







算法原理
1、KNN原理
KNN(K-Nearest Neighbor)在输入没有标签的数据后,将新数据中的每个特征与样本集中数据对应的特征进行比较,提取出样本集中特征最相似数据(最近邻)的分类标签。一般来说,我们只选择样本数据集中前k个最相似的数据,通常k是不大于20的整数。最后选择k个最相似数据中出现次数最多的分类作为新数据的分类。
2、朴素贝叶斯原理
朴素贝叶斯分类器是一个基于贝叶斯定理的比较简单的概率分类器,其中 naive(朴素)是指的对于模型中各个 feature(特征) 有强独立性的假设,并未将 feature 间的相关性纳入考虑中。其中朴素贝叶斯分类器中最核心的便是贝叶斯准则,用如下的公式表示:
p(c|x)= \frac{p(x|c)p(c )}{p(x)}p(c∣x)=p(x)p(x∣c)p(c )
实验内容
1、利用KNN对鸢尾花数据进行分类
2、训练并评价模型
3、使用上述模型在测试集上进行预测
# knn分类器
knn = neighbors.KNeighborsClassifier()
#调用数据集
iris = datasets.load_iris()
#划分数据
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.25, random_state=33)
# print(X_train)
# print("***********")
print("训练集的个数为",len(y_train))
#使用fit建立模型进行训练
knn.fit(X_train,y_train)
y_predict=knn.predict(X_test)
print("预测值为:",y_predict)
print("the accuracy of KNN Classifier is: ",knn.score(X_test,y_test))
#打印字典型分类报告
print(classification_report(y_test, y_predict, target_names = iris.target_names))
 实验结果分析:
实验结果分析:
首先通过sklearn库加载数据集iris,将数据集随机按3:1划分为训练集和测试集,我们可统计训练集记录占112条,从库sklearn中创建KNN分类器模型,将训练集数据传入训练模型,最后拿测试集数据去评估模型。由评估结果可以得出测试记录38条,所创建的KNN分类器的准确率为0.95,召回率为0.96,F1值为0.95。
4、利用Navie Bayes对鸢尾花数据建立分类模型
5、使用上述模型在测试集上进行预测;
6、评估上述模型
from sklearn.naive_bayes import GaussianNB,BernoulliNB
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris
from sklearn.metrics import classification_report
#读取数据
iris = load_iris()
#划分数据
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.25, random_state=33)
#创建模型
classifier=GaussianNB()
# classifier=BernoulliNB()
#开始训练
classifier.fit(x_train,y_train.ravel())
# print(y_train.ravel())
#计算GaussianNB分类器的准确率
print("***训练集***")
print("GaussianNB-输出训练集的准确率为:",classifier.score(x_train,y_train))
y_train_predict=classifier.predict(x_train)
print(classification_report(y_train, y_train_predict, target_names = iris.target_names))
print("***测试集***")
print("GaussianNB-输出测试集的准确率为:",classifier.score(x_test,y_test))
y_test_predict=classifier.predict(x_test)
print(classification_report(y_test, y_test_predict, target_names = iris.target_names))
 实验结果分析:
实验结果分析:
同使用KNN训练模型的大致思路一样,先将数据集划分为训练集和测试集,再创建模型GaussianNB(),将训练数据传入模型对模型进行训练,最后用所建模型进行预测,在这里分别对训练集和测试集进行预测,有结果可看出所建朴素贝叶斯模型对训练数据预测的准确率为0.96,对测试集预测的准确率为0.95,由于测试集和训练集的准确率都较高,故模型可用。
7、不使用sklearn中的分类方法,自己编写KNN程序(建议用python语言),并对鸢尾花数据进行分类
import random
from sklearn.datasets import load_iris
#加载数据集
iris_dataset = load_iris()
def test(a, b, data, label):
listmin = [] # 保存各个测试数据与样本数据的最小距离
list1 = [] # 保存所有近邻距离
list2 = [] # 保存listmin用来排序查找
listknn = [] # 保存n近邻的n各最短距离
num = [] # 保存最短距离下标
result1 = 0
result2 = 0
result3 = 0
# 计算最短距离度量,并保存在数组中
for j in range(len(data)):
list1 = []
for i in range(1, b + 1):
c = abs(a[0] - data[j][0]) ** i + abs(a[1] - data[j][1]) ** i + abs(a[2] - data[j][2]) ** i + abs(
a[3] - data[j][3]) ** i
d = round((pow(c, 1 / i)), 3) # 保留三位小数
list1.append(d)
listmin.append(min(list1))
list2.extend(listmin) # 创建一个新的数组用来运算
list2.sort()
# 找寻数组中与目标点距离最短的n个点,进行记录,并且进行预测
for i in range(b):
for j in range(len(listmin)):
if list2[i] == listmin[j]:
listknn.append(list2[i])
num.append(listmin.index(listmin[j]))
if (label[listmin.index(listmin[j])] == 0):
result1 += 1
elif (label[listmin.index(listmin[j])] == 1):
result2 += 1
else:
result3 += 1
if (result1 > result2 and result1 > result3):
n = 0
elif (result2 > result1 and result2 > result3):
n = 1
else:
n = 2
print("目标点为:{},\n当模型设为{}近邻时,\n与目标点最近的点是{},\n距离为:{},\n预测标签为:{}\n"
.format(a, b, (list(data[num[i]] for i in range(len(num)))),listknn, n))
data = iris_dataset['data']
label = iris_dataset['target']
a = [random.uniform(1, 8) for i in range(4)]
print("测试数据为:{}".format(a))
knn = int(input("请输入近邻:"))
test(a, knn, data, label)
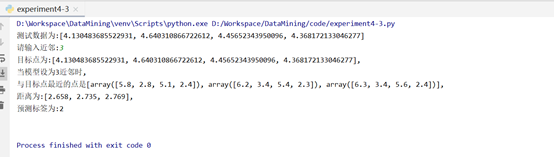 实验结果分析:
实验结果分析:
通过编写KNN算法,了解了KNN算法的原理,首先选择K值,即选出K个相近的点分为一组,以分组后的数据选择一个中心点,再次以这些中心点实现K近邻分类,直至可以分类的目标值基本不再改动。在本实验中随机选择4个数作为一条记录,K值选择3,可得出与该随机记录相邻的3条记录,最后得出该随机记录预测标签为2。

















 1035
1035











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











