







scikit-learn (sklearn) 官方文档中文版
K近邻
K近邻算法详解
机器学习:K-近邻算法(KNN)
k近邻法及kd树
K-近邻需要做标准化处理
相似的样本,特征之间的值应该都是相近的
K取值影响最终结果
距离公式(欧式距离)
两个样本,有三个特征,a(a1,a2,a3),b(b1,b2,b3),c(c1,c2,c3),d,e,f,g…其中a为未分类的,则:step 1:
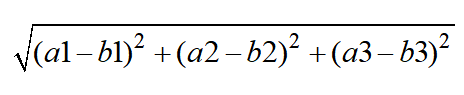
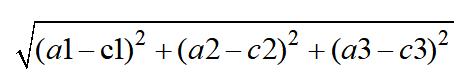
…
之后,比较他们的大小
step 2:选出距离最小的K个值
step 3:在K个值中选出频率最高的作为a的分类结果
案例:某人的签到地点预测
分类问题
特征值:x,y坐标,定位准确性,年,日,时,周 目标值:入住位置的id
处理:0<x<10 0<y<10 为减少数据量
data.query(“x>0 & x<10 & y>0 & y<10”)
-
数据量大,节省时间x,y缩小
-
时间戳进行(年、月、日、周、时分秒),当作新的特征
-
几千~几万的类别,少于签到人数的位置删除
K_Means与K-近邻区别
很多人会把它跟K-Means算法混淆,因为都是K字头的。这里做一下简单的说明:
首先,K-Means是一种无监督的聚类算法,KNN则是有监督的分类、回归算法。
K-Means中的K代表了将数据划分成K个簇,它的核心思想是:根据样本之间的距离大小,将样本划分成K个簇,要求簇内的样本尽量紧密,簇间的距离尽量大。它的实现过程是:随机选择K个质心(K-Means++做了改进),然后计算样本到质心的距离,将样本划分到距离最近的质心的类别,然后更新质心重新划分,直到质心的位置不在发生变化或达到迭代的次数停止。(它是有迭代训练的过程的)
KNN中的K是K个最近邻样本点,由这K个最近邻配合决策方式得要合适的分类或回归值。它的实现过程见上图,包括暴力求解、KD树等。(它没有训练的过程)
朴素贝叶斯算法
贝叶斯公式及应用
朴素贝叶斯算法的理解与实现
机器学习之朴素贝叶斯算法详解
数据挖掘领域十大经典算法之—朴素贝叶斯算法(超详细附代码)
理解朴素贝叶斯分类的拉普拉斯平滑
职业与体型是独立的,不存在在职业下,百分之多少体型怎样。即是独立的,则
注:里面的引用图片来自某个机构的PPT,害怕侵权,特说明
属于某个类别为0,不合适。



于是引出拉普拉斯平滑
注:里面的引用图片来自某个机构的PPT,害怕侵权,特说明


案例:新闻分类
特点:训练误差大,结果肯定不好,
且该算法不需要调参
对缺失数据不太敏感,常用于文本分类
分类准确度高,速度快
另外,神经网络的文本分类效果要好
分类模型的评估
精确率和召回率
1、准确率
estimator.score()
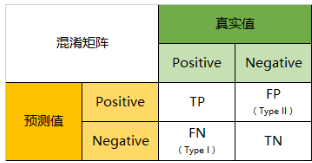
2、混淆矩阵
类模型评判指标(一) - 混淆矩阵(Confusion Matrix)
二级指标
> 灵敏度即召回## 标题率
sklearn.metrics.classification_report


模型选择与调优
- 交叉验证:所有数据分成n等分
注:里面的引用图片来自某个机构的PPT,害怕侵权,特说明

- 网格搜索
调参
调参必备–Grid Search网格搜索
sklearn.model_select.GridSearchCV















 959
959











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









