P(A|B)和P(AB)有什么区别
最新推荐文章于 2022-11-08 18:15:48 发布





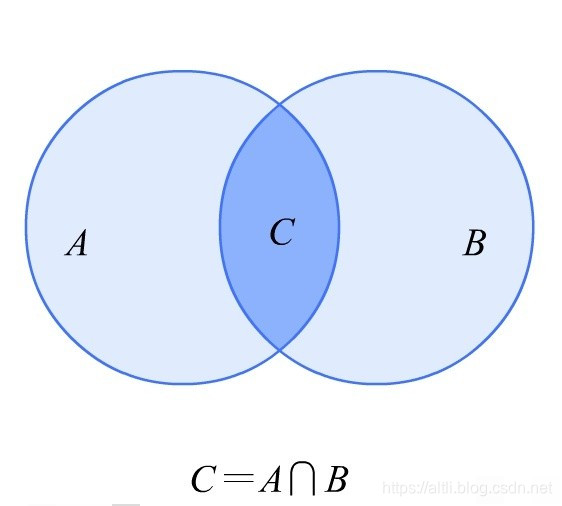
 本文深入探讨了条件概率P(A|B)与联合概率P(AB)的区别,从时间与空间角度解释了两者概念的不同,并通过具体公式P(AB)=P(A|B)*P(B)说明了它们之间的联系。
本文深入探讨了条件概率P(A|B)与联合概率P(AB)的区别,从时间与空间角度解释了两者概念的不同,并通过具体公式P(AB)=P(A|B)*P(B)说明了它们之间的联系。
本文深入探讨了条件概率P(A|B)与联合概率P(AB)的区别,从时间与空间角度解释了两者概念的不同,并通过具体公式P(AB)=P(A|B)*P(B)说明了它们之间的联系。
本文深入探讨了条件概率P(A|B)与联合概率P(AB)的区别,从时间与空间角度解释了两者概念的不同,并通过具体公式P(AB)=P(A|B)*P(B)说明了它们之间的联系。
 2076
5972
2076
5972

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言