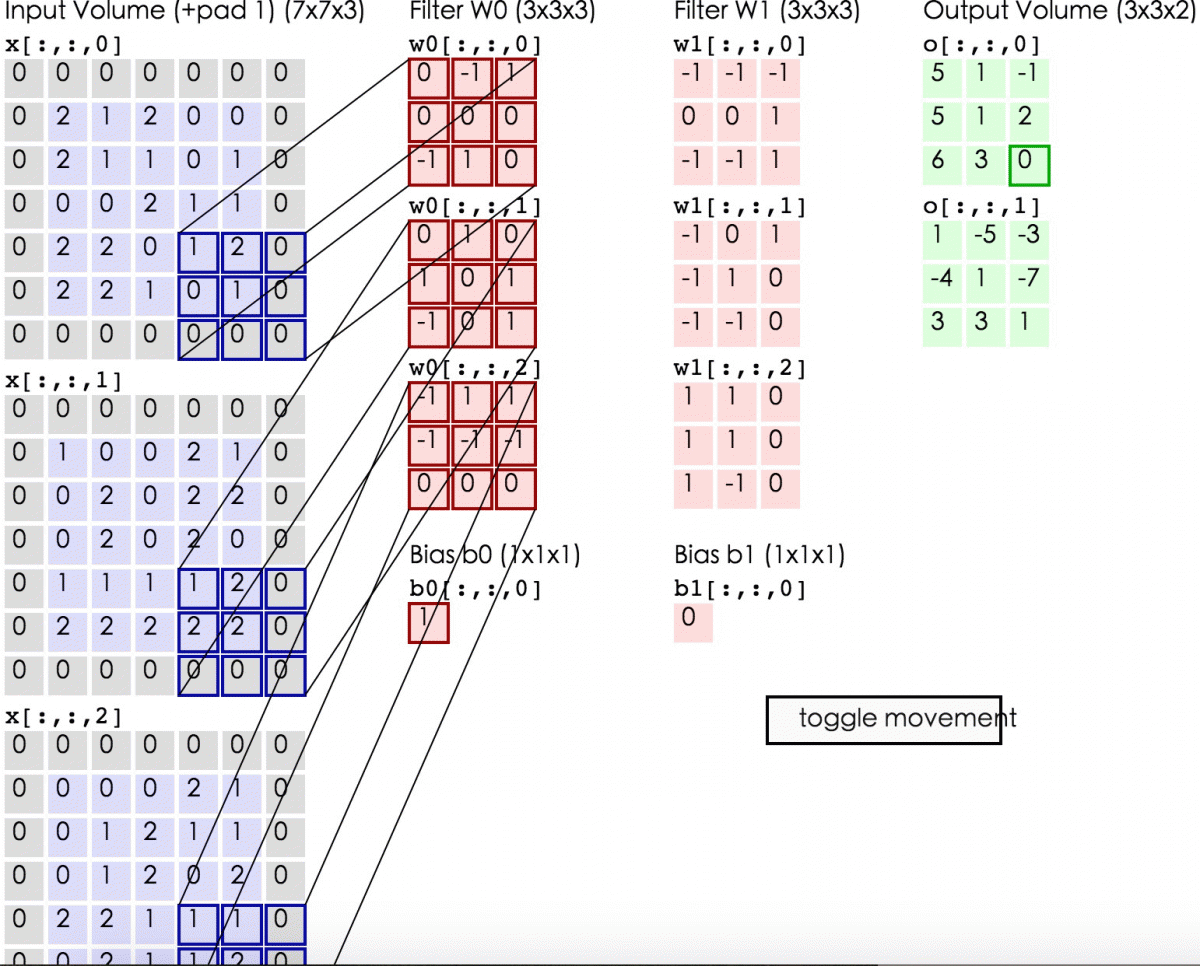
随着左边数据窗口的平移滑动,滤波器Filter w0对不同的局部数据进行卷积计算。
值得一提的是:
- 左边数据在变化,每次滤波器都是针对某一局部的数据窗口进行卷积,这就是所谓的CNN中的局部感知机制。
- 与此同时,数据窗口滑动,但中间滤波器Filter w0的权重(即每个神经元连接数据窗口的的权重)是固定不变的,这个权重不变即所谓的CNN中的参数共享机制。
首先,我们来分解下上述动图,如下图
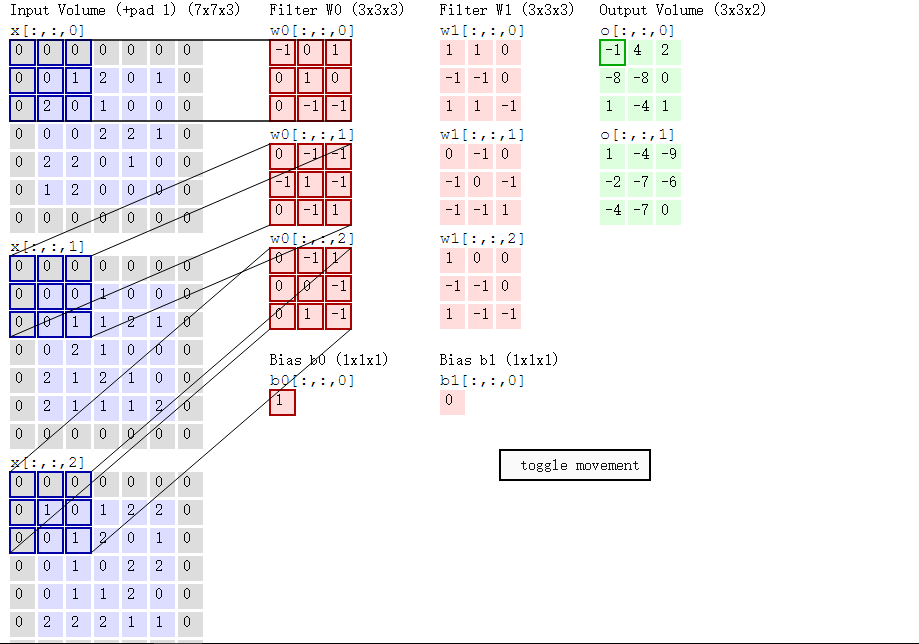
接着,我们细究下上图的具体计算过程。即上图中的输出结果-1具体是怎么计算得到的呢?其实,类似wx + b,w对应滤波器Filter w0,x对应不同的数据窗口,b对应Bias b0,相当于滤波器Filter w0与一个个数据窗口相乘再求和后,最后加上Bias b0得到输出结果-1,如下过程所示:
-1* 0 + 0*0 + 1*0
+
0*0 + 1*0 + 0*1
+
0*0 + -1*2 + -1*0
+
0*0 + -1*0 + -1*0
+
-1*0 + 1*0 + -1*0
+
0*0 + -1*0 + 1*1
+
0*0 + -1*0 + 1*0
+
0*0 + 0*1 + -1*0
+
0*0 + 1*0 + -1*1
+
1
=
-1
然后滤波器Filter w0固定不变,数据窗口向右移动2步,继续做内积计算,得到4的输出结果
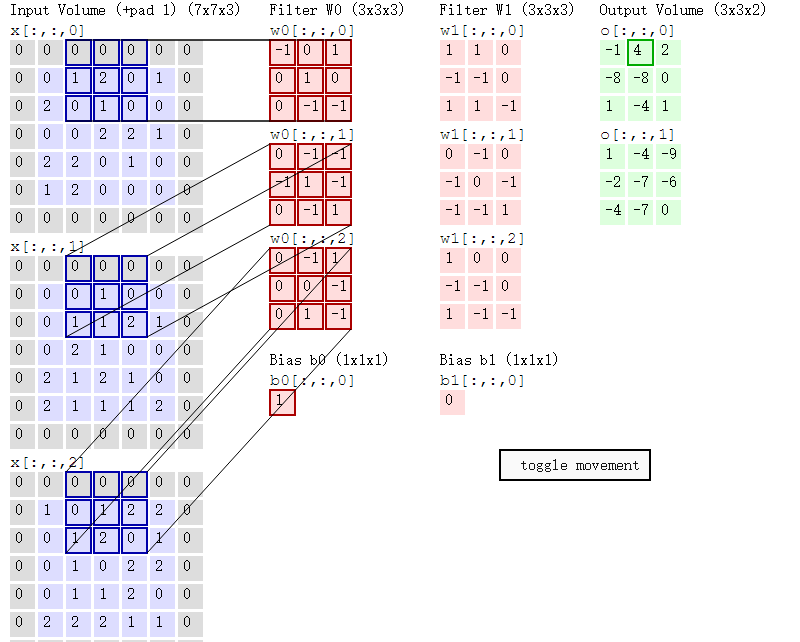
最后,换做另外一个不同的滤波器Filter w1、不同的偏置Bias b1,再跟图中最左边的数据窗口做卷积,可得到另外一个不同的输出。
- 2池化
通过卷积操作获得了图像的特征之后,若直接用该特征去做分类则面临计算量的挑战。例如:对于一个 96X96 像素的图像,假设我们已经学习得到了400个定义在8X8输入上的特征,每一个特征和图像卷积都会得到一个 (96 − 8 + 1) *(96 − 8 + 1) = 7921 维的卷积特征,由于有 400 个特征,所以每个样本都会得到一个7921 * 400 = 3,168,400 维的卷积特征向量。学习一个拥有超过 3 百万特征输入的分类器十分不便,并且容易出现过拟合 (over-fitting)。而Pooling的结果可以使得特征减少,参数减少。
常见的池化方式有如下三种:
1) mean-pooling,即对邻域内特征点只求平均,对背景保留更好;
2) max-pooling,即对邻域内特征点取最大,对纹理提取更好;
3) Stochastic-pooling,介于两者之间,通过对像素点按照数值大小赋予概率,再按照概率进行亚采样;
特征提取的误差主要来自两个方面:(1)邻域大小受限造成的估计值方差增大;(2)卷积层参数误差造成估计均值的偏移。一般来说,mean-pooling能减小第一种误差,更多的保留图像的背景信息,max-pooling能减小第二种误差,更多的保留纹理信息。在平均意义上,与mean-pooling近似,在局部意义上,则服从max-pooling的准则。
下面图中的例子,通过池化,将4*4的矩阵降为了2*2的矩阵。















 9176
9176











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









