







一、手写数字识别介绍
MNIST数字识别是学习神经网络非常好的入门知识。MNIST是由Yann LeCun等创建的手写数字识别数据集,简单易用,通过对该数据集的认识可以很好的对数据进行神经网络建模。本项目以MNIST数据集为例,利用pytorch导入数据,并建立一个简单的图像识别模型。
二、MNIST数据集
1)数据集介绍
MNIST数据集主要是一些手写的数字的图片及对应标签,该数据集的图片共有10类,对应的阿拉伯数字为0-9,如图。

在MNIST数据集介绍的官网(http://yann.lecun.com/exdb/mnist/)中可知,原始的MNIST数据集共包含4个文件。
| 文件名 | 大小 | 用途 |
| train-images-idx3-ubyte.gz | 大约9.45MB | 训练图像数据 |
| train-labels-idx1-ubyte.gz | 大约0.03MB | 训练图像数据的标签 |
| t10k-images-idx3-ubyte.gz | 大约1.57MB | 测试图像数据 |
| t10k-labels-idx1-ubyte.gz | 大约4.5KB | 测试图像的标签 |
在MNIST数据集中有两类图像:一类是训练集,对应着文件train-images-idx3-ubyte.gz和train-labels-idx1-ubyte.gz;另一类是测试集,对应着文件t10k-images-idx3-ubyte.gz和t10k-labels-idx1-ubyte.gz。在数量上,训练集一共有60000张图像,而测试集有10000张图像。我们可以通过自行下载数据集,然后在python中打开并进行处理,也可以利用pytorch中定义好的包进行下载导入并处理。
数据集为什么是gz格式呢?gz是压缩文件格式,应该是为了方便存储和下载,gz文件格式也方便在多种操作系统中进行处理。
解压缩后是idx3-ubyte格式和idx1-ubyte格式,这是什么格式?与图片有什么关系吗?如何转换成平时接触的格式?可以参考这个链接。其实这种格式就是将一堆图片按照顺序组成一个大数组。分析一下代码应该可以理解。
2)数据集导入
在pytorch中,有一个非常重要且好用的包是torchvision,该包主要由3个子包组成,分别是models、datasets和transformers。models定义了许多用来完成图像方面深度学习的任务模型。datasets中包含MNIST、Fake Data、COCO、LSUN、ImageFolder、DatasetFolder、ImageNet、CIFAR等一些常用数据集,并且提供了数据集设置的一些重要参数,可以通过简单数据集设置来进行数据集的调用。transforms用来对数据进行预处理,预处理会加快神经网络的训练,常见的预处理包括从数组转成张量(tensor)、归一化等常见的变化。(为什么要进行归一化?)
归一化的数值中,为什么均值是0.1307,标准差是0.3081呢?因为这是别人做数据集的时候顺便算好的,怎么算呢?我也不知道用那种方法,没验证过,大概就是最大最小标准化法、z—score 标准化、log对数函数归一化等等吧,有兴趣的小伙伴可以去探讨一下,欢迎补充。
本项目导入主要涉及到datasets和transforms,代码如下。
import numpy as np
import torch
from torchvision import datasets, transforms
import matplotlib.pyplot as plt
import torchvision
'''
运行说明
安装依赖命令,要安装这个版本。
pip install torch==1.4.0 torchvision==0.5.0
pip install matplotlib numpy
代码按照内容的顺序,方便阅读。
'''
# 1.1.2 导入数据集
train_loader = torch.utils.data.DataLoader(
datasets.MNIST(root='./data', #root表示数据加载的相对目录
train=True, #train表示是否加载数据库的训练集,False时加载测试集
download=True,#download表示是否自动下载
transform=transforms.Compose([#transform表示对数据进行预处理的操作
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),batch_size=64, shuffle=True)#batch_size表示该批次的数据量 shuffle表示是否洗牌
test_loader = torch.utils.data.DataLoader(
datasets.MNIST('./data', train=False, transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),batch_size=64, shuffle=True)上述代码最外层调用了DataLoder对数据进行封装,而里面设计了datasets和transforms。对于root目录,Pytorch会检测数据是否存在,当数据不存在时,系统会自动将数据下载到data文件夹中。其中的transforms对原数据进行了两个操作,一个是ToTensor,用来把PIL.Image(RGB)或者numpy.ndarry(H*W*C)0~255的值映射到0-1的范围内,并转换成Tensor格式;另一个是Normalize(mean,std),用来实现归一化,不同数据集中图像通道的均值(mean)和标准差(std)这两个数值是不一样的,MNIST数据集的均值是0.1307,标准差是0.3081,这些系数是数据集提供计算好的,有利于加快神经网络的训练。我们随机取一个batch下的数据进行观察,并将其可视化画出来,结果如下所示。
(为什么要转换成ToTensor格式呢?我个人理解是,ToTensor格式包含了batch信息,即一次扔多少张图像进去同时训练的意思,有助于提高训练的效率(欢迎指正)。在PyTorch中,张量Tensor是最基础的运算单位,与NumPy中的NDArray类似,张量表示的是一个多维矩阵。不同的是,PyTorch中的Tensor可以运行在GPU上,而NumPy的NDArray只能运行在CPU上。由于Tensor能在GPU上运行,因此大大加快了运算速度。)
def imshow(img):
img = img / 2 + 0.5 # unnormalize
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
plt.show()
# 得到batch中的数据
dataiter = iter(train_loader)
images, labels = dataiter.__next__()
# 展示图片
imshow(torchvision.utils.make_grid(images))这里需要注意的是,估计有小伙伴这里会报错,大概意思是没有dataiter.next()模块之类的。可能是因为版本问题导致代码不兼容,我这里的代码是已经改过了的,可以在自己环境上顺利运行,如果出现报错,那么将 images,labels = dataiter.__next__()改成 images,labels = dataiter.next()
三、构建模型
上一小节中,介绍了MNIST数据集,并掌握了认识ipytorch中导入该数据集,本节继续以pytorch为工具,搭建一个图像识别网络。一个典型的神经网络训练过程包括定义神经网络、前向传播、计算损失、反向传播、更新参数。
1)定义神经网络
在pytorch中,torch.nn是专门为神经网络设计的模块化接口,nn库构建于autograd(在Pytorch中为Tensor所有操作提供自动微分)之上,可以用来定义和运行神经网络。nn.Module是nn库中十分重要的类,包含网络各层的定义以及forward函数。pytorch允许定义自己的神经网络,但需要继承nn.Modue类,并实现forward函数。只要在nn.Moduel的子类中定义forward函数,backward函数就会被自动实现(利用autograd),一般把神经网络中具有科学系参数的层放在构造函数__init__中,而不具有可学习参数的层(如Relu),可放在构造函数中,也可不放在构造函数中。下面的代码就是大概的框架。
import torch.nn as nn # 导入nn库的常见做法
class NetName(nn.Module):
def __init__(self):
super(NetName,self).__init__()
nn.module1 = ...
nn.module2 = ...
nn.module3 = ...
def forward(self,x):
x = self.module1(x)
x = self.module2(x)
x = self.module3(x)
return x本小节对MNIST数据集,我们构建一个简单的图像识别网络,该网络结构如图。

这是一个简单的前馈神经网络,其中Convolutions是卷积操作,Subsampling是下采样操作,也就是池化,Full connetion表示全连接层,Gaussian Connections时进行了欧式径向基函数(Euclidean Radial Basis Funciton)运算并输出最终结果。它将输入的图片,经过两层卷积和池化,再经过三层全连接,最后输出我们想要的概率值。代码如下:
import torch
import torch.nn as nn
import torch.nn.functional as F#可以调用一些常见的函数,例如非线性以及池化等
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
# 1 input image channel, 6 output channels, 5x5 square convolution
# 输入图片是1 channel输出是6 channel 利用5x5的核大小
self.conv1 = nn.Conv2d(1, 6, 5)
self.conv2 = nn.Conv2d(6, 16, 5)
# 全连接 从16 * 4 * 4的维度转成120
self.fc1 = nn.Linear(16 * 4 * 4, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
# 在(2, 2)的窗口上进行池化
x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2))
x = F.max_pool2d(F.relu(self.conv2(x)), 2)#(2,2)也可以直接写成数字2
x = x.view(-1, self.num_flat_features(x))#将维度转成以batch为第一维 剩余维数相乘为第二维
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
def num_flat_features(self, x):
size = x.size()[1:] # 第一个维度batch不考虑
num_features = 1
for s in size:
num_features *= s
return num_features
net = Net()
print(net)首先把该网络取名为Net,在继承nn.Module类,在初始化函数中定义了卷积和全连接。卷积利用的函数时nn.Conv2d,它接收三个参数,即输入通道、输出通道和核大小。由于MNIST是黑白数据集,所以只有一个颜色通道,如果是其他彩色数据集,则有RGB三个通道。所以最开始的输入为1,核大小定义为5,输出定义为6,代表6个特征。(输入通道个数等于卷积核通道个数;卷积核个数 等于 输出通道个数)(卷积运算如何获得多个特征的?)(其实卷积核的权重也是需要学习和更新的)
全连接层又叫Full-connetcted Layer或者Dense Layer,在pytorch中通过nn.Linear函数来实现,是一个常用来做维度转换的层,接收两个参数,即输入维度和输出维度。初始化卷积和全连接后,我们在forward函数中定义前向传播,当输入变量x时,F.max_pool2d(F.relu(self.conv1(x)),(2,2))先输入第一层卷积,为了增加非线性表征,在卷积后加入一层ReLU层,再调用F中的max_pool2d函数定义窗口大小为(2,2)进行池化,得到新的x。依次类推,将x输入接下来的网络结构中。
2)前向传播
定义完一个网络结构后,后期我们会将所有数据按照batch的方式进行输入(batch可以理解为批次,后面可能会涉及到batch_size这个概念就是一次同时训练多少张图片,太大不行因为显存不够用,太小也不好因为效率太慢,而且梯度变化很大,网络难以收敛),得出对应的网络输出,这也就是所谓的前向传播。
# 前向传播
image = images[:2]
label = labels[:2]
print(image.size())
print(label)
out = net(image)
print(out)3)计算损失
损失函数需要一对输入:模型输出和目标,用来评估输出距离目标有多远。损失用loss来表示,损失函数的作用就是计算神经网络每次迭代的前向计算结果与真实值之间的差距,从而指导模型下一步训练往正确的方向进行。常见的损失函数有交叉熵损失函数和均方误差损失函数。
在pytorch中,nn库模块提供了多种损失函数,常用的有以下几种:处理回归问题的nn.MSELoss函数,处理二分类的nn.BCELoss函数,处理多分类的nn.CrossEntropyLoss函数,由于本次MNIST数据集是10个分类,因此选择nn.CrossEntropyLoss函数。(交叉熵损失函数是什么?如何计算损失值的?)
# 计算损失
image = images[:2]
label = labels[:2]
out = net(image)
criterion = nn.CrossEntropyLoss()
loss = criterion(out, label)
print(loss)输出为tensor(2.2725,grad_fn=<NIILossBackward>),表明当前两个样本通过网络输出后于实际差距仍有2.2725,我们训练的目标是最小化loss值。
4)反向传播与更新参数
(这部分主要讲的是实现过程,如果是原理部分可以看西瓜书和李航老师的统计学习方法,里面有详细的推导和分析,这里没像前面那样子补充一些原理性的资料,因为这一块内容比较庞大,我自己也没明白,所以如果有不明白可以查阅其他资料补充和学习)
当计算出一次前向传播的loss值之后,可进行反向传播计算梯度,以此来更新参数。在pytorch中,对loss调用backward函数即可。backward函数属于torch.autograd函数库,在深度学习过程中进行反向传播,计算输出变量关于输入变量的梯度。最后要做的事情就是更新神经网络的参数,最简单的规则就是随机梯度下降,公式如下:
当然,还有很多不同的更新规则,类似于SGD、Nesterov-SGD、Adam、RMSProp等,为了让这些可行,pytorch建立了一个torch.optim包,调用它可以实现上述任意一种优化器。
# 创建优化器
import torch.optim as optim
optimizer = optim.SGD(net.parameters(),lr = 0.01) # lr 表示学习率
criterion = nn.CrossEntropyLoss()
# 在训练过程中
image = images[:2]
label = labels[:2]
optimizer.zero_grad() # 消除梯度
out = net(image)
loss = criterion(out,label)
loss.backward()
optimizer.step() # 更新梯度在训练开始前,先定义好优化器optim.SGD和损失函数nn.CrossEntropyLoss,当开始迭代进行训练时,将数据进行输入,得到的输出用来和实际标签计算loss,对loss进行反向传播,最后通过优化器更新参数。其中需要对优化器进行消除梯度,因为在使用backward函数时,梯度是被累积而不是被替换掉,但是在训练每个batch(指一批数据)时不需要将两个batch的梯度混合起来累积,所以这里需要对每个batch设置一边zero_grad。
四、开始训练
为了方便后续使用模型,可以将训练过程携程一个函数,向该函数传入网络模型、损失函数、优化器等必要对象后,在MNIST数据集上进行训练并打印日志观察过程,代码如下:
# 开始训练
def train(epoch):
for run_time in range(1,epoch+1):
net.train() # 设置为training模式
running_loss = 0.0
for i, data in enumerate(train_loader):
# 得到输入 和 标签
inputs, labels = data
# 消除梯度
optimizer.zero_grad()
# 前向传播 计算损失 后向传播 更新参数
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# 打印日志
running_loss += loss.item()
if i % 100 == 0: # 每100个batch打印一次
print('[%d, %5d] loss: %.3f' %
(run_time, i + 1, running_loss / 100))
running_loss = 0.0
train(10)
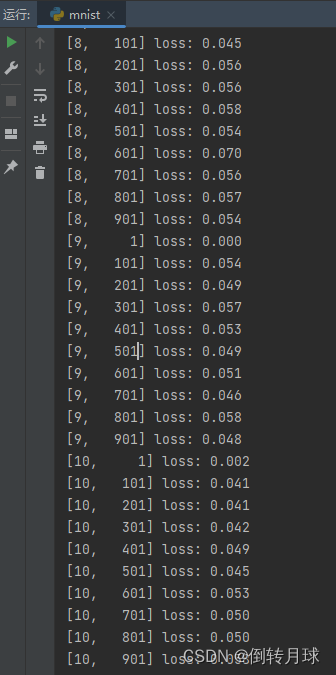
torch.save(net.state_dict(),"Linear.pth")调用train(10)训练10轮的结果如下,可以看出loss值不断下降。其中,10表示训练10轮完整的数据集(每轮60000张图片)。 其实到了后面损失值已经保持比较低的水平了,当然还是会有一点小波动,整体上是呈现减小的趋势。

五、观察模型预测结果
在训练完成以后,为了检验模型的训练结果,可以在测试集上进行验证,通过不同的评估方法来评估。一个分类模型,常见的评估方法是求分类准确率,它能衡量所有类别中预测正确的个数占所有样本的比值,直观且简单。
# 观察模型预测效果
correct = 0
total = 0
with torch.no_grad():#或者model.eval()
for data in test_loader:
images, labels = data
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the 10000 test images: %d %%' % (100 * correct / total))训练时用的是train_loader数据集,测试时就得用另一部分的数据集test_loader。代码中用到with torch.no_grad(),是为了让模型不进行梯度求导,和model.eval()具有相同的作用。eval即evaluation模式,train即训练模式(可以看到开始训练时的代码——model.train()),这两种模式仅仅当模型中有Dropout和BatchNorm时才会有影响。因为训练时Dropout和BatchNorm都会开启,而一般而言,测试时Dropout会被关闭,BatchNorm中的参数也是利用训练时保留的参数,所以测试时应进入评估模式。通过数据输入神经网络,得到神经网络的概率输出后,我们需要取最大值对应的索引,这里用到了torch.max函数。该函数接收两个输入,一个是数据,另一个是表示要在哪一维度操作,很明显这里输入的是概率值及第二维的1.返回两个输出,即最大的数值及最大值对应的索引。在这里我们并不关心数值多少,所以对该变量用“_”命名,这是常见的对无关变量命名的方式。将预测索引和实际索引进行对比,即可得到准确率。
![]()
这是在所有类别上进行评估,并无法侧重看出哪个类别预测的好坏,如果想观察每个类别的预测结果,可以使用如下代码。
# 语法解释:https://juejin.cn/s/list%280.%20for%20i%20in%20range%2810%29%29
class_correct = list(0. for i in range(10))
class_total = list(0. for i in range(10))
classes = [i for i in range(10)]
with torch.no_grad():
for data in test_loader:
images, labels = data
outputs = net(images)
_, predicted = torch.max(outputs, 1)
c = (predicted == labels).squeeze() # squeeze()用来压缩为1的维度
for i in range(len(labels)): # 对所有labels逐个进行判断
label = labels[i]
class_corret[label] += c[i].item()
class_total[label] += 1
for i in range(10):
print('Accuracy of %5s : %2d %%' % (classes[i], 100 * class_correct[i] / class_total[i]))六、使用已训练好的模型
网络模型的加载有两种:①加载参数;②加载整个模型(包括网络模型和已训练好的参数权重),两种方法在载入模型时都需要有预设的网络结构,例如下边代码,否则会提示找不到相应的module。
import matplotlib.pyplot as plt
import torch
from torch import nn
from PIL import Image
import cv2
import torch.nn.functional as F #可以调用一些常见的函数,例如非线性以及池化等
import matplotlib.pyplot as plt
import numpy as np
from torch.autograd import Variable
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
# 1 input image channel, 6 output channels, 5x5 square convolution
# 输入图片是1 channel输出是6 channel 利用5x5的核大小
self.conv1 = nn.Conv2d(1, 6, 5)
self.conv2 = nn.Conv2d(6, 16, 5)
# 全连接 从16 * 4 * 4的维度转成120
self.fc1 = nn.Linear(16 * 4 * 4, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
# 在(2, 2)的窗口上进行池化
x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2))
x = F.max_pool2d(F.relu(self.conv2(x)), 2)#(2,2)也可以直接写成数字2
x = x.view(-1, self.num_flat_features(x))#将维度转成以batch为第一维 剩余维数相乘为第二维
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
def num_flat_features(self, x):
size = x.size()[1:] # 第一个维度batch不考虑
num_features = 1
for s in size:
num_features *= s
return num_features
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = torch.load('Linear.pth')
print(model)
img = cv2.imread('2.png',0)
img = cv2.resize(img,(28,28))
height,width=img.shape
dst=np.zeros((height,width),np.uint8)
for i in range(height):
for j in range(width):
dst[i,j]=255-img[i,j]
img = dst
img=np.array(img).astype(np.float32)
img=np.expand_dims(img,0)
img=np.expand_dims(img,0)#扩展后,为[1,1,28,28]
img=torch.from_numpy(img)
img = img.to(device)
output=model(Variable(img))
prob = F.softmax(output, dim=1)
prob = Variable(prob)
prob = prob.cpu().numpy() #用GPU的数据训练的模型保存的参数都是gpu形式的,要显示则先要转回cpu,再转回numpy模式
print(prob) #prob是10个分类的概率
pred = np.argmax(prob) #选出概率最大的一个
print(pred.item())
七、总结
本文首先介绍MNIST数据集,以及利用Pytorch导入该数据集,接着通过搭建神经网络的步骤(定义神经网络、前向传播、计算损失、反向传播、更新参数)构建出一个简单的图像卷积网络,最后对数据集进行训练并观察预测结果。
八、文件列表

【参考资料】
《Pytorch教程21个项目玩转Pytorch实战》
感谢本文中超链接的作者!















 1456
1456











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









