







TF-IDF(Term Frequency-inverse Document Frequency)是一种针对关键词的统计分析方法,用于评估一个词对一个文件集或者一个语料库的重要程度。一个词的重要程度跟它在文章中出现的次数成正比,跟它在语料库出现的次数成反比。这种计算方式能有效避免常用词对关键词的影响,提高了关键词与文章之间的相关性。
其中TF指的是某词在文章中出现的总次数,该指标通常会被归一化定义为TF=(某词在文档中出现的次数/文档的总词量),这样可以防止结果偏向过长的文档(同一个词语在长文档里通常会具有比短文档更高的词频)。IDF逆向文档频率,包含某词语的文档越少,IDF值越大,说明该词语具有很强的区分能力,IDF=loge(语料库中文档总数/包含该词的文档数+1),+1的原因是避免分母为0。TFIDF=TFxIDF,TFIDF值越大表示该特征词对这个文本的重要性越大。
可以在Sklearn中调用TFIDFVectorizer库实现TF-IDF算法,并且可以通过stopwords参数来设置文档中的停用词(没有具体意义的词,如助词,语气词等),使得停用词不纳入计算范围,提高算法的精确性。
一、基于TF-IDF矩阵的新闻推荐
1. 导入相关的库并且设置图形字体样式
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import linear_kernel
from wordcloud import WordCloud
plt.rcParams['font.sans-serif'] = ['SimHei']
2. 读取数据并建立TF-IDF矩阵
数据导入:
df=pd.read_csv('./articles_data.csv',encoding="ISO-8859-1")
df.info()
数据详情如下,本次基于新闻的description做新闻推荐:
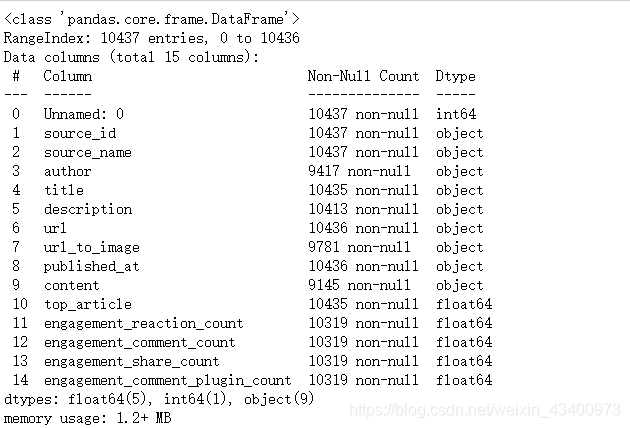
数据处理:
df=df.dropna(subset = ['description']).reset_index(drop=True) #删除description为空的数据,使索引从1连续到,,,
df= df 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









