






Attention Is All You Need :引入自注意力机制
VIT :将transformer 引入cv ,使用Patch和位置编码
Swin transformer :提出层次化(hierarchical)Transformer,其表示用位移窗口(shifted Windows)计算
Attention Is All You Need
使用注意力,效果好,速度好。可扩展到图片和图像上
Architecture
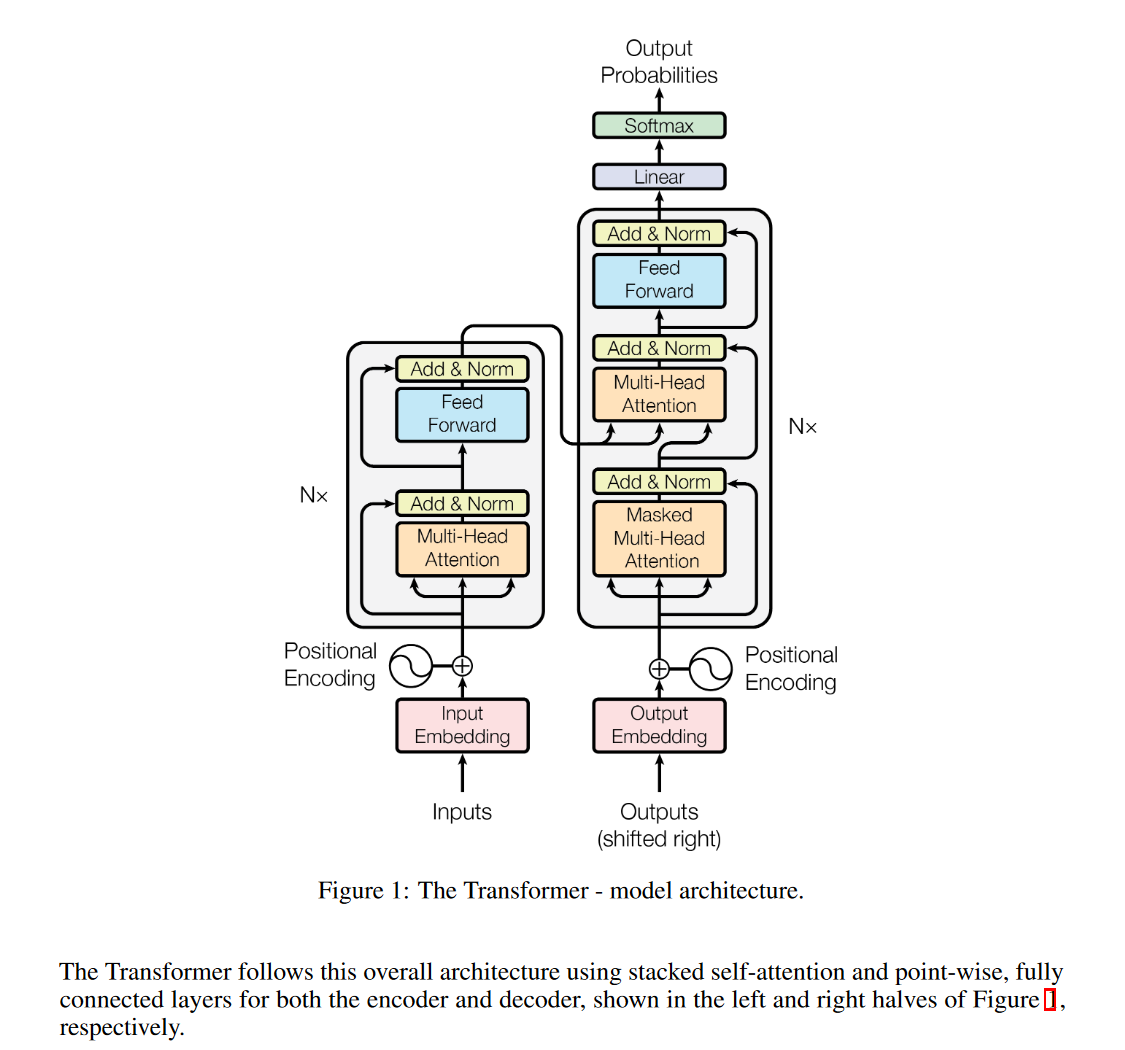
Contribution
注意力机制
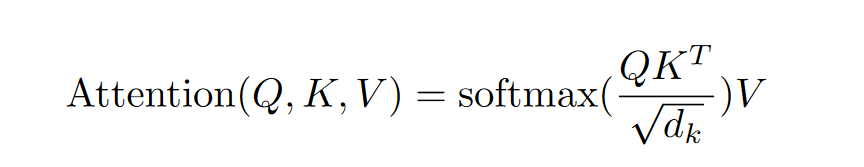
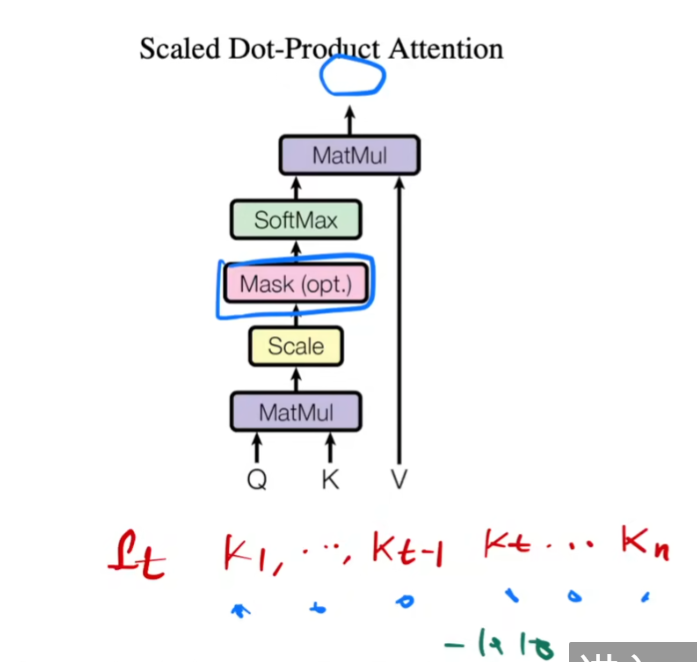

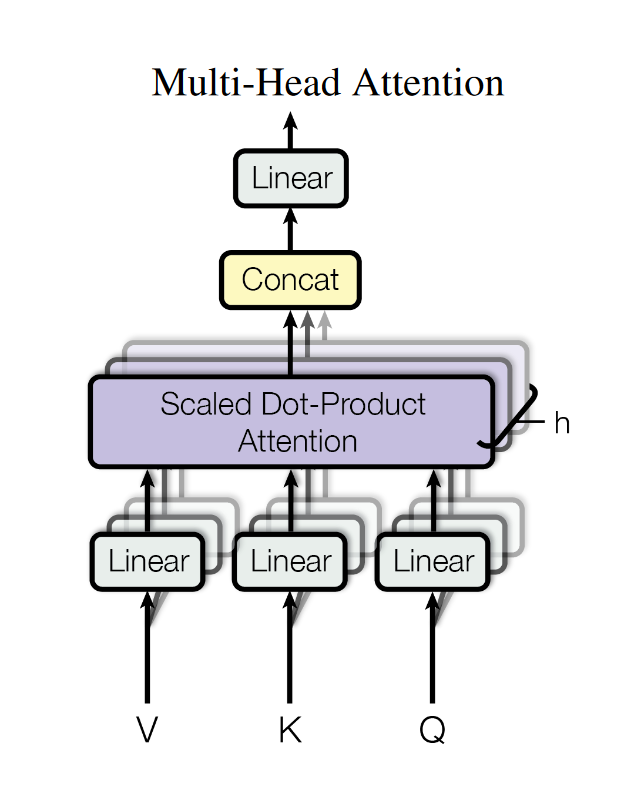
多头注意力机制
multi-head self attention (MSA)
Layernorm和batchnorm的区别
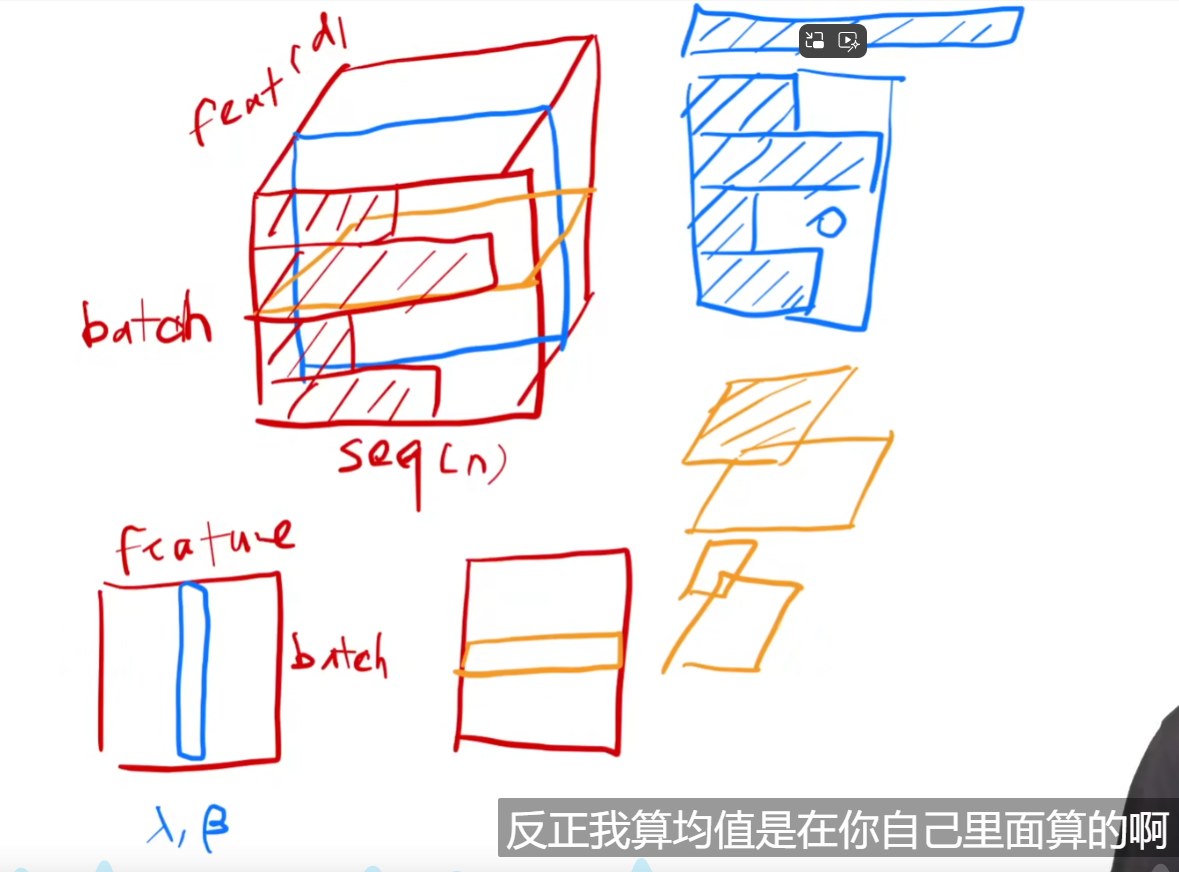
如何使用注意力的?
自注意力:key value query 是一个值
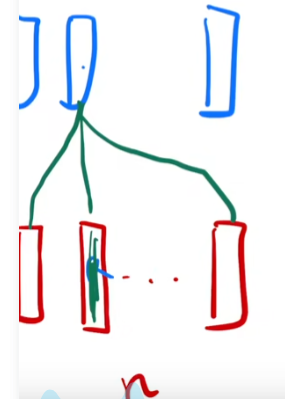
输出是你自己本身和其他向量的加权和
VIT :AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
期刊:ICLR( International Conference on Learning Representations ) 2021
Architeture
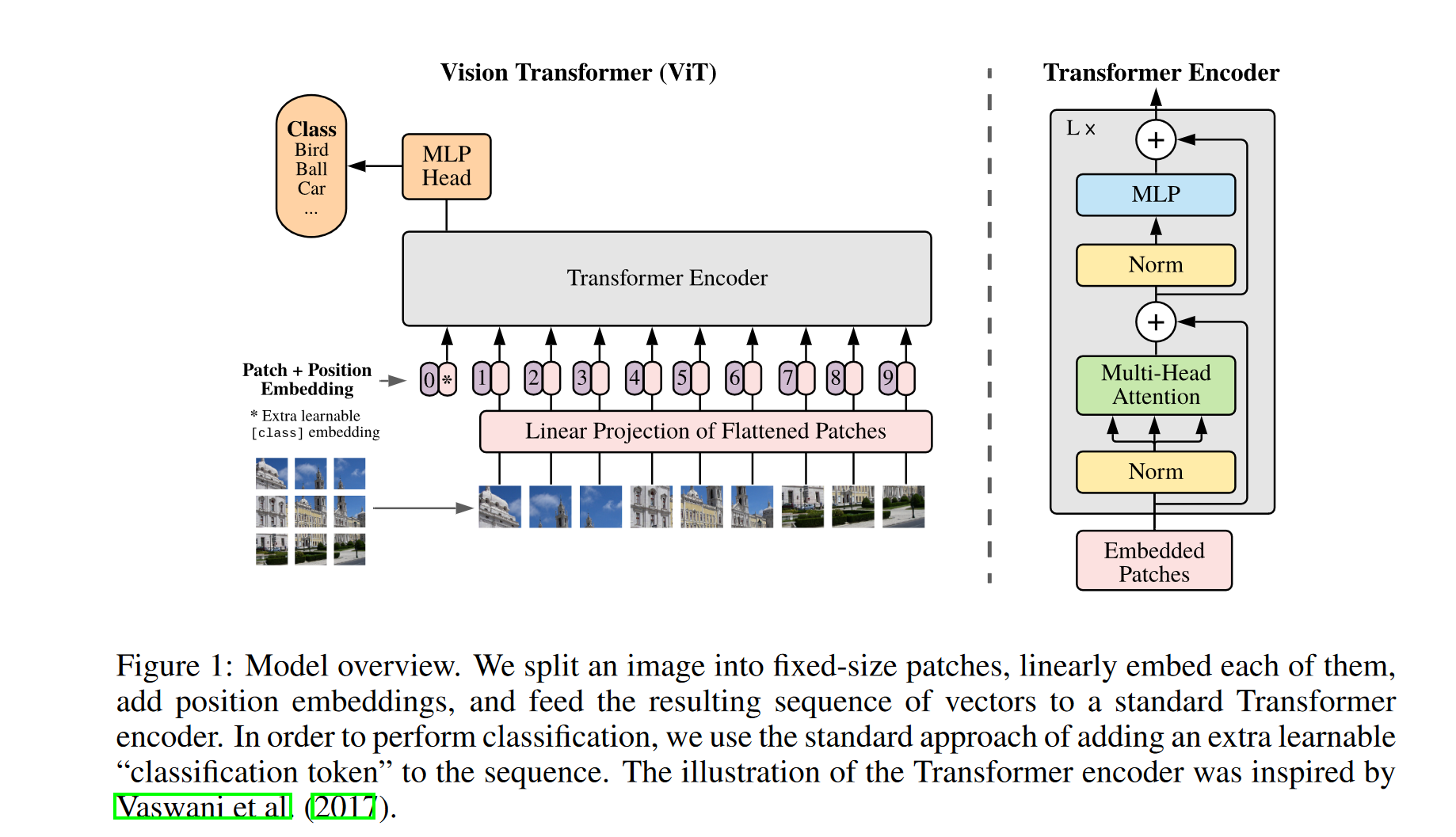
Patch+Position+class
https://zhuanlan.zhihu.com/p/445122996
Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
期刊:iCCV( International Conference on Computer Vision, )21最佳论文
挑战:such as large variations in the scale of visual entities and the high resolution of pixels in images compared to words in text.
Architeture
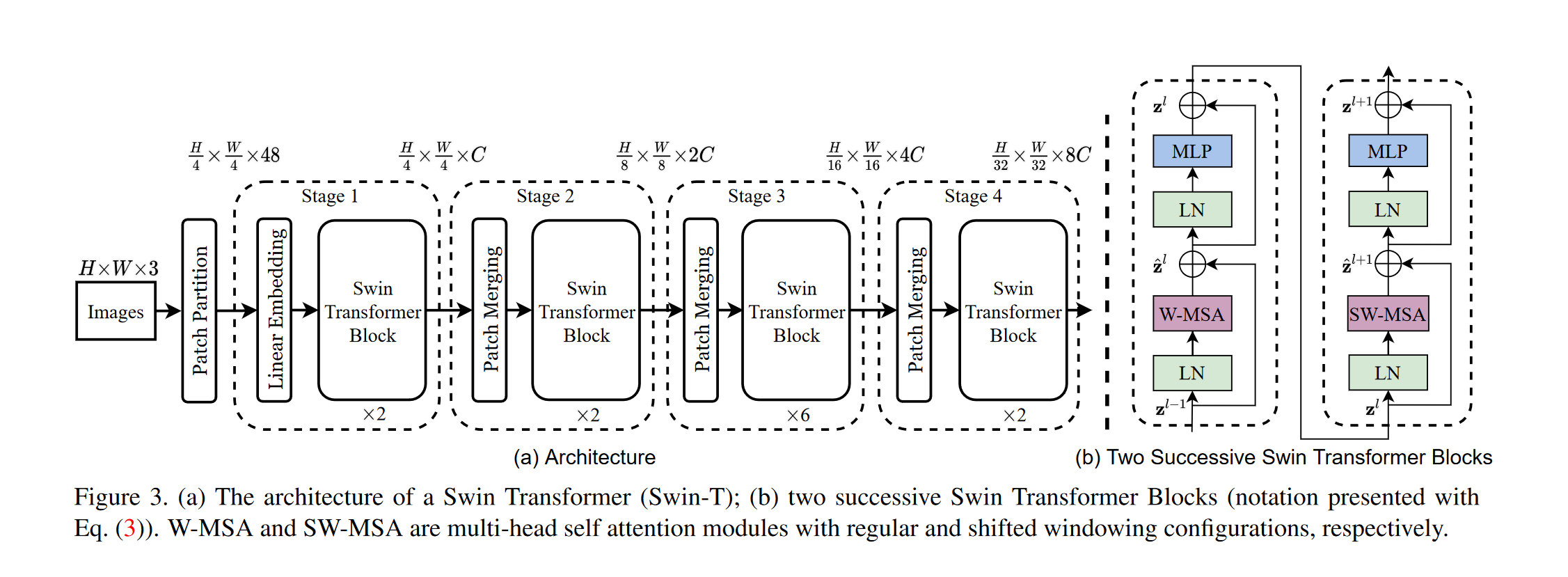
Swin transformer 和 VIT 对比
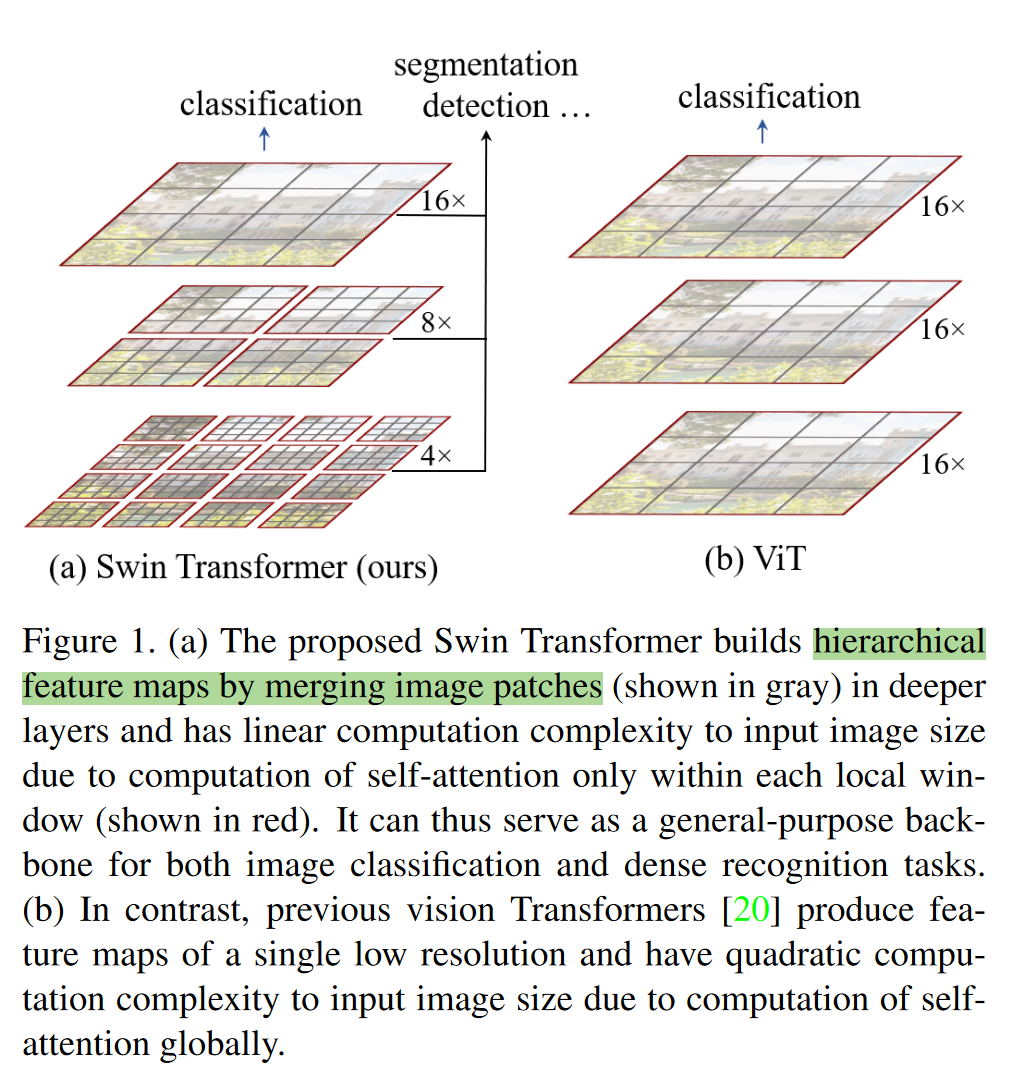
使用局部特征这个先验知识
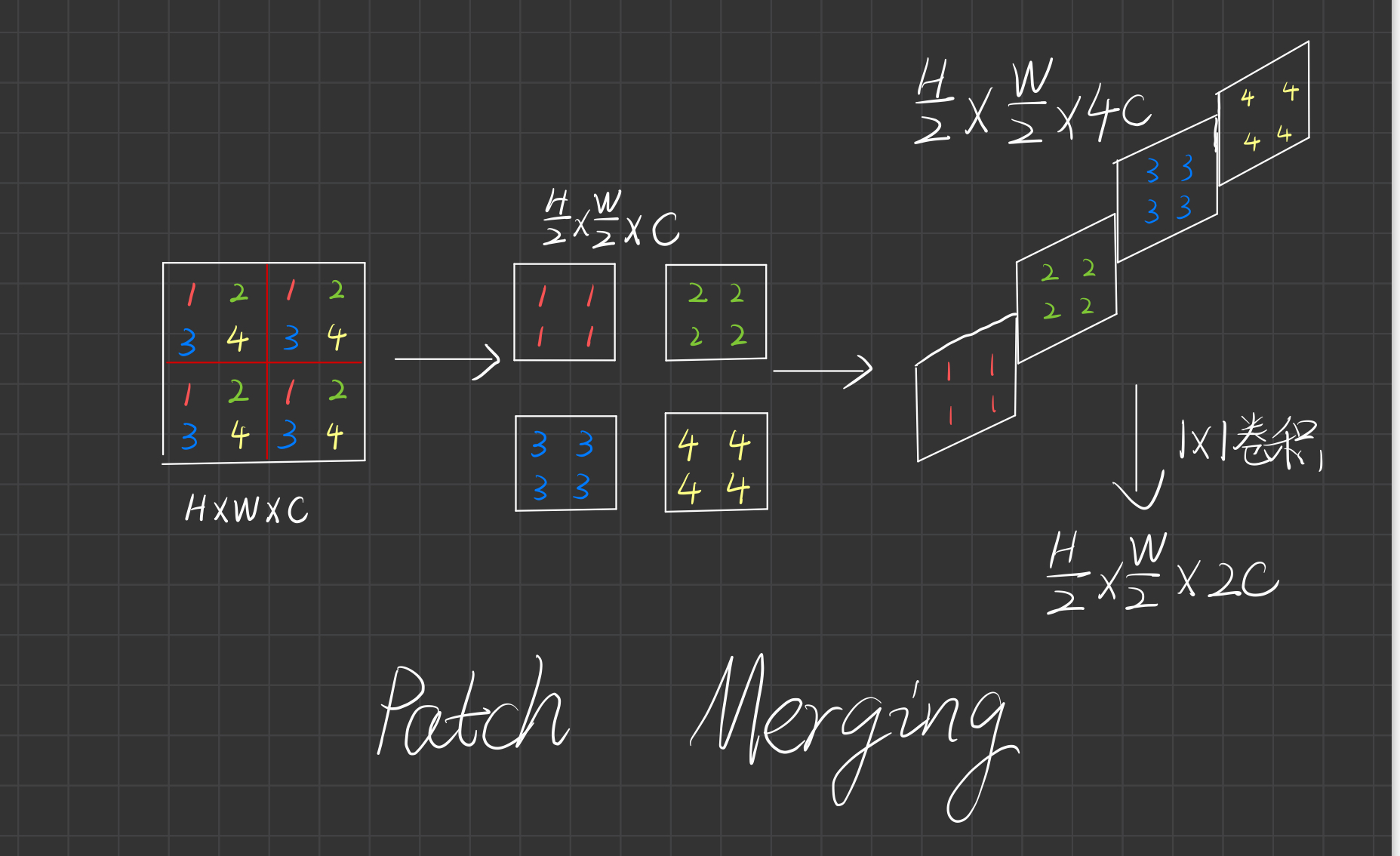
Patch mergeing
与Pixel shuffle相反的过程
shifted windows:
W-MSA & SW-MSA
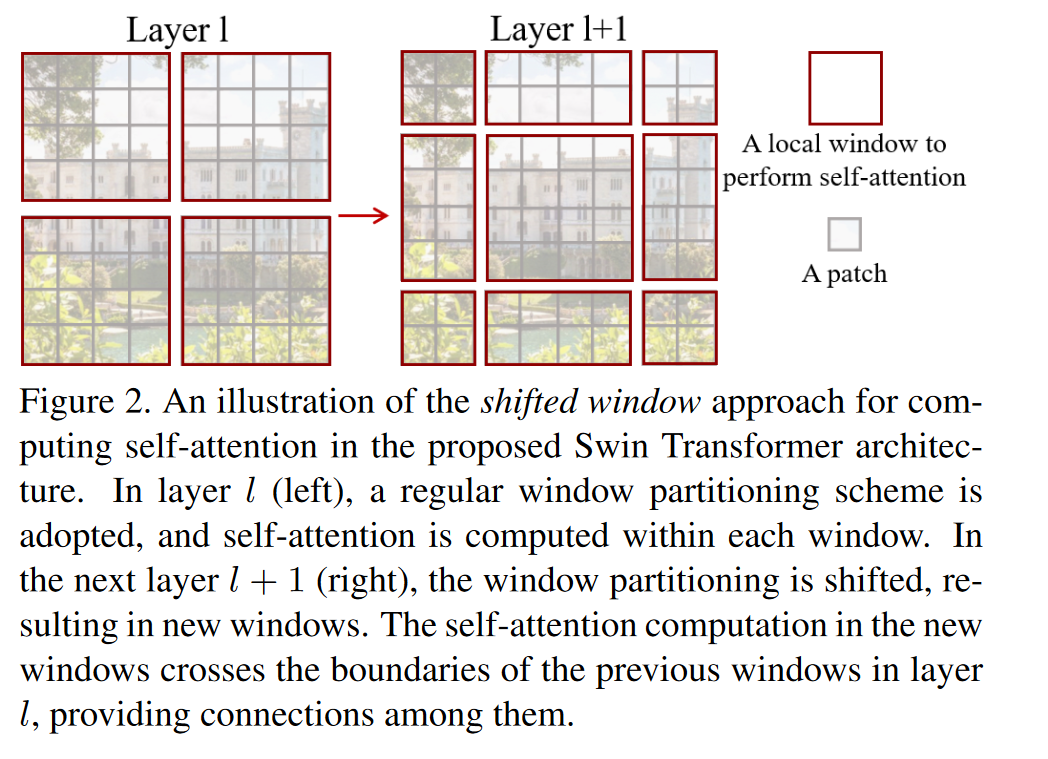
窗口自注意力机制:
FlowFormer: A Transformer Architecture for Optical Flow
期刊:ECCV( European Conference on Computer Vision )2022
知识点补充
- 超像素(Superpixel)是一种图像处理技术,它将图像分割成一组有意义的小区域,这些区域称为超像素。每个超像素通常是由具有相似颜色、纹理或其他特征的像素组成的相邻像素群。超像素的生成有助于简化图像的处理和分析,因为与处理单个像素相比,处理这些较大且更有意义的区域可以大大降低计算复杂度。
- Inductive biases(归纳偏置)在机器学习和人工智能中是指在学习算法中引入的先验知识或假设,这些假设帮助算法更有效地从有限的数据中学习并进行泛化。归纳偏置使得算法在面对不同问题时能够更快地收敛,并且在未见过的数据上表现良好。
cv中常用的inductive biases
1. locality :相邻区域有相关特征
2. translation equivaraince(平移同变性):不管是先平移还是先卷积输出一样
3.自注意力机制
- stand-alone attention
- axis attention
4.Pixel Shuffle 是一种在深度学习中常用于超分辨率任务的操作。它能够将低分辨率图像的多个通道重排列成高分辨率图像的少量通道。具体来说,它是一种重构图像空间维度的方法,从而提高图像分辨率。
Pixel Shuffle 操作的核心思想是将一个特征图中的低分辨率高通道数据重新排列成高分辨率低通道的数据。这通常用于生成模型(例如超分辨率神经网络)中的上采样层。
以下是 Pixel Shuffle 的工作原理:
假设输入是一个大小为
(
C
×
r
2
,
H
,
W
)
(C \times r^2, H, W)
(C×r2,H,W) 的张量,其中 © 是通道数,(H) 和 (W) 分别是高度和宽度,® 是上采样因子。
Pixel Shuffle 的操作步骤如下:
- 重新排列输入张量的形状为 ( r , r , C , H , W ) (r, r, C, H, W) (r,r,C,H,W)。
- 交换轴并合并空间维度,得到一个大小为 ( C , H × r , W × r ) (C, H \times r, W \times r) (C,H×r,W×r) 的输出张量。
这个过程将低分辨率图像的多个通道“拆分”并重新组合,形成一个高分辨率的图像。
在 PyTorch 中,Pixel Shuffle 可以通过 torch.nn.PixelShuffle 实现。例如:
import torch
import torch.nn as nn
# 定义输入张量
input_tensor = torch.randn(1, 16, 8, 8) # Batch size = 1, Channels = 16, Height = 8, Width = 8
# 定义 Pixel Shuffle 层
pixel_shuffle = nn.PixelShuffle(upscale_factor=2)
# 应用 Pixel Shuffle 层
output_tensor = pixel_shuffle(input_tensor)
print(output_tensor.shape) # 输出张量的形状应该是 (1, 4, 16, 16)
在这个例子中,上采样因子是 2,输入张量的通道数是 16,经过 Pixel Shuffle 操作后,输出张量的通道数变为 4,空间维度从 8x8 变为 16x16。















 40万+
40万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









