






知识蒸馏:提取复杂模型有用的先验知识,并与简单模型特征结合算出他们的距离,以此来优化简单模型的参数,让简单模型学习复杂模型的dark knowledge,从而帮助简单模型提高性能。
论文地址:https://arxiv.org/abs/1612.03928
github地址:https://github.com/szagoruyko/attention-transfer
PAYING MORE ATTENTION TO ATTENTION: IMPROVING THE PERFORMANCE OF CONVOLUTIONAL NEURAL NETWORKS VIA ATTENTION TRANSFER
这篇论文主要通过提取复杂模型生成的注意力图来指导简单模型,使简单模型生成的注意力图与复杂模型相似。这样简单模型不仅可以学到特征信息,还能够了解如何提炼特征信息。使得简单模型生成的特征更加灵活,不局限于复杂模型。

图a是输入,b是相应的空间注意力图,它可以表现出网络为了分类所给图片所需要注意的地方。所谓空间注意力图,其实就是将特征图
C
×
H
×
W
C \times H \times W
C×H×W通过映射变换成特征
H
×
W
H\times W
H×W。作者将每层channel平方相加获得特征图对应的注意力图。

上图是人脸识别任务中,对不同维度的特征图进行变换求得的注意力图,可以发现高维注意力图会对整个脸作出反应。

我们发现精度越高的网络对应的注意力图往往可以抓住图片分类的特征。同时选择合适的变换方程对注意力图的获取也至关重要。
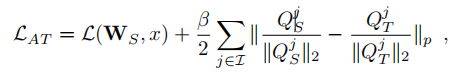
论文中,作者loss分为两部分,第一部分是分类loss就是简单的交叉熵损失函数来实现分类,后一部分是衡量复杂模型于简单模型注意力图差异的距离损失函数。作者着重强调对注意力图进行归一化的重要性,在学生网络的训练中起很大作用。
def at(x):
y = F.normalize(x.pow(2).mean(1).view(x.size(0), -1))
return y
def at_loss(x, y):
return (at(x) - at(y)).pow(2).mean()
作者提供的代码,实现了对注意力图归一化,对差值平方再求平均。
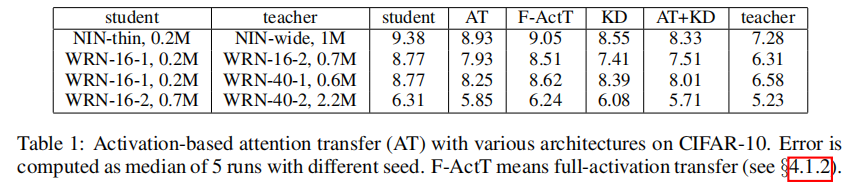
从cifar-10结果可以看出,作者提出的Activation-based attention transfer可以有效的学习复杂模型提取特征的能力,从而提高简单模型的分类精度。

















 2668
2668

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









