







MULTI-LABEL IMAGE RECOGNITION WITH JOINT CLASS-AWARE MAP DISENTANGLING AND LABEL CORRELATION EMBEDDING
文章连接:
代码:
文章目录
摘要
多标签图像识别是一项基本但具有挑战性的计算机视觉任务。通过探索这些多标签之间的标签相关性,已经取得了很大的进展,这是多标签识别中最关键的问题。在本文中,我们提出了一个统一的深度学习框架来联合解开与区分类别信息(category-wise information)对应的类别特定映射(class-specific maps),然后评估这些映射的标签共现性。具体来说,在获得一般的深度图像特征并进行多标签分类后,我们利用分类权值将特征映射重构为类感知的解纠缠映( class-aware disentangled maps)(CADMs)。然后,基于cadm,我们首先将其转移到标签向量中,然后用标签嵌入(label embedding)表示标签相关依赖关系(label correlation dependency)。整个模型由分类损失和标签相关嵌入损失( label correlation embedding loss)驱动,可以端到端训练。两个基准多标签图像数据集的广泛定量结果表明,我们的模型始终优于其他竞争方法。同时,定性分析也表明,我们的模型可以有效地捕获相对纯的类感知映射和模型标签相关相关性。
1. Introduction
一种简单而直接的多标签识别方法是为每个标签训练一个二元深度分类器。然而,从多标签数据中学习的主要挑战在于潜在的巨大规模的输出空间。为了应对如此巨大的输出空间的挑战,一个常见的做法是探索标签相关性,以促进学习过程。在文献中,Gong等人[8]评估了各种损失函数,发现加权近似排序损失对深度cnn效果最好。此外,Hu等人[9]提出使用结构化推理神经网络来对多个标签的标签相关性进行建模。Li等人[10]利用概率图形模型来捕获标签相关相关性。
最近,研究人员试图应用注意机制来发现不同注意区域之间的标签相关性,In [12], the authors developed
the spatial regularization net to focus on the objectiveness regions(目标区域), and further learned label correlation of these regions by self-attention.而Wang等人[11]提出了空间变压器,首先捕获目标区域,然后使用lstm来处理标签相关性。尽管取得了很好的改进,但现有的方法在识别和恢复多个标签的共现方面仍然存在局限性,更具体地说: 1)分离出特定类别的图像区域,2)进一步共同评估它们对应的标签共现。如果这两个过程能够很好地执行,它将显著提高多标签识别性能。
在本文中,我们提出了一个统一的多标签图像识别框架,它由两个关键模块组成,针对上述两个过程。我们的模型的体系结构如图1所示。
在获取generate and holistic feature之后,第一个模块可以以一种简单而有效的方法将类感知的映射从全局图像级表示中分离出来,即利用分类权值将特征映射重构为类感知的解纠缠映射。Each map of the so called class-aware disentangled maps corresponds to(对应于) one specific class/label meaning of the multiple labels。它可以相对纯粹地反映其特定标签的语义信息,同时与空间上下文相关联(图2)。特别是,类感知的解纠缠映射(CADMs)的数量等于标签的数量。我们的模型的第二个模块是基于所获得的cadm,它旨在以更明确的(explicit)方式建模多标签共现,如图3所示。
我们首先将cadm转换为一个标签向量。在标签向量空间中,对于多标签识别,它假设相关的标签(标签向量)应该相互封闭,并形成一个虚拟的集群。请注意,由于嵌入操作是在标签向量空间中执行的,因此cadm的鉴别能力不会被破坏。然后,我们将其表示为标签相关嵌入损失函数。在传统的多标签识别损失和标签相关嵌入损失的驱动下,我们的模型可以以端到端方式进行训练,不需要任何额外的注释。简而言之,我们的方法探索了标签的空间相关性,并利用其作为分类的附加线索。特别是,标签相关嵌入层可以从本质上学习class-aware map之间的相关性(例如,如果有一个“人”在它上面,“滑雪板”的激活将会增强)。
创新点:
我们设计了该模型的两个功能模块,即类感知映射分离和标签相关嵌入模块,分别用于利用空间上下文捕获类特定信息和标签共现建模。
[9]H. Hu, G.-T. Zhou, Z. Deng, Z. Liao, and G. Mori, “Learning structural inference neural networks with label relations,” in CVPR, 2016, pp.2960–2968.
[10]Q. Li, M. Qiao, W. Bian, and D. Tao, “Conditional graphical LASSO for multi-label image classification,” in CVPR, 2016, pp. 2977–2986.
[11]Z. Wang, T. Chen, G. Li, R. Xu, and L. Lin, “Multi-label image recognition by recurrently discovering attentional regions,” in ICCV, 2017, pp.464–472.
[12]F. Zhu, H. Li, W. Ouyang, N. Yu, and X. Wang, “Learning spatial regularization with image-level supervisions for multi-label image classification,” in CVPR, 2017, pp. 5513–5522.
2. Method
2.1 Model overview
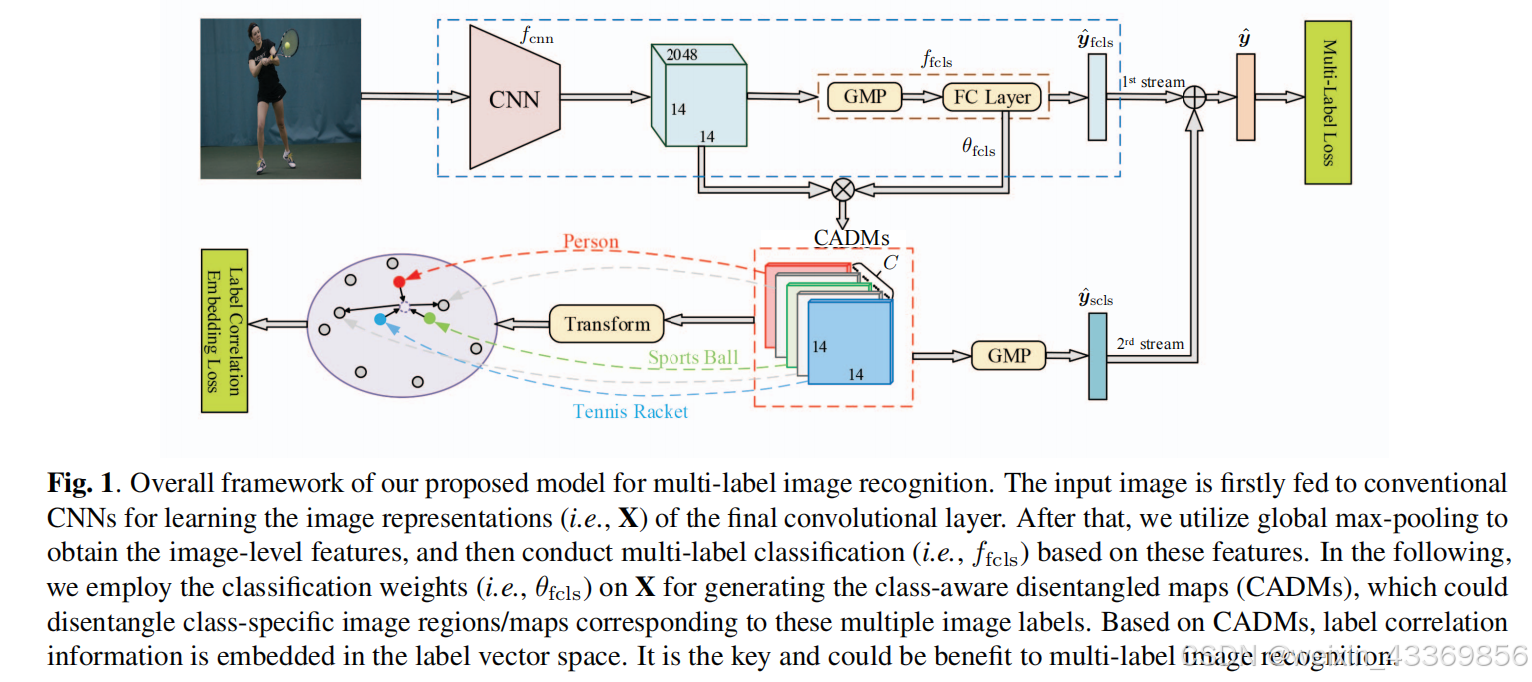
首先,从CNN网络中获取丰富的图像信息, these feature maps are embedded with rich spatial information, and are also known to obtain mid- and high-level information
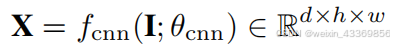
Specifically, here h = 14, w = 14, and d = 2048.
之后,为了测量最终的预测误差,我们结合两个预测的标签置信度作为双流聚合,如图1的最右边。
对于第一个流的标签置信度,我们在X上使用全局最大池化(GMP)来获得图像级特征,然后对每个C标签进行二进制分类
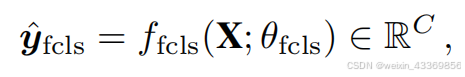
y
^
fcls
=
[
y
^
fcls
1
,
y
^
fcls
2
,
⋯
,
y
^
fcls
C
]
⊤
\hat{\mathbf{y}}_{\text{fcls}} = \left[ \hat{y}_{\text{fcls}}^1, \hat{y}_{\text{fcls}}^2, \cdots, \hat{y}_{\text{fcls}}^C \right]^{\top}
y^fcls=[y^fcls1,y^fcls2,⋯,y^fclsC]⊤,每个元素表示每个类别的置信度概率。
对于第二个流,类感知的解纠缠特征图(CADMs)上执行深度级全局最大池化(depth-wise max pooling)来获得其标签置信度
y
^
scls
\hat{\mathbf{y}}_{\text{scls}}
y^scls。类感知映射不仅包含局部级的空间上下文信息(spatial contexts information )(即激活),而且还具有全局级的类特定的语义意义(global-level class-specific semantic)。
将二者相加做平均作为最后多分类预测logtis
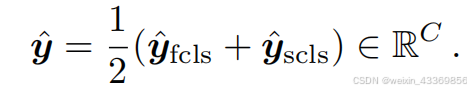
然后计算交叉熵损失
L
cls
=
∑
c
=
1
C
y
c
log
(
σ
(
y
^
c
)
)
+
(
1
−
y
c
)
log
(
1
−
σ
(
y
^
c
)
)
\mathcal{L}_{\text{cls}} = \sum_{c=1}^{C} y^c \log(\sigma(\hat{y}^c)) + (1 - y^c) \log(1 - \sigma(\hat{y}^c))
Lcls=c=1∑Cyclog(σ(y^c))+(1−yc)log(1−σ(y^c))
再加上用于约束标签相关性的label correlation embedding loss
L
lce
\mathcal{L}_{\text{lce}}
Llce,for explicitly modeling the label co-occurrence cues
最终的loss为:
L
=
L
cls
+
λ
⋅
L
lce
\mathcal{L}=\mathcal{L}_\text{cls}+\lambda\cdot\mathcal{L}_\text{lce}
L=Lcls+λ⋅Llce
2.2 Class-aware map disentangling
The disentangled maps could benefit to evaluate the label correlation
and embed the label correlation information into the whole
multi-label learning system.
Inspired by [16],我们通过
θ
fcls
\theta_{\text{fcls}}
θfcls从原始特征中分里C class-specific maps, 然而,与[16]中使用的全局平均池不同的是,这里我们使用全局最大池来保持小尺寸对象的突出激活。
θ
fcls
\theta_{\text{fcls}}
θfcls可以被视为一个滤波器,从特征X中过滤出第c个标签的类别特定的鉴别信息(class-specific discriminative information)
class-specific map可以通过以下计算得到:
A
c
=
θ
f
c
l
s
c
⊤
⋅
X
∈
R
h
×
w
\mathbf{A}_{c}={\theta_{fcls}^{c}}^{\top} \cdot X \in \mathbb{R}^{h \times w}
Ac=θfclsc⊤⋅X∈Rh×w
A
=
θ
f
c
l
s
⊤
⋅
X
∈
R
C
×
h
×
w
\mathbf{A}={\theta_{fcls}}^{\top} \cdot X \in \mathbb{R}^{C\times h \times w}
A=θfcls⊤⋅X∈RC×h×w
其中
θ
f
c
l
s
∈
R
d
×
C
{\theta_{fcls}}\in\mathbb{R}^{d \times C}
θfcls∈Rd×C,
X
∈
R
d
×
h
×
w
\mathbf{X} \in \mathbb{R}^{d\times h\times w}
X∈Rd×h×w
The observations verify that the class-aware map disentangling approach can both decouple label semantic information and localize class-specific regions at the same time
2.3 label correlation embedding
In order to capture label correlation, we propose to explicitly model it via label correlation embedding in a metric learning fashion.
我们的模型将于图像关联的class-aware region maps嵌入到一个多为label空间中,每个label都关联着一个固定尺寸的label vector,因此两个相关label的共现关系可以通过label vector在label space中的距离来测量。
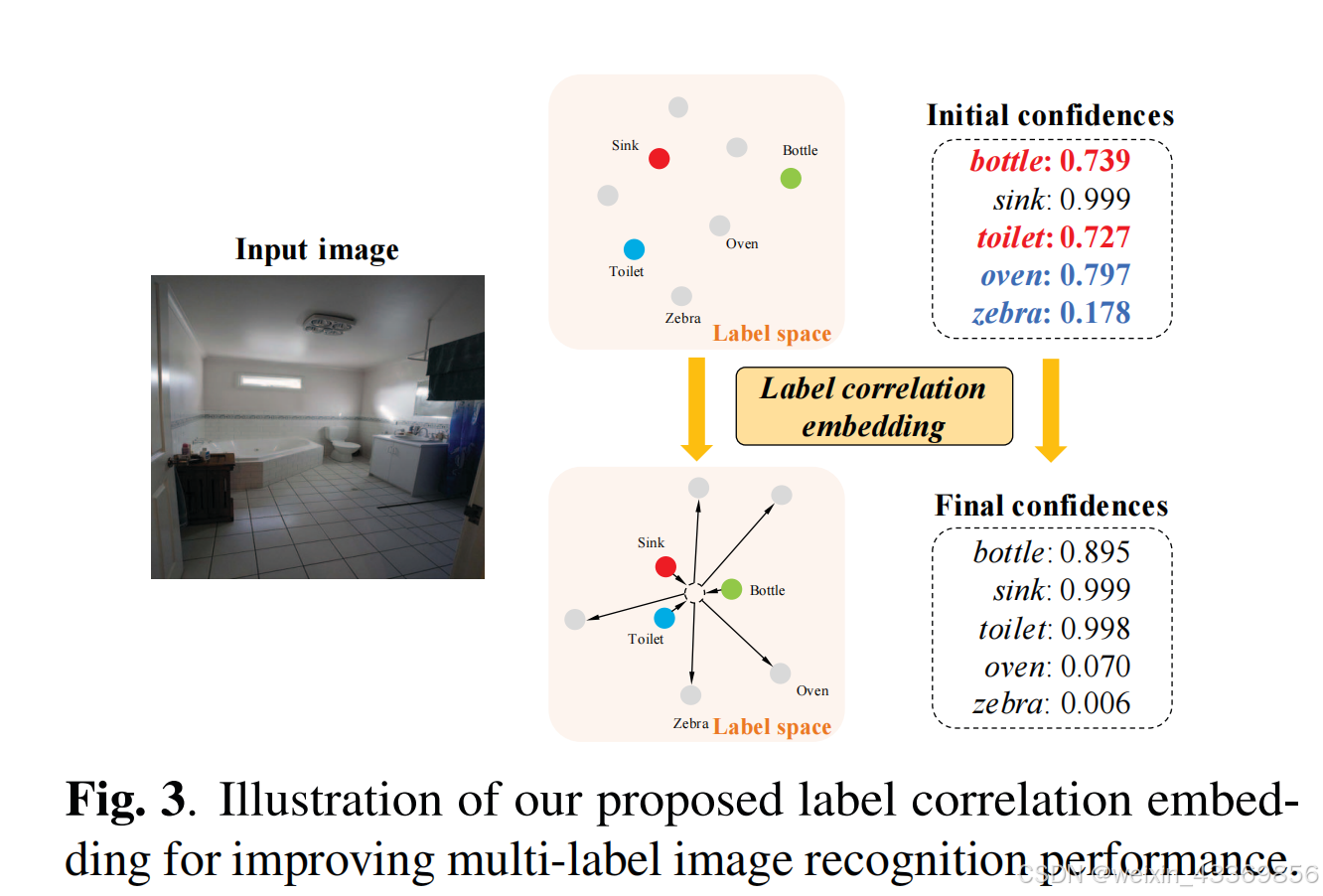
采用度量学习的思想测量label embedding的距离,相关度高的标签可以被聚集到一起,不相关的标签应该远离聚类中心。
将CADM每个类别对应的class-aware map
A
c
\mathbf{A}_{c}
Ac沿着空间维度展开成一维向量
f
flat
(
A
c
)
∈
R
1
×
(
h
×
w
)
f_\text{flat}(\mathbf{A}_{c})\in\mathbb{R}^{1\times(h\times w)}
fflat(Ac)∈R1×(h×w),然后用一个非线性层上述张量嵌入label space(其实就是用两层全连接层+ReLu)
a
c
=
f
embed
(
f
flat
(
A
c
)
;
θ
embed
)
\mathbf{a}_c={f_{\text{embed}}(f_{\text{flat}}(\mathbf{A}_c);\theta_{\text{embed}})}
ac=fembed(fflat(Ac);θembed)
因此,标签相关嵌入的目标是最小化相关标签向量的成对欧氏距离的和


3. Experiment
指标:average per-class precision, recall, F1 (CP, CR, CF1)
average overall precision, recall, F1 (OP, OR, OF1)
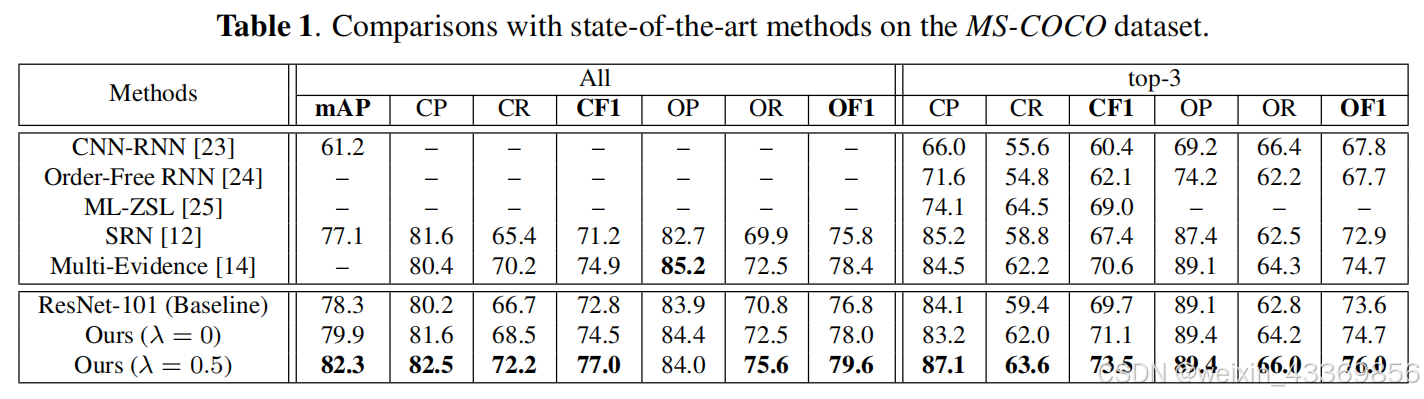
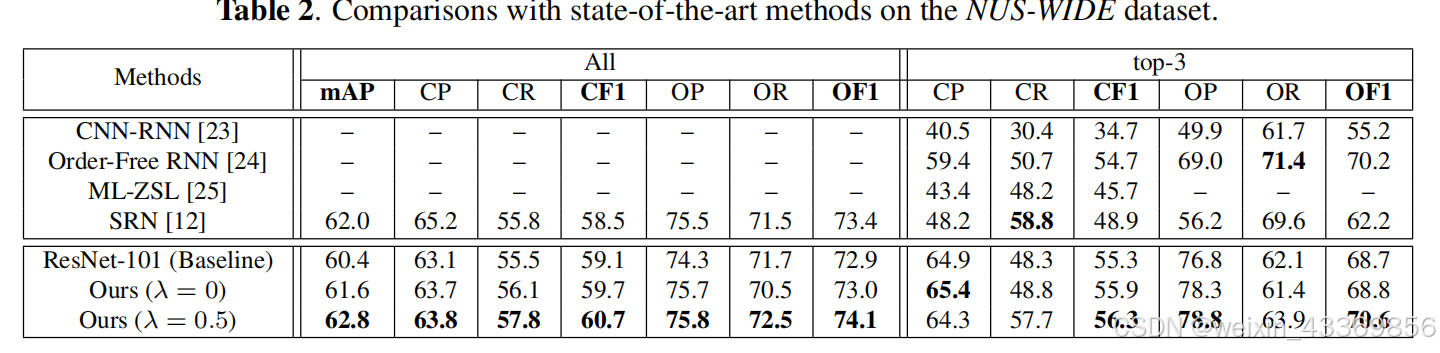
总结
在本文中,我们提出了一个多统一的多标签图像识别框架。我们的模型由两个关键模块组成,即类感知映射解纠缠和标签相关嵌入。只有图像级的监督,我们的模型就可以以端到端的方式进行训练。实验结果和可视化分析从定量和定性的角度验证了该方法的有效性。在未来,开发新的标签相关嵌入损失是进一步提高性能的前景。

















 53
53

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









