






【开发语言及实现平台或实验环境】
C++/Clion
【实验目的】
(1)理解词法分析在编译程序中的作用
(2)加深对有穷自动机模型的理解
(3)掌握词法分析程序的实现方法和技术
【实验内容】
对一个简单语言的子集编制一个一遍扫描的词法分析程序。
【实验要求】
(1)待分析的简单语言的词法
- 关键字
begin if then while do end - 运算符和界符
:= + - * / < <= > >= <> = ; ( ) # - 其他单词是标识符(ID)和整形常数(NUM),通过以下正规式定义:
ID=letter(letter|digit)*
NUM=digitdigit* - 空格由空白、制表符和换行符组成。空格一般用来分隔ID、NUM、运算符、界符和关键字,词法分析阶段通常被忽略。
(2)各种单词符号对应的种别编码

(3)词法分析程序的功能
输入:所给文法的源程序字符串
输出:二元组(syn,token或sum)构成的序列。
syn为单词种别码;
token为存放的单词自身字符串;
sum为整形常数。
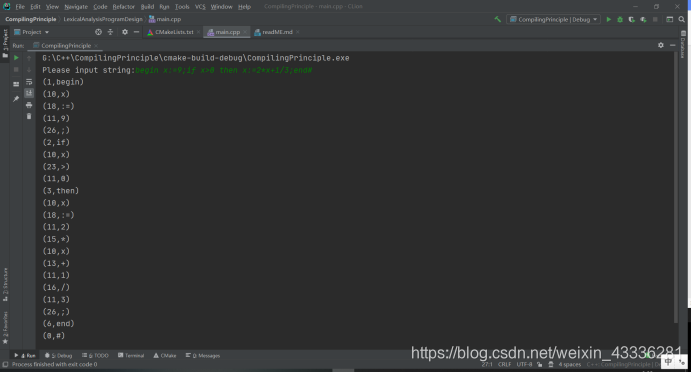
例如:对源程序begin x:=9;if x>0 then x:=2*x+1/3;end# 经词法分析后输出如下序列:(1,begin)(10,’x’) (18,:=) (11,9) (26,; ) (2,if)……
【实验步骤】
(1)根据图1.1构建主程序框架

代码提示:
main()
{
p=0;
printf(“\n please input string:\n”);
do{
输入源程序字符串,送到缓冲区prog[p++]中
}
while(ch!=’#’);
p=0;
do
{
scanner();//调用扫描子程序
switch(syn)
{
case 11:输出(数的二元组);break;
case –1:输出(错误);break;
default:输出(其他单词二元组);
}
} while(syn!=0);
}
(2)关键字表置初值
关键字作为特殊标识符处理,把它们预先安排在一张表格中(关键字表),当扫描程序识别标识符时,查关键字表。如能查到匹配的单词,则为关键字,否则为一般标识符。
(3)编写扫描子程序
代码提示:
scanner()
{
…….
读下一个字符送入ch;
while(ch= =’ ’) 读下一个字符;
if(ch是字母或数字)
{
while((ch是字母或数字))
{
ch=>token;
读下一个字符;
}
token与关键字表进行比较,确定syn的值;
}
else
if(ch是数字)
{
…………..
syn=11;
}
else
swith(ch)//其他字符情况
{
case’<’:
…………
case’>’:
…………
…………………………….
Default:syn=-1;
}
}
(4)调试程序,验证输出结果。
【实验代码】
#include <iostream>
#include <string>
using namespace std;
// 关键字表置初始值
string keyword[30] = {"#", "begin", "if", "then", "while", "do", "end", "", "", "",
"letter(letter|digit)*", "digitdigit*", "", "+", "-", "*", "/",
":", ":=", "", "<", "<>", "<=", ">", ">=", "=", ";", "(", ")"};
class word {
public:
int syn{};
string token;
};
// 处理单词的函数
word letterAnalysis(const string &subCode) {
word item;
if (subCode.substr(0, 5) == "begin") {
item.syn = 1;
} else if (subCode.substr(0, 2) == "if") {
item.syn = 2;
} else if (subCode.substr(0, 4) == "then") {
item.syn = 3;
} else if (subCode.substr(0, 5) == "while") {
item.syn = 4;
} else if (subCode.substr(0, 2) == "do") {
item.syn = 5;
} else if (subCode.substr(0, 3) == "end") {
item.syn = 6;
} else {
// 如果是其它单词,截取到第一个非字符
for (int i = 0; i < subCode.length(); ++i) {
if (!(subCode[i] > 'a' && subCode[i] < 'z')) {
item.syn = 10;
keyword[item.syn] = subCode.substr(0, i);
break;
}
}
}
item.token = keyword[item.syn];
return item;
}
// 处理数字的函数
word numberAnalysis(string subCode) {
word item;
item.syn = 11;
for (int i = 0; i < subCode.length(); ++i) {
// 截取到第一个非数字字符
if (!(subCode[i] >= '0' && subCode[i] <= '9')) {
keyword[item.syn] = subCode.substr(0, i);
break;
}
}
item.token = keyword[item.syn];
return item;
}
// 处理字符的函数
word charAnalysis(string subCode) {
word item;
switch (subCode[0]) {
case '#':
item.syn = 0;
break;
case '+':
item.syn = 13;
break;
case '-':
item.syn = 14;
break;
case '*':
item.syn = 15;
break;
case '/':
item.syn = 16;
break;
case ':':
if (subCode[1] == '=') {
item.syn = 18;
} else {
item.syn = 17;
}
break;
case '<':
if (subCode[1] == '>') {
item.syn = 21;
} else if (subCode[1] == '=') {
item.syn = 22;
} else {
item.syn = 20;
}
break;
case '>':
if (subCode[1] == '=') {
item.syn = 24;
} else {
item.syn = 23;
}
break;
case '=':
item.syn = 25;
break;
case ';':
item.syn = 26;
break;
case '(':
item.syn = 27;
break;
case ')':
item.syn = 28;
break;
}
item.token = keyword[item.syn];
return item;
}
// 词法分析
void scanner(const string &code) {
for (int i = 0; i < code.length(); ++i) {
word item;
if (code[i] > 'a' && code[i] < 'z') {
// 处理单词
item = letterAnalysis(code.substr(i, code.length() - i + 1));
} else if (code[i] >= '0' and code[i] <= '9') {
// 处理数字
item = numberAnalysis(code.substr(i, code.length() - i + 1));
} else if (code[i] == ' ') {
// 如果是空格,直接跳过
continue;
} else {
// 处理特殊符号
item = charAnalysis(code.substr(i, code.length() - i + 1));
}
i += int(item.token.length()) - 1;
cout << "(" << item.syn << "," << item.token << ")" << endl;
}
}
int main() {
string code;
cout << "Please input string:";
// 读入一行代码,因为代码中有空格,所以要用 getline
getline(cin, code);
scanner(code);
return 0;
}
【运行结果】



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











