







你是否有遇到下面的问题,提交了很多 jobs 到集群机器中,导致了很多 job 被 PEND 了,这种情况是在等待状态为 RUN 的那些 jobs 运行完成,但是你有没有想过一个问题就是,当那些RUN的 job 中有一个运行出错了,这样这个进程就一直在处于等待的阶段,一直占用着内存等信息。
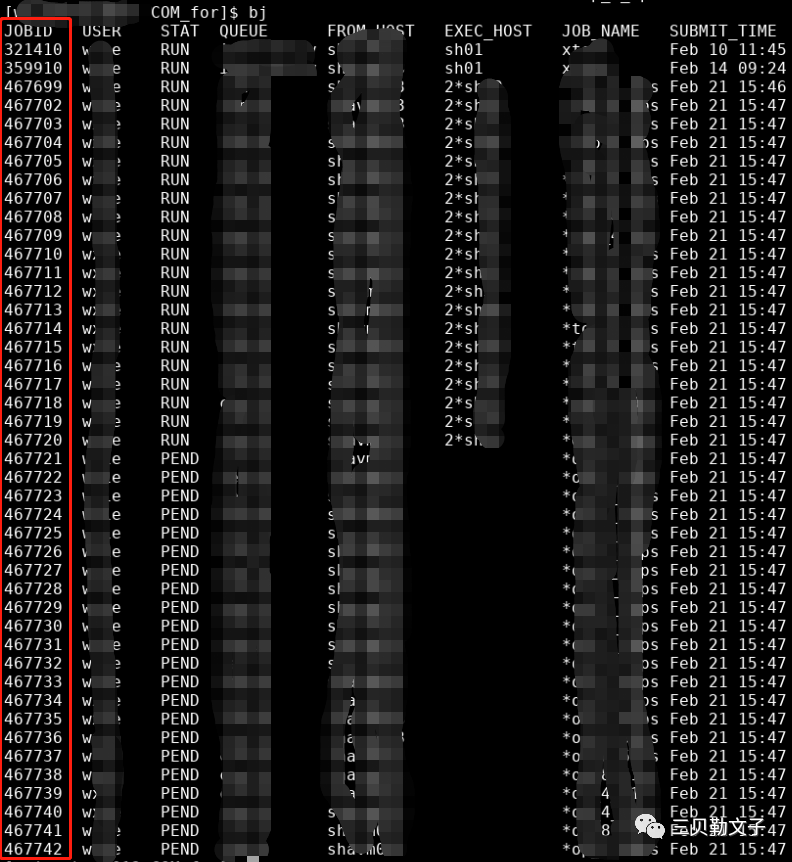
当然,我们可以使用 bkill 根据 JOBID 来结束该 job,像下面的操作:
bkill 467727执行上面的命令后,JOBID 为 467727的 job 就会被kill掉,但是有一个问题就是当你要 kill 掉所有状态为 PEND 的 jobs的时候,你该不会去一个一个来 kill 吧,太浪费时间了, 而且也很无聊。对此,小编有以下几个推荐,看看你觉得哪一个合适:
第一:使用 python 脚本作为辅助,也就是将要 kill 的所有 jobs 的 id 的范围记录下来然后进行遍历 kill :
import os
for i in range(467721, 467742):
os.system("bkill " + str(i))这种情况只适合于要 kill 的 jobs id 是连续的;
第二:将所有的 jobs 都 kill 掉,就相当于把屏幕显示的所有进程都 kill 掉:
bkill -u $user_name 0 // $user_name代表进程表中的第二列 USER第三:如果是选择性的 kill 某些 jobs 的话,则可以通过将 jobs 打印到文件中,然后编辑文件,使文件里面保留要被 kill 的 jobs 的 id 号:
bjobs > serven // 把 jobs 状态放到文件serven里面
gvim serven // 进入 serven 文件, 删掉那些除进程以外的信息,可以通过替换来删除比较快速
cat serven | xargs bkill // 删掉 serven 文件里面的内容第四: 杀掉提交到某个 queue (例如:cent6) 的所有进程:
bkill -q cent6 0 // 0 代表该 queue 里面所有的进程
对于删不掉的 job 加上”-r“
bkill -r $JOBID查看进程执行到了那一步:
bjobs -w // 可以得到详细的进程信息查看某个进程执行到哪里的并且打印信息:
bpeek -f $JOBID

















 1768
1768

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











