






 文章讲述了作者在部署到服务器的Django项目中,使用Celery定时任务处理大量PDF时遇到的无预警宕机问题。通过排查发现是PDF处理函数导致的内存占用过多,通过清理pdfplumber缓存解决了问题。作者反思了代码优化的重要性,并对比了过去的计算机硬件条件,提醒开发者关注内存管理。
文章讲述了作者在部署到服务器的Django项目中,使用Celery定时任务处理大量PDF时遇到的无预警宕机问题。通过排查发现是PDF处理函数导致的内存占用过多,通过清理pdfplumber缓存解决了问题。作者反思了代码优化的重要性,并对比了过去的计算机硬件条件,提醒开发者关注内存管理。
有一个项目需求,要在每天凌晨5点的时候执行一个任务,获取一系列的PDF文件并解析。
后端是Django框架,定时任务用Celery来实现的。
本地跑没什么问题,但是一放到服务器上跑就会宕机,而且是毫无征兆的宕机,至少在宝塔面板上看到的宕机前的负载、CPU使用率和内存占用率还是正常的。
一开始以为是Celery的问题,但是排查了很久都没发现有啥问题,尤其是这个脚本在本地是可以跑的。
于是我就不通过Celery,手动执行了一下这个脚本,通过逐行打印的方式,定位到了问题函数。
def process_pdf(self):
for i in range(len(self.pdf.pages)):
print(f"正在处理第 {i} 页……")
page = self.pdf.pages[i]
self.extract_text_and_tables(page)
这个函数就是遍历PDF的每一页,然后提取这一页的文本和表格。
在执行这个函数的过程中,通过 htop 命令实时观察内存占用,发现随着处理的页面越来越多,占用的内存也越来越多,直到服务器完全卡住,宕机了。
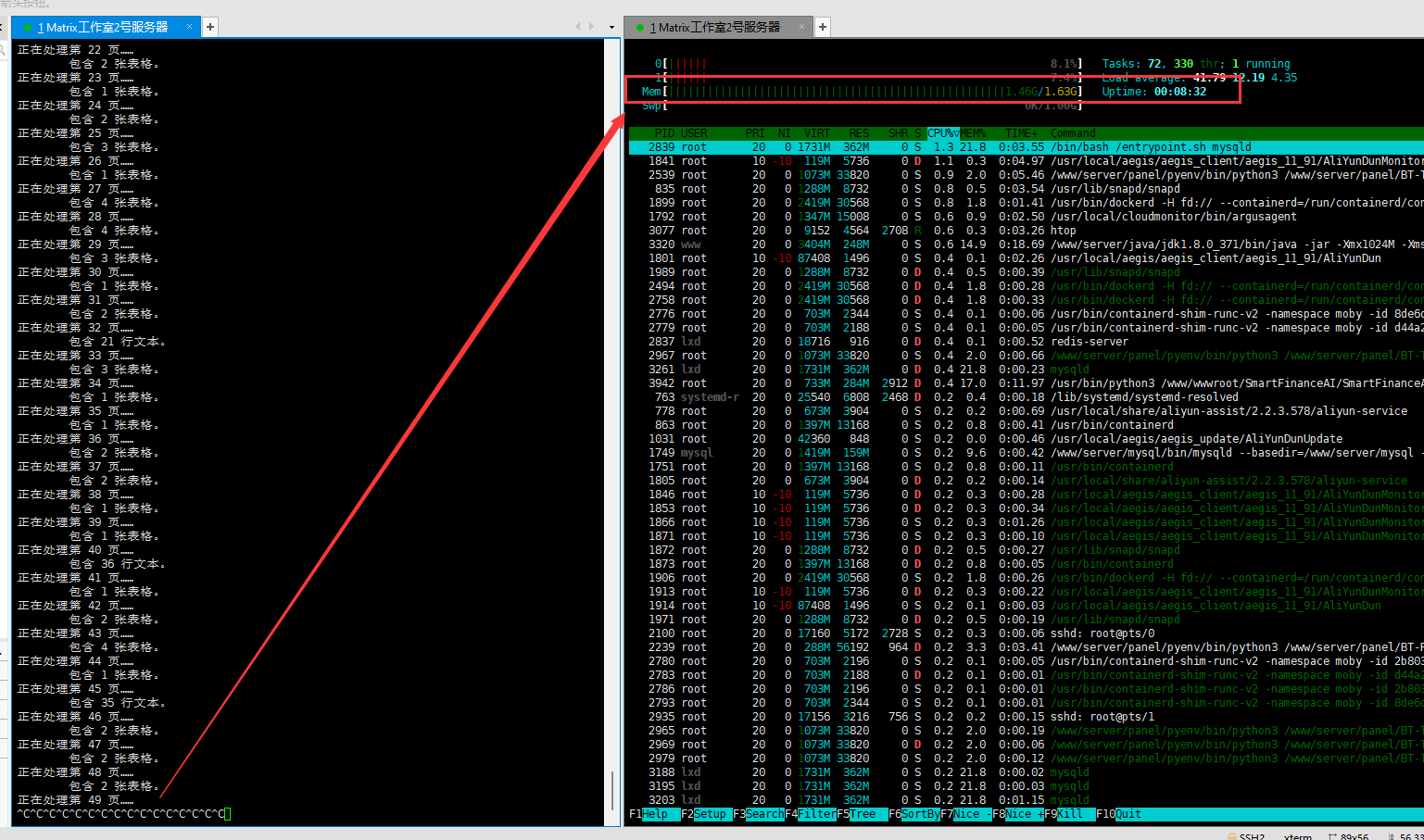
所以问题就很明显了,服务器的资源不够,内存占满了,所以才导致了宕机。
我是通过 pdfplumber 加载的 PDF 文件,所以自然而然的去 pdfplumber 的 GitHub 上看看有没有人遇到类似的问题,果然找到了一个。
Memory issues on very large PDFs
其中提到了一些方法,综合了一下,修改代码如下。
def process_pdf(self):
for i in range(len(self.pdf.pages)):
print(f"正在处理第 {i} 页……")
page = self.pdf.pages[i]
self.extract_text_and_tables(page)
# 清理缓存,避免内存泄漏
# https://github.com/jsvine/pdfplumber/issues/193
del page._objects
del page._layout
page.flush_cache()
gc.collect()
问题解决!
其实一开始也想到了可能是机器资源不行,毕竟是比较低配的机器,还抱怨过要是有钱买服务器就好了。
但是发现问题并解决问题之后,更多的其实是有一些羞愧,自己还是太菜了,代码有漏洞。
再想想当年阿波罗登月的时候,计算机内存只有几十 KB,就这样人家都能上月球,现在服务器内存都 2G 了,还不知足。
菜就多练,今天这次之后,处理这种大文件就记得要关注内存泄漏的问题了。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











