







介绍了用户画像的应用场景:
(1)个性化推荐
通过用户标签给用户推荐合适的商品或者内容
(2)营销圈选
根据组合条件(比如说:性别女、年龄25-30、都市白领)圈选出一部分用户,给他们发送push或者短信告知他们最近有什么活动之类的。
(3)策略引擎
根据用户标签命中不同的策略,比如说:高消费人员有奢侈品入口通道
(4)算法模型
(5)画像报告
背景:
今天这篇文章主要分享下用户画像在营销圈选中的应用,后续会继续聊其他几个方向的应用场景。
营销圈选,顾名思义就是根据一些组合条件圈选出合适的人群,比如说:最近要搞女性的美妆促销活动。那应该很容易理解,我选出这方面需求的女性用户,然后通过发送push弹窗或者短信或者邮件等等方式来告诉用户,我们有一个美妆大促活动有什么什么优惠,然后让你来参加。
问题:
但是会出现一些问题,比如说:平台用户总共有10w,但是我根据组合条件筛选(女性用户、都市白领、年龄在25-30岁之间)出来只有5000。如果只是给这5000人发送这个需求显然是没办法达到我的要求。那有没有什么办法呢?
比如说:发现圈选的目标用户5000里面,有很多相似的地方,喜欢美妆对于满减活动也比较敏感,然后平台里面10w 用户也有不少男性用户虽然年龄超过30岁了,但是对于美妆也非常感兴趣(可能是给女朋友买?)
那想到一种办法是不是可以通过这5000用户,去全量用户里面找和这些用户比较相似的一些人呢?通过这5000个用户找到和他们相似的2.5w个用户,加起来3w,给这3w人发送营销活动。
解决方案:
上文中提到的5000个用户称呼为“种子用户”,平台用户10w称之为所有用户(DMP用户),然后我们扩充出来的3w用户称之为“相似用户”或者"扩展用户"
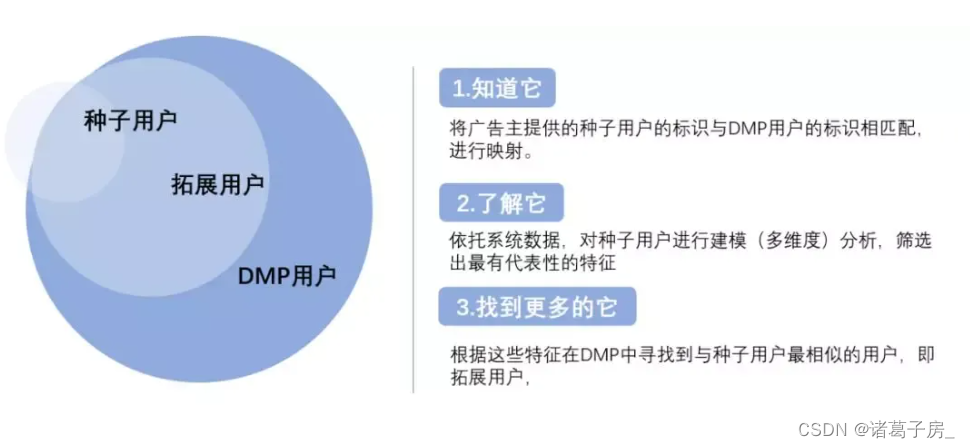
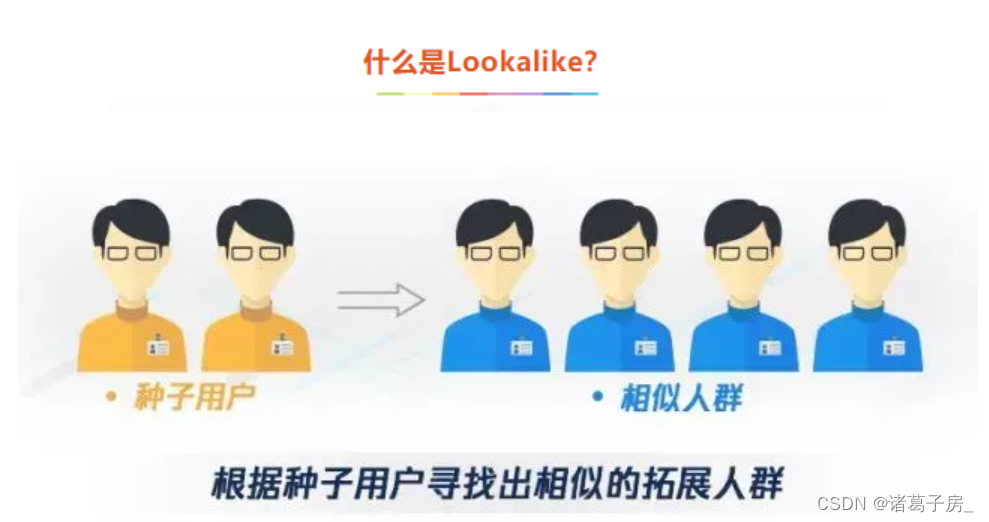
那究竟如何才能根据种子用户找到这部分相似用户呢?
Lookalike整体业务流程如下:
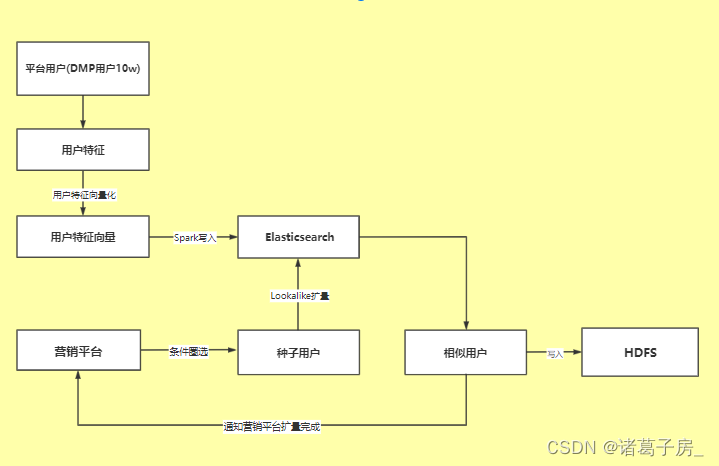
(1)根据平台的全量构建标签,也是用户画像标签的加工(dws_user_info_profile)

(2)根据构建的用户标签进行向量化,可以参考Spark Word2Vec构建向量化(dws_user_info_profile_embe),具体内容可参考:
https://dblab.xmu.edu.cn/blog/1292/

(3)将向量化的用户特征数据写入ElasticSearch,此处考虑用Spark 进行批量写入,提升性能,至此用户量化和入库工作就已经完成了
(4)在营销平台根据圈选条件(比如说:女性、年龄25-30岁、喜欢美妆),最后得到种子用户的id列表
(5)根据种子用户关联用户向量特征得到可以匹配上的用户的向量特征,种子用户id,种子用户向量
(6)根据向量特征去ElasticSearch 里面进行扩量
ElasticSearch 创建索引mapping 主要有两个字段,userId和vector_embedding(dense_vector),其中vector_embedding 为dense_vector类型
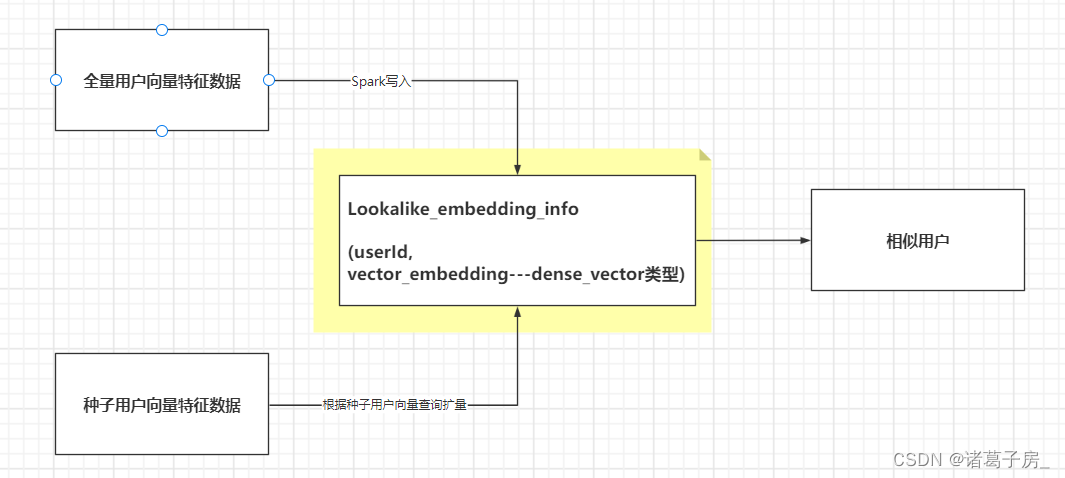
ElasticSearch 向量化使用参考:https://cloud.tencent.com/developer/article/1774216
通过使用ES向量化查询功能完成扩量,具体实现会涉及到扩量查询采用Spark 提升并发性,通过配置扩量倍数参数来获取每一个种子用户的Top N 扩量,最终将扩量后的数据写入HDFS目录同时通知营销平台扩量完成。


















 1062
1062

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











