







大型语言模型会记忆和重复训练数据,从而造成隐私和版权风险。为了减少记忆,作者对 NSP 训练目标进行了微妙的修改,称之为 goldfish loss。在训练过程中,随机抽样的 token 子集将被排除在损失计算之外。这些被剔除的 token 不会被模型记忆,从而防止逐字复制训练集中的完整 token 链。
作者进行了大量实验来训练十亿规模的 Llama-2 模型,包括预训练的和从头开始训练的,结果表明可提取的记忆量显著减少,对下游基准几乎没有影响。
在多轮对话的数据清洗过程中,如果未能将一些重复的话语(后处理保底或预设的回复)以及一些人名进行清洗,模型很容易学到这一完整的回复,即使数据量很少。当时老板推荐了一篇论文(暂时找不到了,里面提到对注意力进行 random mask,来避免过拟合),我当时没有修改 attention mask,转而去对参与计算 loss 的 label 进行 random mask,没想到这个做法现在发了论文,但这篇论文做了很多的实验来验证 Goldfish Loss 的有效性,做了大量的工作。
Goldfish Loss:Learning Without Memorizing
LLM 通常使用因果语言建模(CLM)目标进行训练,该目标表示一个 token 的平均对数概率,以之前的所有 token 为条件。对于一个由 L 个训练 token 组成的 x = { x i } x = \{x_i\} x={xi} 序列,可以写成:
L ( θ ) = − 1 L ∑ i = 1 L l o g P ( x i ∣ x < i ; θ ) (1) L(\theta) = - \frac{1}{L} \sum_{i=1}^L log \ P(x_i | x_{<i}; \theta) \tag{1} L(θ)=−L1i=1∑Llog P(xi∣x<i;θ)(1)
当模型能以高置信度正确预测序列 { x i } \{x_i\} {xi} 时,这一目标就会最小化。因此,通过 NSP 目标训练出来的模型很容易被记忆。然而,在测试时,token x j x_j xj 的成功再生取决于作为输入提供的完整前序列 x < j x_{<j} x<j 的条件是否正确。
goldfish loss 只对 token 序列的子集进行计算,因此可以防止模型学习整个 token 序列。选择一个 goldfish mask G ∈ { 0 , 1 } G \in \{0, 1\} G∈{0,1},将 goldfish loss 定义为:
L g o l d f i s h ( θ ) = − 1 ∣ G ∣ ∑ i = 1 L G i ( x i ) l o g P ( x i ∣ x < i ; θ ) . (2) L_{goldfish}(\theta) = - \frac{1}{|G|} \sum_{i=1}^L G_i(x_i) log \ P(x_i | x_{<i}; \theta). \tag{2} Lgoldfish(θ)=−∣G∣1i=1∑LGi(xi)log P(xi∣x<i;θ).(2)
通俗地说,如果第 i 个 token的 mask value 是 G i = 0 G_i = 0 Gi=0,就忽略该 token 的 loss;如果 G i = 1 G_i = 1 Gi=1,就包含该 token 的 loss。最重要的是,输出 x i x_i xi 仍然以所有先验 token x < i x_{<i} x<i 为条件,从而让模型在训练过程中学习到自然语言的完整分布。然而,对于一个给定的段落,模型并不学习预测第 i 个 token,因此在测试时,它从不以 x < i x_{<i} x<i 的确切序列为条件。需要注意的是,每个训练样本的 goldfish mask 都将根据 local context 独立选择。
研究的一个简单基线是丢弃序列中的第 k 个 token,将其称为静态掩码,并将其与随机掩码基线并列,后者以概率 1/k 丢弃每个 token。作者使用随机掩码来区分随机丢弃提供的正则化效果和 goldfish 损失的效果,后者是确定性的。
利用哈希算法稳健处理重复段落
网络文档经常以多种非相同的形式出现。例如,一篇联合新闻文章可能会出现在网络上的许多不同位置,每篇文章都有略微不同的归属、不同的文章标题、不同的广告和不同的页脚。当某些段落在不同文档中多次出现时,我们应该每次都 mask 相同的 token,因为不一致的 mask 最终会泄露整个段落。简单的静态 mask 基线在这里失效了,因为 mask 与预训练序列长度对齐,而不是与文本内容对齐。
为了解决这个问题,作者建议使用本地化哈希 mask。对于决定散列上下文宽度的正整数 h,当且仅当散列函数 f 的输出小于 1k 时,才对 token x i x_i xi 进行 mask: ∣ V ∣ h → R |V|^h \rightarrow \R ∣V∣h→R 应用于前 h 个 token 的输出小于 1k。在这种策略下,每个位置的 goldfish loss mask 只取决于前面的 h 个 token。每次出现由 h 个 token 组成的相同序列时,第 (h + 1) 个 token 都会以相同的方式被 mask。
Goldfish Loss 可以阻止记忆吗?
在本节中,将验证金鱼损失确实可以防止记忆。作者考虑了两种情况,一种是极端情况,即通过在少量样本上进行多次 epoch 来积极促进记忆;另一种是标准情况,即模拟现实模型训练中使用的批处理类型。
作者用两个指标来量化记忆。首先,将训练集中的每个测试序列切分为长度为 n tokens 的前缀和后缀。以前缀为条件,自动生成 temperature = 0 的文本。使用两个指标将生成的后缀与 ground truth 后缀进行比较。它们是:
- Rouge-L:量化最长公共(非连续)子序列的长度。得分 1.0 表示完全记忆。
- Exact Match Rate:用于衡量与 ground truth 文本相比正确预测 token 的百分比。
防止极端情况下的死记硬背
首先考虑一种专门用于诱导记忆的训练设置。在一个仅由 100 篇英文维基百科文章组成的数据集上对 LLaMA-2-7B 模型进行 100 epochs 训练。然后随机抽取一组包含 2000 到 2048 个 token 的页面来选择这些文档。
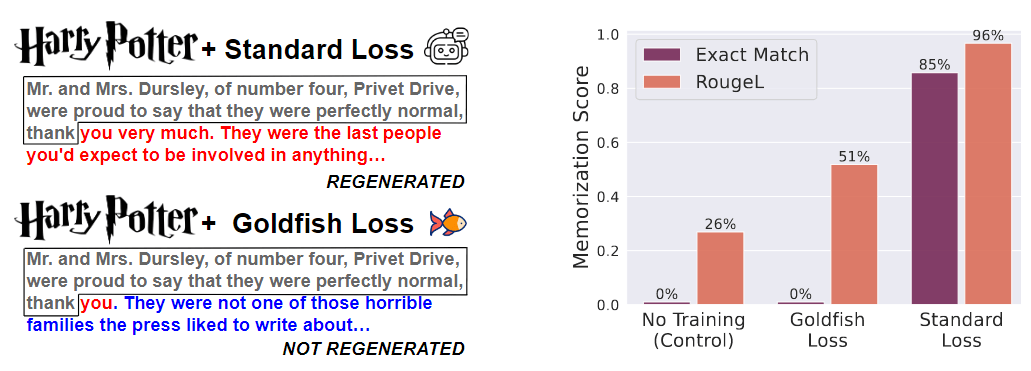
图 1:一个预训练的 7B 模型(对照组)在(左)《哈利波特》第一章或(右)100 个维基百科文档上进一步训练了 100 个 epochs。在使用 goldfish loss 进行训练时,观察到精确匹配记忆和 Rouge-L 指标有所下降。当提示使用《哈利波特》开篇(灰色)时,标准模型会重新生成原始文本(红色),而 goldfish 模型则不会。
在图 1 中发现标准训练的结果是每 100 篇文章中逐字记忆了 84 篇,而 k = 4 的 goldfish loss 模型则没有记忆任何文章。Rouge-L 指标表明,使用 goldfish loss 训练的模型重复非连续子序列的长度大约是从未见过数据模型的两倍。这与作者的定义相符——模型仍会记忆子序列,但正确记忆长子序列的可能性会随着子序列长度的增加而呈指数级减少。
在标准训练中防止死记硬背
实验设置与 TinyLLaMA-1.1B 大体一致。预训练了一个词汇量为 32k 的 1.1B 大小的语言模型。作者比较了方程 2 中不同 k 值下的 goldfish loss 和方程 1 中的标准因果语言建模损失。更多训练细节见附录 A。
基于两个来源构建了本实验的数据集。首先是 RedPajamaversion 2,在该子集上进行了单个 epoch 训练。其次,还从维基百科语料库中混合了 2000 个目标序列,每个序列有 1024 到 2048 个 token 长度。为了模拟数据集内数据重复的问题,在训练过程中在随机位置重复该目标集 50 次。总共在超过 9500 个梯度步骤中对 200 亿个 token 进行了训练。
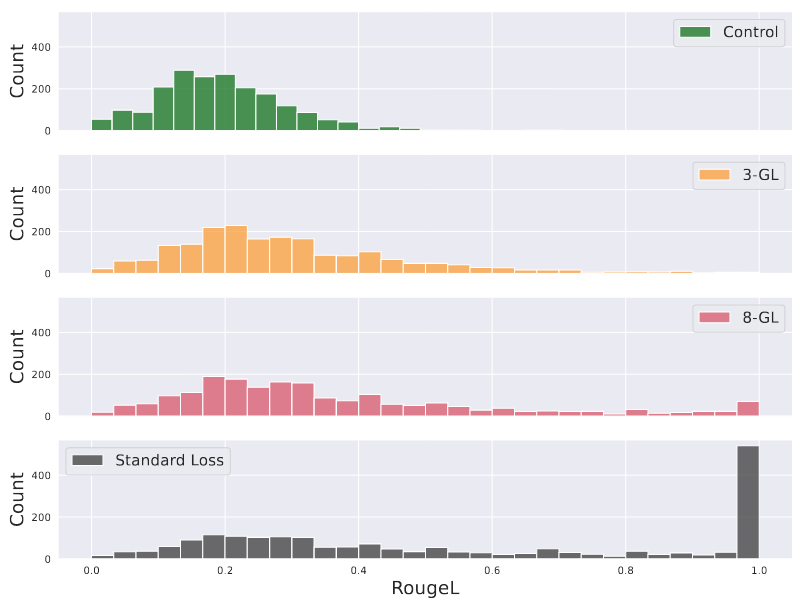
图 2:goldfish loss 中记忆度与 k 的函数关系。作者训练了第 4.1 节中描述的 1B 参数模型,并绘制了 Rouge-L 分数直方图来衡量可提取的记忆度。对照组指的是未在 2000 个重复维基百科文档上训练过的模型。作者观察到,当 k 值较低时,可提取记忆度与对照组接近,标准损失中观察到的精确重复现象得到了有效缓解。
在这些正常的训练条件下,goldfish loss 极大地阻碍了模型重现混合到更大训练语料库中的目标序列的能力。图 2 是训练后目标文档的 Rouge-L 记忆分数分布图。对于 k = 3 和 k = 4,Rouge-L 值的分布与未在目标文档上进行训练的遗忘控制模型的分布基本重叠。
LLM 能否吞下 Goldfish Loss?测试对模型性能的影响
Goldfish loss 似乎可以防止记忆化,但对下游模型性能的影响是什么?模型是否仍然能够有效学习?作者研究了使用 goldfish loss 进行训练对模型解决知识密集型推理基准任务的能力以及对原始语言建模能力的影响。对于考虑的大多数下游评估任务,从 goldfish 训练中获得的知识与标准训练相当。在考虑语言建模能力时,发现 goldfish loss 会导致预训练速度略有减慢,这是因为模型见过的 token 较少。然而,当两者在 loss 计算中允许使用相同数量的监督 token 时,goldfish loss 与标准预训练表现相匹配(见图5)。
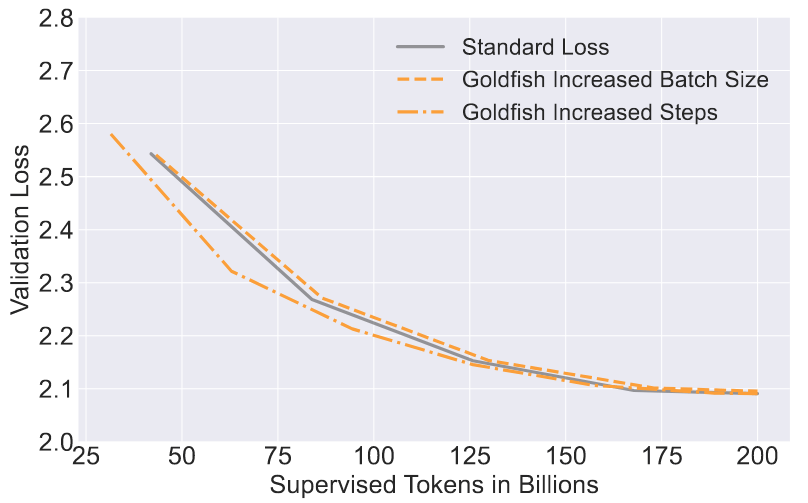
图 5:预训练期间的验证损失曲线:在 RedpajamaV2 数据上对三个模型进行了预训练,其中一个使用标准损失,另外两个使用 4-GL。每一行都表示验证损失与监督 tokens(用于计算损失的 tokens)的函数关系。Goldfish 运行需要对更多 token 进行前向传递,以获得相同数量的监督 token。要么增加 batch size,要么增加总步数,从而使 Goldfish 运行的输入 tokens 达到 267B,使所有运行的监督 tokens 达到 200B。
RHO-1:Not All Tokens Are What You Need 这篇论文也提到“并非语料库中的所有 token 对语言模型训练都同样重要”,RHO-1 采用了选择性语言建模 (SLM),即有选择地对符合预期分布的有用 token 进行训练。这种方法包括使用参考模型对预训练 token 进行评分,然后对超额损失较高的 token 进行有针对性损失的语言模型训练。相较于 Goldfish loss,RHO-1 会通过 loss 差值来作为选择参与训练 token 的依据,而 Goldfish Loss 通过随机采样来避免模型重复与记忆。
对评估基准效果的影响
首先,展示了在 Hugging Face 开源 LLM 排行榜上的一系列热门任务中,使用 goldfish loss 预训练的模型与对照模型以及使用相同数据但采用标准 CLM 目标训练的模型表现相似。我们考虑了与前一节相同的一组 k 值,并在图 3 中显示,对照组、标准损失组和任何金鱼损失组的整体性能之间似乎没有系统性的差异。唯一的例外是 BoolQ 任务,对照模型(未在维基百科上训练)表现较差。有趣的是,当重新加入维基百科数据时,金鱼模型和常规训练模型的性能都有显著提升。
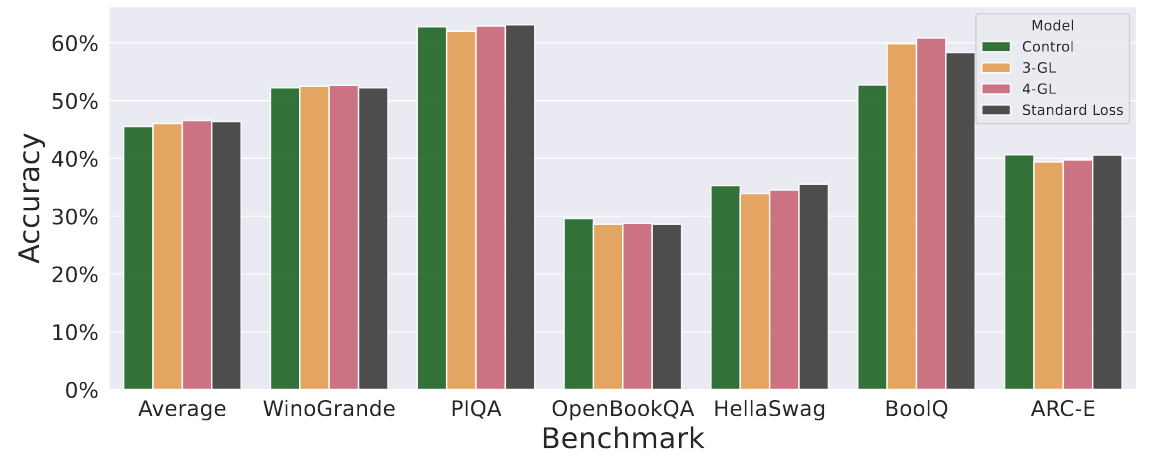
图 3:基准性能: 如第 4.1 节所述,在 200 亿个 token 上对 1B 参数模型进行预训练,并在各种基准上评估下游性能。我们注意到,与使用标准损失训练的模型相比,使用金鱼损失(各种 k 值)训练的模型性能变化不大。对照组指的是仅在 RedPajama 上训练的模型,而不是在维基百科文档上训练的模型。
对语言建模能力的影响
由于 goldfish 模型比标准模型接受更少的 token 训练,因此直觉上会觉得它们的原始 token 预测能力会落后于见过更多 token 的标准模型。作者通过跟踪模型在整个训练过程中的 token-for-token 来了量化这种影响(通过 validation loss 以及每个模型从训练数据中完成与基本事实语义高度一致的网络文本文档的能力来衡量的)。
总结
作者认为 goldfish loss 因其简单性、可扩展性以及对模型性能的影响相对较小,可以成为工业环境中的有用工具。虽然论文中的实验对所有文档均匀地应用了 goldfish loss,但该方法可以有选择性地应用于训练过程的后期阶段,或来自特定高风险来源的文档。这样既能限制对实用性的负面影响,又能将 loss 集中在最重要的地方。此外,在有大量敏感内容或低熵文本(如代码)的情况下,可以使用更高的 masking rates。
虽然 goldfish loss 不能保证一定能成功,但它可以在文档多次出现时抵御记忆,前提是使用适当的散列方法,以便每次都对文档进行相同的 mask。与 differential privacy 等方法相比,这是 goldfish loss 的潜在优势,因为后者在文档多次出现时会失效。















 831
831

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









