






关注一下~,更多商业数据分析案例等你来撩
只要输入基金代码即可获取其历年基金净值的爬虫程序与数据分析源代码都已准备好,公众号 “ 数据分析与商业实践 ” 后台回复 ” 基金爬虫 “ 即可获取 ~~
前言
理财就是理生活,如果理财的过程中还能结合自己所学的技术,岂不美哉?
"投资 80% 看行为,20% 看技术;风险在人声鼎沸处,机会在无人问津时。" 这是股神老巴的一句名言。的确,只有持有得久,坐得住,能够坚持定期不定额的投资,摒弃喜涨厌跌的心理,才能看到赚钱的曙光。

本文灵感来源于笔者的一位极具慧眼的投资老哥,在投资的股票中,会使用i问财和同花顺等分析网站 确认入市时机,筛选出好的公司,同时剔除周期股,剔除基本面转坏的股票,并且也能分析公司的财报是否存在收入美化,资产美化,资金现金流是否异常等。后来才知道这只是基本操作,TA 还懂得个股分析与行业分析,各种高大上的模型与指标配合接地气的操作,再辅以超于常人的投资心态,令TA在近10年的股票投资中佳报频传。
没想到我这个不到两年经验的投资小白也有能跟 TA 搭上话的一天。" 帮我写个爬虫呗,我想只要我输入指定的基金代码,就能够获取该基金历年的净值信息,接着还能够自动按年分组并求出每年 25%,50%,75% 对应的净值分位点,把程序打包发给我。当然,如果能够写个 JAVA 小程序或者嵌入桌面提醒就更好了,这样我就不用一两周看一次了,半年高枕无忧,反正基金只是闹着玩,我只按照净值来,不管什么它的主要重仓" 大佬在电话里淡淡的说...
[图片上传失败...(image-8f8bfc-1596024379263)]
爬虫构建
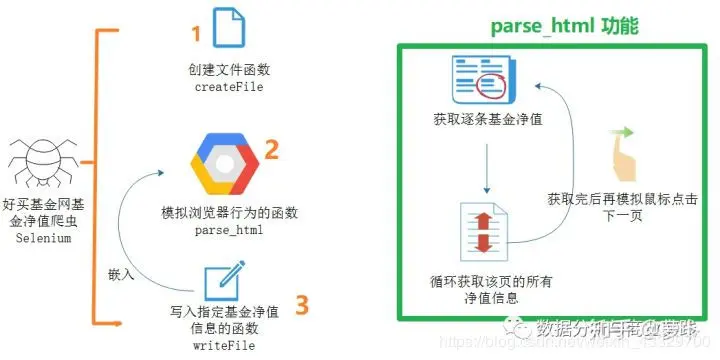
这就是强者的世界吗?既然大佬都发话了,那小弟只能竭尽全力了。上段话的蓝字为主要需求,至于后期的小程序开发或桌面提醒功能都先不谈,本文着重于爬虫的设计很简单的净值分析,下图为爬虫的设计思路,展示了用到的函数和大概步骤,数字代表运行顺序,写入文件的函数嵌在模拟浏览器行为的函数中:
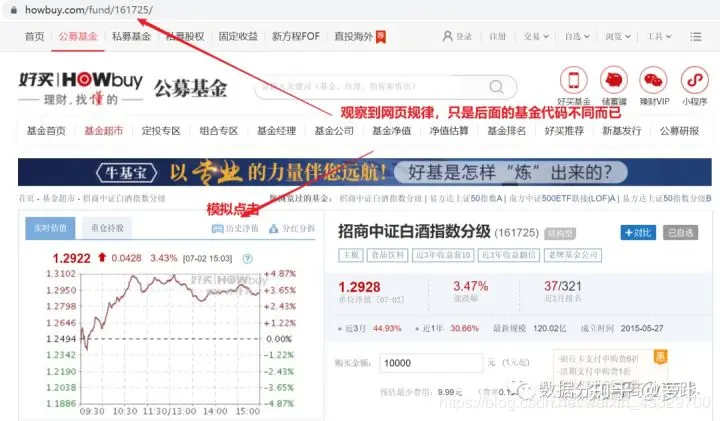
以近几天涨势正猛的招商中证白酒指数分级为例:
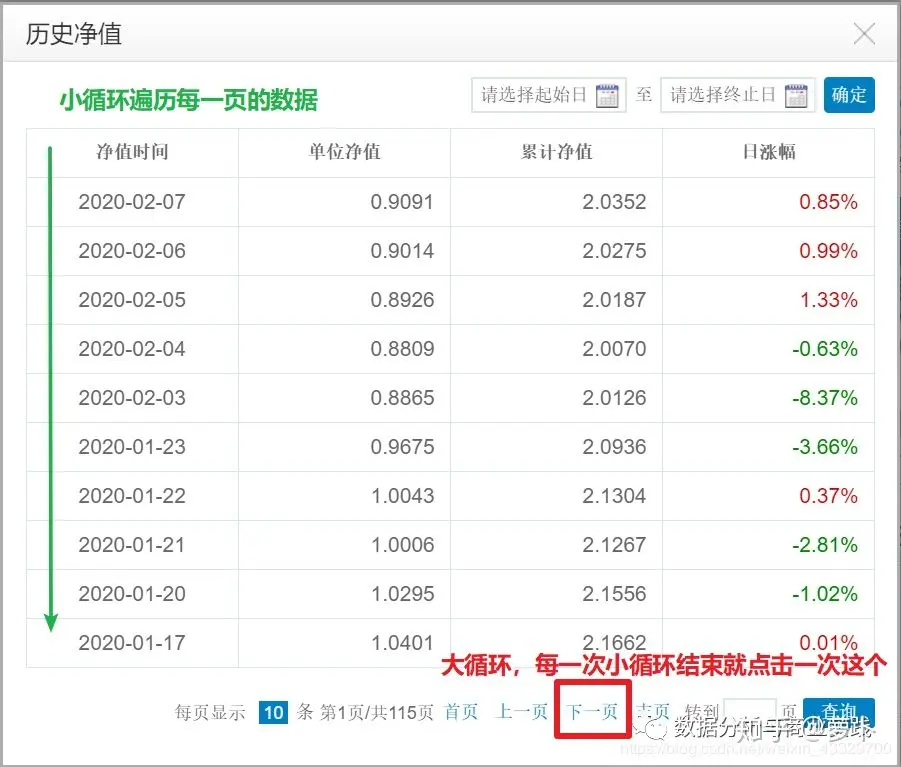
小循环的设置比较简单,毕竟每页的数据量固定,都是10条,但不同基金的页数不同,所以我们只需要提前捕捉到 ” 共xxx页 “ 的 xxx ,然后将其设置结束大循环的终点标志即可。爬虫代码只有 120 行左右(包含了非常非常详细的注释),因篇幅原因不便展示,后台回复关键字领取,7.4更新,本文底部即可获取。
Pandas 分析

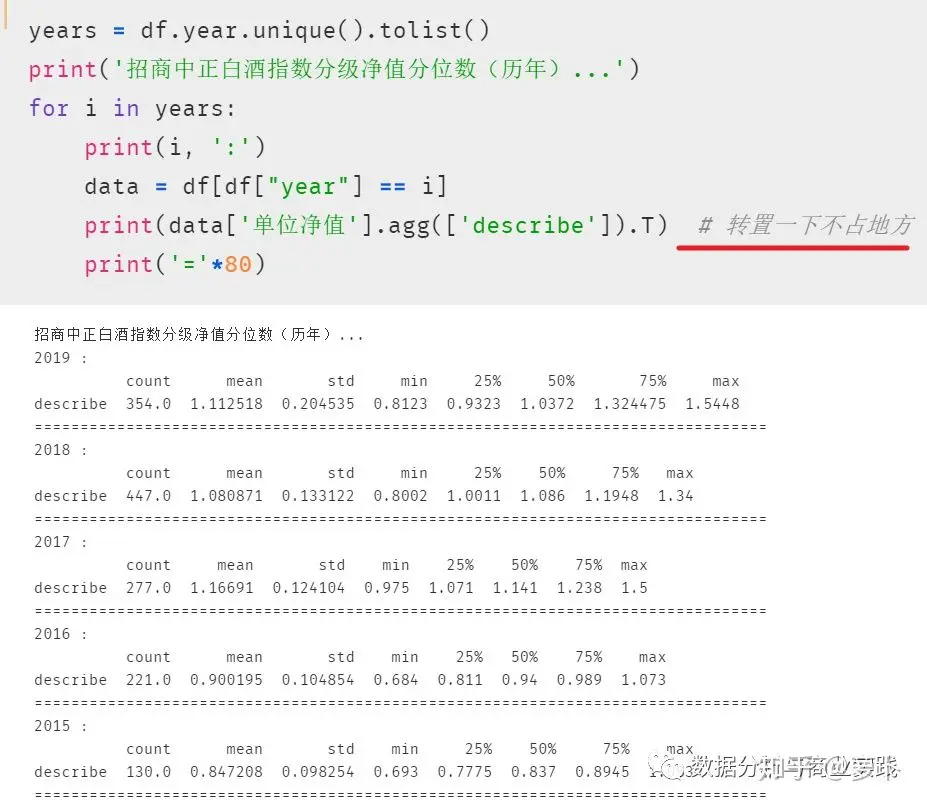
简单分析一下 2015~2019 结果(仅针对基金净值而言):
- 50%分位点并不是逐年上升,而是在17年达到最大值,而后开始下降
- 75%分位点与最大值都是在17年达到一个较大值后,在下一年稍有回落,从去年开始又呈现上升趋势。
- ...
至于数据可视化部分就留给大家自行探索了。
注:相关数据源和超详细的代码(python,Jupyter Notebook 版本 + 详细注释)已经整理好,在 “数据分析与商业实践” 公众号后台回复 “ 基金爬虫 ” 即可获取。
[图片上传失败...(image-c0b64f-1596024379263)]不到70行Python代码,轻松玩转决策树预测客户违约模型(附案例数据与代码)
后续会不断更新常见场景下的 Python 实践
更新
还是直接上代码吧,不过要下载一个浏览器驱动,全套代码,操作和演示视频在公众号后台~~
from selenium import webdriver # 浏览器驱动
from selenium.webdriver.common.keys import Keys # 模拟浏览器点击时需要用
import time,csv
import random
fieldnames = ['日期', '单位净值', '累计净值', '日涨幅'] # 待获取的目标字段
# 根据用户命名来创建的 csv 文件
def createFile(file_name):
# 写入文件的域名
# 创建文件进行存储
with open(file_name + '.csv', 'w', encoding='utf-8') as f:
writer = csv.DictWriter(f, fieldnames=fieldnames)
# 将数据写入文件的函数
def writeFile(data, file_name):
""" data: 传入写入的数据; file_name:可根据基金名称自定义 """
# 对刚才创建的文件进行“追加写”
with open(file_name + '.csv', 'a', encoding='utf-8') as f:
writer = csv.DictWriter(f, fieldnames=fieldnames)
writer.writerow(data)
def parse_data(client_input, file_name):
"""
传入完整的基金代码,返回数据,供写入文件的函数写入
:param client_input: 用户输入的完整基金代码
file_name: 用户自定义的生成文件的名字
:return: 基金净值数据
"""
# ------------------------ 基础配置 ------------------------
# 设置不加载图片,提速
chrome_opt = webdriver.ChromeOptions() # 告知 webdriver:即将需要添加参数
# 需要添加的参数们
prefs = {"profile.managed_default_content_settings.images": 2}
chrome_opt.add_experimental_option("prefs", prefs)
# 初始化浏览器,即运行该行代码将会打开浏览器
driver = webdriver.Chrome(chrome_options=chrome_opt)
# 找寻规律后发现的指定代码后的基金网址
basic_url = 'https://www.howbuy.com/fund/'
full_url = f'{basic_url + client_input}' # 全网址等于基本构造 + 人为输入的基金代码
print(f'即将模拟浏览器打开如下基金网页:{full_url}')
# --------------- 开始模拟浏览器打开指定基金网页并点击历史净值 ----------------
driver.get(full_url)
# 模拟点击历史净值
driver.find_element_by_id('open_history_data').send_keys(Keys.ENTER)
time.sleep(1.5) # 设置缓冲时间
# ------------------------- 激动人心的模拟爬取 ------------------------
## 获取需要爬取的总页数
page_info = driver.find_element_by_xpath('//*[@id="fHuobiData"]/div').text
print(page_info)
## 包含最大页码的内容格式模板如下
"""
第1页/共115页
"""
## 由上可知,需要替换掉空格,换行符,  以及 第1页/共 和 页,这几样东西
## 当然,也可以用正则表达式来操作,这样快很多,不用写那么多 replace
import re
total_pages = re.findall('共(\d+)页', page_info, re.S)[0] # re.S 消除换行符的影响
print(f'该基金共 {total_pages} 页') # 检查一下
print('='*55)
print('开始爬取...')
# 爬取历史净值信息,并模拟翻页
try:
for i in range(1, int(total_pages)+1):
print(f'正在爬取第 {i} 页')
try:
for j in range(2, 11): # 每一页共 10 条信息:2~11
# 日期
date_xpath = '//*[@id="fHuobiData"]/table/tbody/tr[{}]/td[1]'
date = driver.find_element_by_xpath(date_xpath.format(j)).text
# 单位净值
net_value_xpath = '//*[@id="fHuobiData"]/table/tbody/tr[{}]/td[2]'
net_value = driver.find_element_by_xpath(net_value_xpath.format(j)).text
# 累计净值
total_net_value_xpath = '//*[@id="fHuobiData"]/table/tbody/tr[{}]/td[3]'
total_net_value = driver.find_element_by_xpath(total_net_value_xpath.format(j)).text
# 日涨幅
daily_increase_xpath = '//*[@id="fHuobiData"]/table/tbody/tr[{}]/td[4]/span'
daily_increase = driver.find_element_by_xpath(daily_increase_xpath.format(j)).text
print(date, net_value, total_net_value, daily_increase)
## ---------------- 将爬取到的数据写入 csv 文件 ---------------------
data = {
'日期': date,
'单位净值': net_value,
'累计净值': total_net_value,
'日涨幅': daily_increase
}
# 写入数据
writeFile(data, file_name=file_name)
# 模拟点击下一页: 在大循环处模拟
driver.find_element_by_xpath('//*[@id="fHuobiData"]/div/a[3]').send_keys(Keys.ENTER)
time.sleep(random.random()*2)
except Exception as e:
print(e.args)
continue
print('\n')
except Exception as e:
print(e.args) # 为分享方便,只是设置最简单的捕获异常,日后再说
# 调度爬虫的总函数
def main():
client_input = input("请输入完整基金代码:")
file_name = input("请输入你希望创建的文件名(无需添加引号或后缀),如 我的基金:")
createFile(file_name=file_name)
print('='*50)
parse_data(client_input, file_name=file_name)
# 主程序接口
if __name__ == '__main__':
main()
















 2048
2048

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









