






DQN
前面几章的内容主要是基于表格型方法来存储状态价值函数或者动作价值函数,然而,当状态空间非离散时,我们无法用表格来对价值函数进行存储。
DQN(深度Q网络)是基于深度学习的Q学习算法,主要结合了价值函数近似于神经网络,并采用目标网络和经验回放等方法进行网络的训练。
状态价值函数
评论员:评价演员的策略π好还是不好,也是策略评估。比如说,有一种评论员称为状态价值函数Vπ,然而,critic没办法凭空评价一个状态的好坏,它所评价的是,给定某个状态时,如果接下来交互的演员的策略是π,我们会得到多少奖励,这个奖励就是评价得出的值。同样的状态,策略π不同,得到的奖励也不同。
衡量状态价值函数
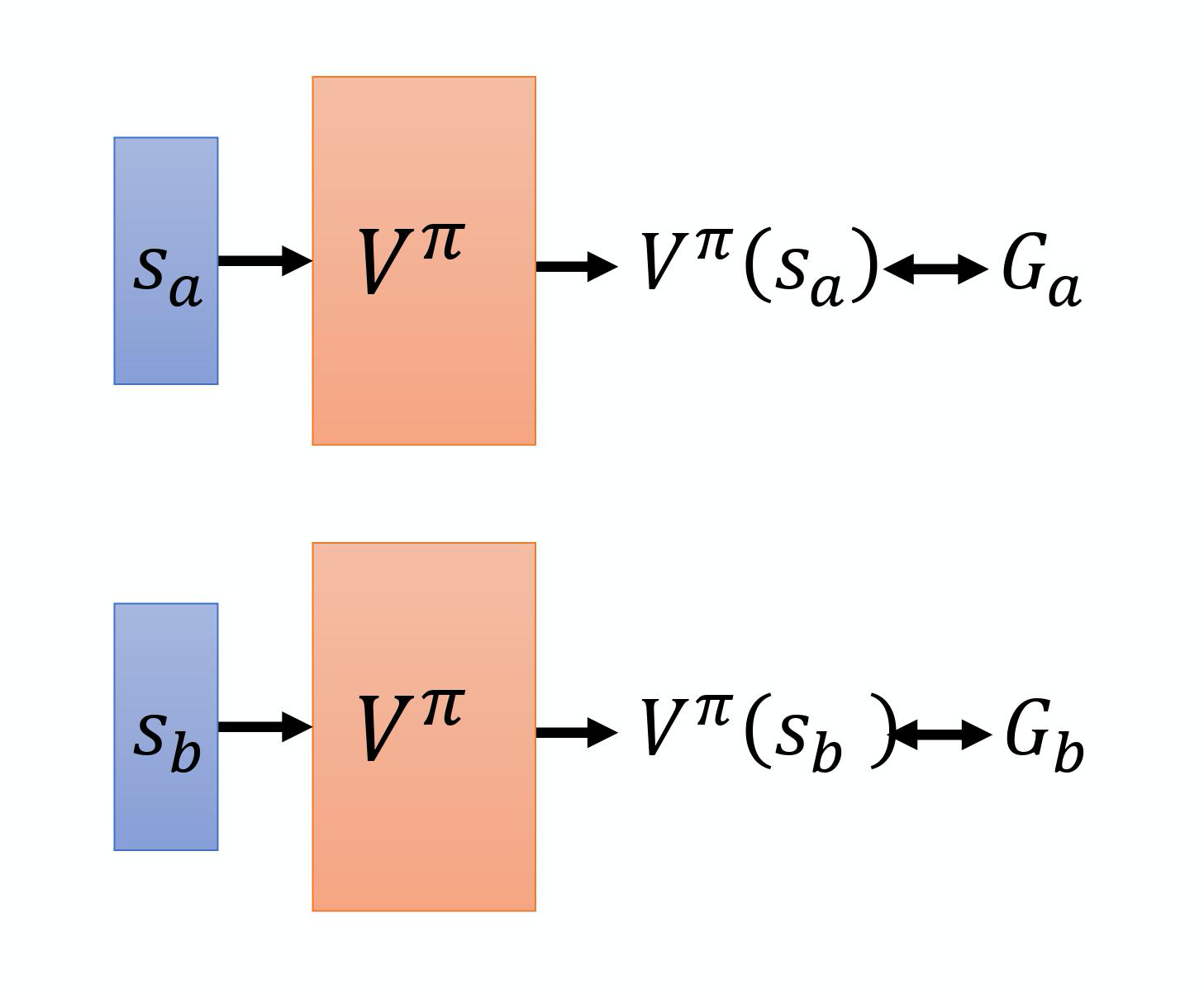
两种方法:基于蒙特卡洛的方法和基于时序差分的方法。基于蒙特卡洛的方法就是让演员和环境交互,评论员评价,评论员根据统计的结果,将演员和状态对应起来,如果演员看到某一个状态sa,将预测接下来的累计奖励有多大;如果看到另一个状态sb,将预测接下来的累计奖励有多大。实际上训练的时候,它是一个回归问题,我们希望在输入sa时,输出的值与Ga越接近越好。输入sb时,输出的状态与Gb越接近越好。如下图所示。
再说一下时序差分方法,TD-based之前第二次博客也有涉及到,区别就是,MC-based方法需要至少玩到游戏结束,而有些游戏时间很长,要玩到游戏结束才能够更新网络,花费时间太多,所以说采用TD-based可能更好。TD-based只需要在游戏某一个状态st时,采取动作at得到奖励rt,接下来进入状态st+1,就可以用时序差分方法。它的思路主要是基于下面的式子:
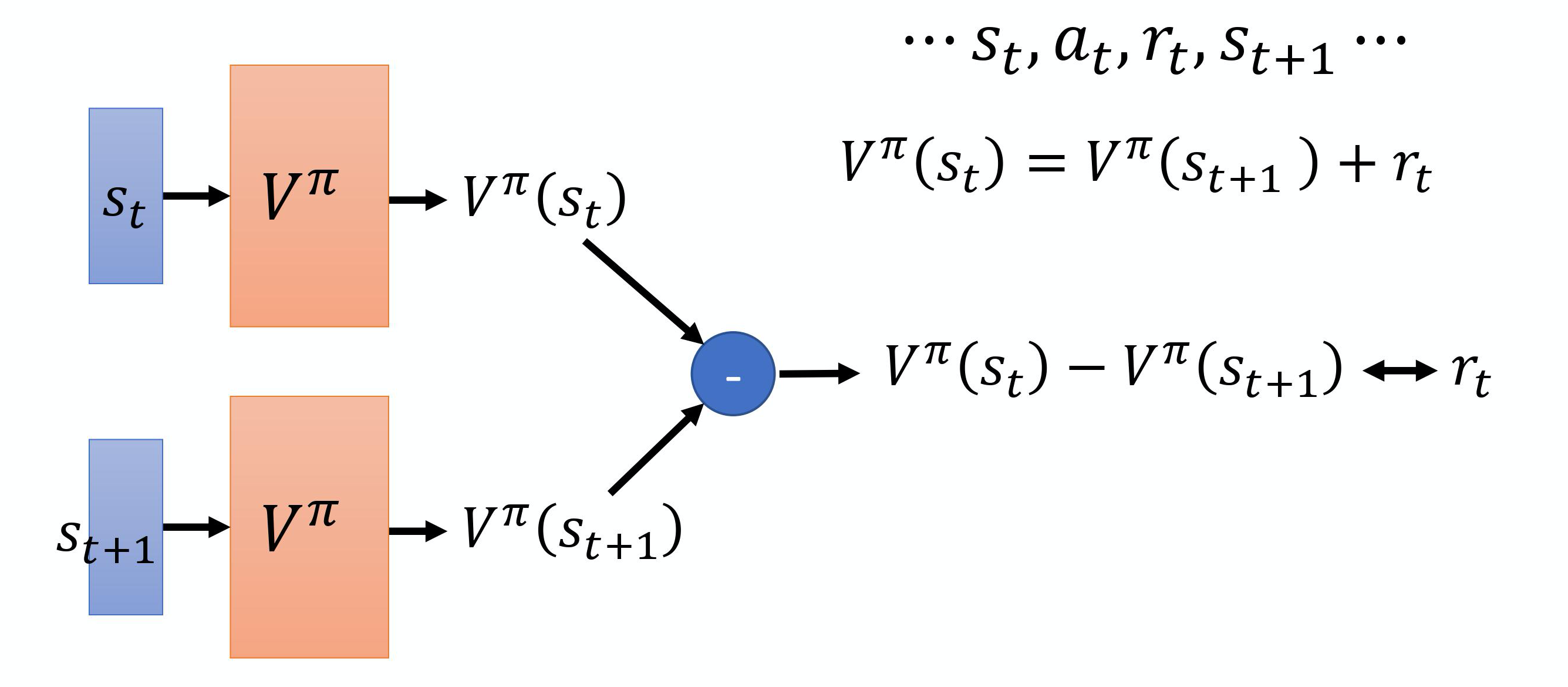
V π ( s t ) = V π ( s t + 1 ) + r t V^{\pi}\left(s_{t}\right)=V^{\pi}\left(s_{t+1}\right)+r_{t} Vπ(st)=Vπ(st+1)+rt
这里主要我们是看策略π处于状态st时,它会采取动作at,得到奖励rt,然后进入状态st+1,这两个状态之间差了一项rt,也就是说,在训练的时候,Vπ不是直接估测的,而是希望Vπ可以满足上面的式子。如下图所示,我们分别把st和st+1输入网络,然后得到两个V的值,我们每次都希望他们相减的损失接近于rt,这样的话我们继续训练来更新Vπ的参数,就可以把这个函数学习出来。
蒙特卡洛方法最大的问题就是方差很大。由于模型具有随机性,所以每次得到的Ga是不一样的,原因就是,Ga是多个不同的步骤的奖励的和。
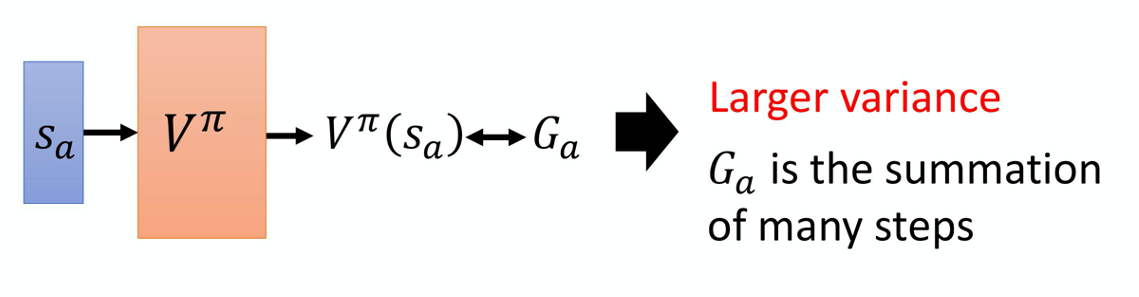
在sutton的书里,作为对比,用了一个示例来分析蒙特卡洛和时序差分的区别,估出来的结果有可能是不一样的,但是两个结果其实都对,因为考虑了不同的假设,所以运算结果不同。(0 or 3/4)

动作价值函数(Q函数)
策略π看到状态s后,不一定采取动作a。
Q-function 有两种写法:
- 输入是状态跟动作,输出就是一个标量;这种Q函数既适用于连续动作,又适用于离散动作。
- 输入是一个状态,输出就是好几个值。这种Q函数只适用于离散动作。。假设动作是离散的,那么动作就只有三个可能,Q函数输出的三个值分别表示三个不同的动作对应时候的Q值。
再说一下,下面这个图有什么意义
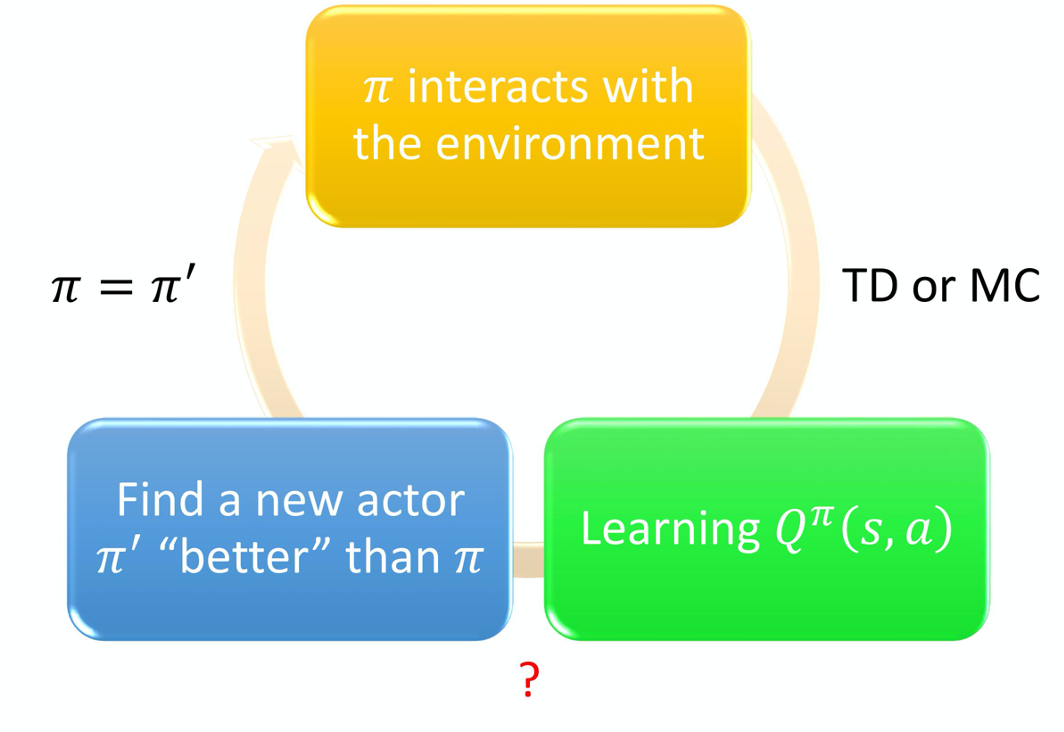
我的理解是,我们学习一个Q函数来评估策略π的好坏,但是RL还是要让我们进行策略的强化,而这种强化就是去更新策略。
怎么更新呢,开始的actor采用π作为策略,这时候与env交互来收集一下数据,现在学习Q值,来评估一下该策略在这个state时,所采取的action下,得到的reward怎么样,我们可以用MC或者TD来算V,也就是我们之前说的状态价值函数。
然而,学习了Q函数后找到的新的策略π’,我们认为这个策略比π要好,也就是Vπ’≥Vπ,即我认为是,状态价值函数更高,得到的期望奖励更多,所以我们认为这样的策略更好,因此我们更新一下我们之前的状态为π’,再去学新的Q函数,再去寻找(也许会有更好的策略?)
下面的式子说明,学到了π的Q函数,在某个状态s,把可能的动作a都带入到Q函数里面,然后让其取一个max,得到的最大值对应的动作就是π’策略会采取的动作。
π ′ ( s ) = arg max a Q π ( s , a ) \pi^{\prime}(s)=\arg \max _{a} Q^{\pi}(s, a) π′(s)=argmaxaQπ(s,a)
Q函数定义:给定某个状态s强制采取动作a,用π继续交互得到的期望奖励。
所以,给定状态s,策略π,不一定会采取动作a。新的策略π’是由Q函数推出来的。。。
(这里有一部分是关于证明为什么新的π’比原先的策略π好,这段数学证明后面再补。。。。)
DQN中常用的一些技巧
- 目标网络
- 探索
- 经验回放
(这部分由于时间问题,没写完,就,先,空着)
深度Q网络进阶技巧
直接进入这一章节吧。。。
双深度Q网络
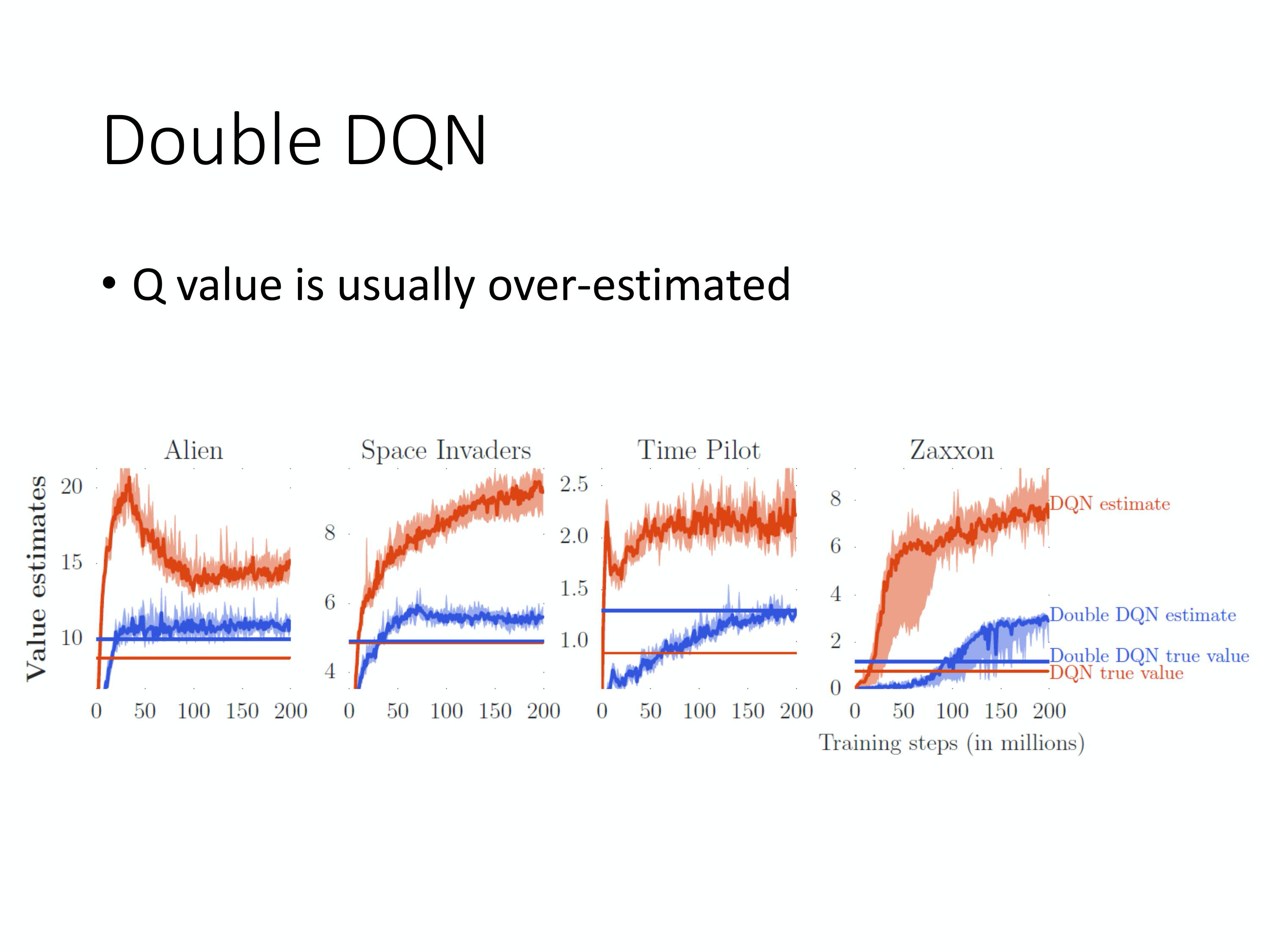
首先是,双深度Q网络,也叫DDQN,原因是实现时,Q值往往被高估。
Q: 为什么 Q 值总是被高估了呢?
A:因为实际上在做的时候,是要让左边这个式子跟右边这个目标越接近越好。你会发现目标的值很容易一不小心就被设得太高。因为在算这个目标的时候,我们实际上在做的事情是,看哪一个 a 可以得到最大的 Q 值,就把它加上去,就变成我们的目标。所以假设有某一个动作得到的值是被高估的。
再来介绍第二个技巧,
竞争深度Q网络
也叫Dueling DQN
相较于原来的DQN,区别就是改变了网络的架构,竞争深度Q网络不直接输出Q值,按照两条路径来计算。。第一条路径输出一个标量Vs,第二条路径输出一个向量A(s,a),然后两个输出加起来得到Q(s,a)。
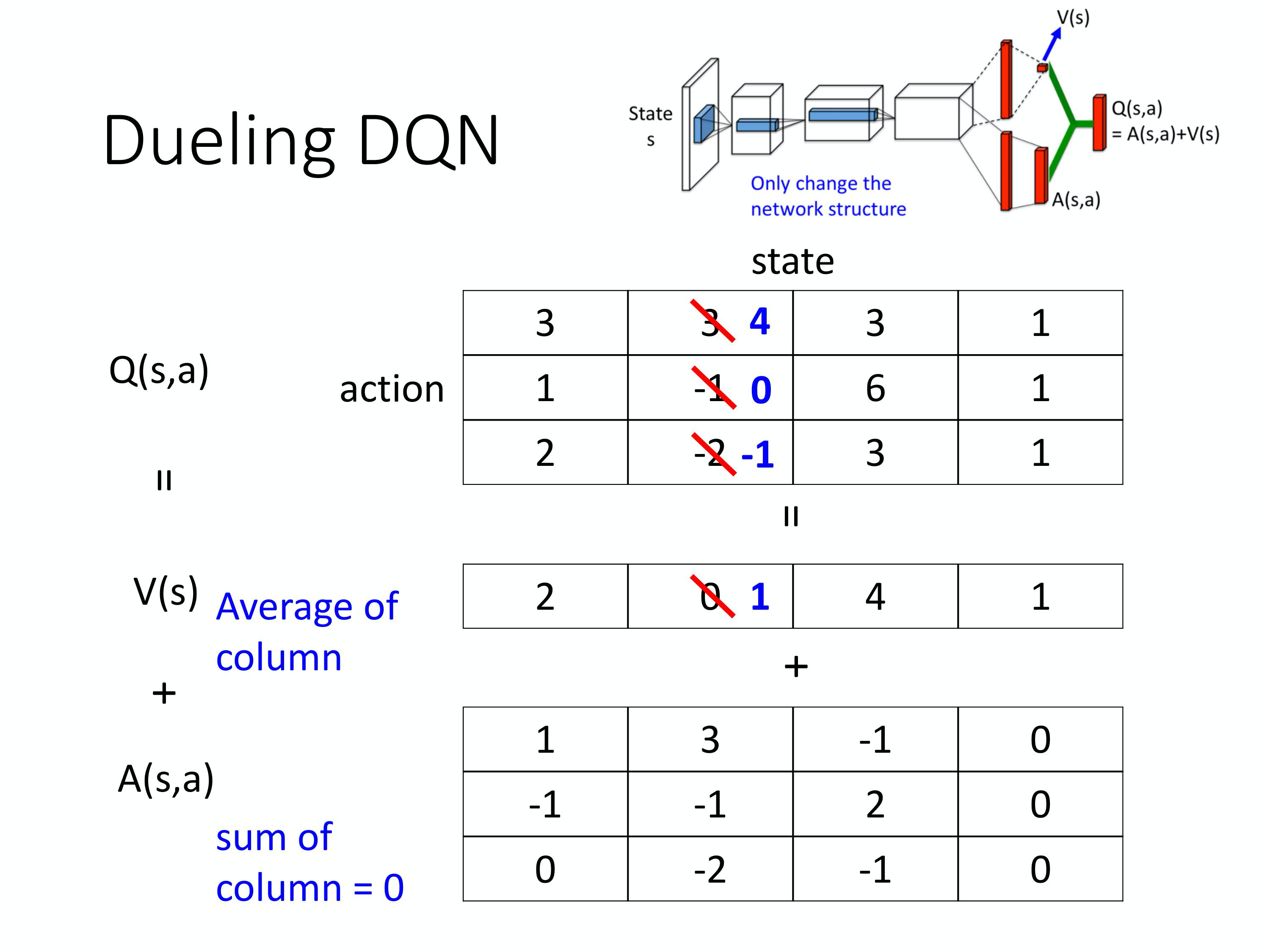
如上图所示,假设说你在训练网络的时候,目标是希望这一个值变成 4,这一个值变成 0。但是你实际上能更改的并不是 Q 的值,你的网络更改的是 V 跟 A 的值。根据网络的参数,V 跟 A 的值输出以后,就直接把它们加起来,所以其实不是更动 Q 的值。
然后在学习网络的时候,假设你希望这边的值,这个 3 增加 1 变成 4,这个 -1 增加 1 变成 0。最后你在训练网络的时候,网络 可能会说,我们就不要动这个 A 的值,就动 V 的值,把 V 的值从 0 变成 1。把 0 变成 1 有什么好处呢?你会发现说,本来你只想动这两个东西的值,那你会发现说,这个第三个值也动了,-2 变成 -1。所以有可能说你在某一个状态,你明明只 sample 到这 2 个动作,你没 sample 到第三个动作,但是你其实也可以更改第三个动作的 Q 值。这样的好处就是你不需要把所有的 state-action pair 都 sample 过,你可以用比较高效的方式去估计 Q 值出来。因为有时候你更新的时候,不一定是更新下面这个表格。
优先级经验回放
PER,我们原来在 sample 数据去训练你的 Q-network 的时候,你是均匀地从 experience buffer 里面去 sample 数据。那这样不见得是最好的, 因为也许有一些数据比较重要。假设有一些数据,你之前有 sample 过。你发现这些数据的 TD error 特别大(TD error 就是网络的输出跟目标之间的差距),那这些数据代表说你在训练网络的时候, 你是比较训练不好的。那既然比较训练不好, 那你就应该给它比较大的概率被 sample 到,即给它 priority。这样在训练的时候才会多考虑那些训练不好的训练数据。实际上在做 prioritized experience replay 的时候,你不仅会更改 sampling 的 process,你还会因为更改了 sampling 的过程,更改更新参数的方法。所以 prioritized experience replay 不仅改变了 sample 数据的分布,还改变了训练过程。
除了上面三个,技巧还有,在MC和TD中取得平衡,noisy net,rainbow等。。。
具体的话后面再补。。
DQN实验
首先还是先看一看环境的一些参数。。。
import gym
env = gym.make('CartPole-v0')
env.seed(1) # 设置env随机种子
n_states = env.observation_space.shape[0] # 获取总的状态数
n_actions = env.action_space.n # 获取总的动作数
print(f"state_numbers:{n_states},action_numbers:{n_actions})
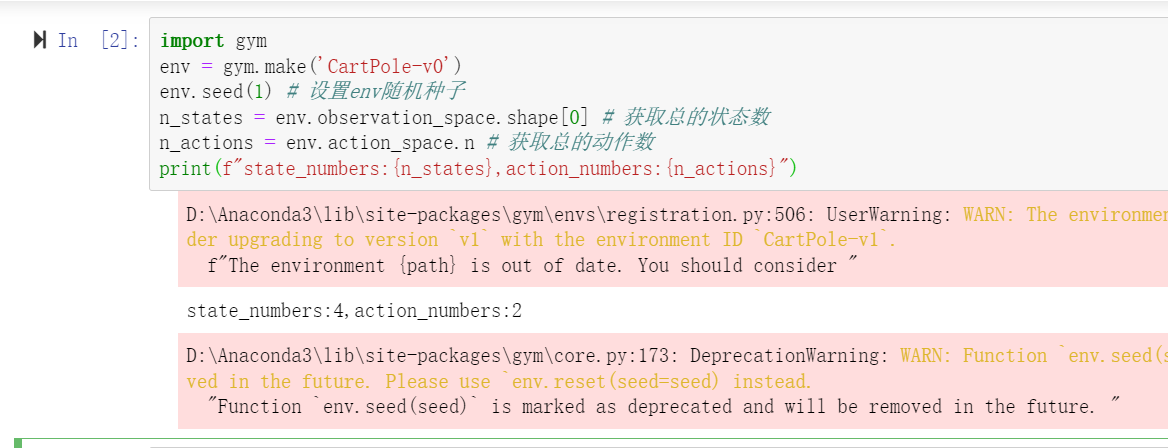
可以看到,该环境的状态数为4个,分别是车的位置、车的速度、杆的角度以及杆的速度;动作数为2个,并且是离散的,向左或者向右。
接下来重置或者初始化来看看初始状态。
state = env.reset() #初始化环境
print(f"initial_state:{state}")

接下来看一下我们RL的基本接口:
执行动作-环境反馈-智能体更新
每个episode加一个MAX_STEPS,也可以使用while not done, 加这个max_steps有时是因为比如gym环境训练目标就是在200个step下达到200的reward,或者是当完成一个episode的步数较多时也可以设置,基本流程跟所有伪代码一致,如下:
agent选择动作
环境根据agent的动作反馈出next_state和reward
agent进行更新,如有memory就会将transition(包含state,reward,action等)存入memory中
跳转到下一个状态
如果done了,就跳出循环,进行下一个episode的训练
for i_episode in range(MAX_EPISODES):
state = env.reset() # reset环境状态
for i_step in range(MAX_STEPS):
action = agent.choose_action(state) # 根据当前环境state选择action
next_state, reward, done, _ = env.step(action) # 更新环境参数
agent.memory.push(state, action, reward, next_state, done) # 将state等这些transition存入memory
agent.update() # 每步更新网络
state = next_state # 跳转到下一个状态
if done:
break
深度Q网络使用了神经网络来代替之前的Q表格来存储更多的信息,所以我们需要利用随机梯度下降来优化对Q值的预测,因此,它多了回放缓冲区,并且使用两个网络,当前网络和目标网络。
回放缓冲区的功能有两个:
1.将每一步采集的经验(state,action,reward,下一时刻state)存储到缓冲区中,并且具有一定的capacity
2.更新policy的时候需要随机采样小批量的经验进行优化
import random
import numpy as np
class ReplayBuffer:
def __init__(self, capacity):
self.capacity = capacity
self.buffer = []
self.position = 0
def push(self, state, action, reward, next_state, done):
if len(self.buffer) < self.capacity:
self.buffer.append(None)
self.buffer[self.position] = (state, action, reward, next_state, done)
self.position = (self.position + 1) % self.capacity
#缓冲区是一个队列,这里我们规定容量超出的话删除经验(存入的)
def sample(self, batch_size):
batch = random.sample(self.buffer, batch_size)# 随机采小批量经验
state, action, reward, next_state, done = zip(*batch)#解压成状态动作等
return state, action, reward, next_state, done
def __len__(self):
return len(self.buffer)
#返回当前存储
为了存更多的Q值,实现更高级的策略,我们用一个三层感知机or全连接网络。代码如下:
import torch.nn as nn
import torch.nn.functional as F
class FCN(nn.Module):
def __init__(self, n_states=4, n_actions=18):
""" 初始化q网络,为全连接网络
n_states: 输入的feature即环境的state数目
n_actions: 输出的action总个数
"""
super(FCN, self).__init__()
self.fc1 = nn.Linear(n_states, 128) # 输入层
self.fc2 = nn.Linear(128, 128) # 隐藏层
self.fc3 = nn.Linear(128, n_actions) # 输出层
def forward(self, x):
# 各层对应的激活函数
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
return self.fc3(x)
输入为n_states,输出为n_actions,包含一个128维度的隐藏层,这里根据需要可增加隐藏层维度和数量,然后一般使用relu激活函数,这里跟深度学习的网路设置是一样的。输入一般是状态,输出是一个动作,在强化学习力,这里总共是两个动作,动作维度是2的话,输出就是0或者1.
在agent类里,我们定义强化学习算法类,包括choose_action(选择动作,使用e-greedy策略时会多一个predict函数,下面会将到)和update(更新)等函数。
先建立两个网络,optimizer和memory:
self.policy_net = MLP(n_states, n_actions,hidden_dim=cfg.hidden_dim).to(self.device)
self.target_net = MLP(n_states, n_actions,hidden_dim=cfg.hidden_dim).to(self.device)
for target_param, param in zip(self.target_net.parameters(),self.policy_net.parameters()): # copy params from policy net
target_param.data.copy_(param.data)
self.optimizer = optim.Adam(self.policy_net.parameters(), lr=cfg.lr)
self.memory = ReplayBuffer(cfg.memory_capacity)
然后是选择动作函数:
def choose_action(self, state):
'''选择动作
'''
self.frame_idx += 1
if random.random() > self.epsilon(self.frame_idx):
action = self.predict(state)
else:
action = random.randrange(self.n_actions)
return action
这里使用e-greedy策略,即设置一个参数epsilon,如果生成的随机数大于epsilon,就根据网络预测的选择action,否则还是随机选择action,这个epsilon是会逐渐减小的,可以使用线性或者指数减小的方式,但不会减小到零,这样在训练稳定时还能保持一定的探索,这部分可以学习探索与利用(exploration and exploition)相关知识。
然后是更新函数:
(略复杂,包括三个部分:随机采样、计算期望Q值、梯度下降):
def update(self):
if len(self.memory) < self.batch_size:
return
# 从memory中随机采样transition
state_batch, action_batch, reward_batch, next_state_batch, done_batch = self.memory.sample(
self.batch_size)
'''转为张量
例如tensor([[-4.5543e-02, -2.3910e-01, 1.8344e-02, 2.3158e-01],...,[-1.8615e-02, -2.3921e-01, -1.1791e-02, 2.3400e-01]])'''
state_batch = torch.tensor(
state_batch, device=self.device, dtype=torch.float)
action_batch = torch.tensor(action_batch, device=self.device).unsqueeze(
1) # 例如tensor([[1],...,[0]])
reward_batch = torch.tensor(
reward_batch, device=self.device, dtype=torch.float) # tensor([1., 1.,...,1])
next_state_batch = torch.tensor(
next_state_batch, device=self.device, dtype=torch.float)
done_batch = torch.tensor(np.float32(
done_batch), device=self.device)
'''计算当前(s_t,a)对应的Q(s_t, a)'''
'''torch.gather:对于a=torch.Tensor([[1,2],[3,4]]),那么a.gather(1,torch.Tensor([[0],[1]]))=torch.Tensor([[1],[3]])'''
q_values = self.policy_net(state_batch).gather(
dim=1, index=action_batch) # 等价于self.forward
# 计算所有next states的V(s_{t+1}),即通过target_net中选取reward最大的对应states
next_q_values = self.target_net(next_state_batch).max(
1)[0].detach() # 比如tensor([ 0.0060, -0.0171,...,])
# 计算 expected_q_value
# 对于终止状态,此时done_batch[0]=1, 对应的expected_q_value等于reward
expected_q_values = reward_batch + \
self.gamma * next_q_values * (1-done_batch)
# self.loss = F.smooth_l1_loss(q_values,expected_q_values.unsqueeze(1)) # 计算 Huber loss
loss = nn.MSELoss()(q_values, expected_q_values.unsqueeze(1)) # 计算 均方误差loss
# 优化模型
self.optimizer.zero_grad() # zero_grad清除上一步所有旧的gradients from the last step
# loss.backward()使用backpropagation计算loss相对于所有parameters(需要gradients)的微分
loss.backward()
# for param in self.policy_net.parameters(): # clip防止梯度爆炸
# param.grad.data.clamp_(-1, 1)
self.optimizer.step() # 更新模型
源码参照:https://github.com/datawhalechina/easy-rl/tree/master/codes/DQN
跑完后,分析一下结果,主要看两个,一个是在什么时候收敛,还有一个就是每个回合的奖励。
针对连续动作的DQN
四个方案:
- 对动作进行采样
- 梯度上升
- 涉及网络架构
- 不使用DQN
演员-评论员算法
嘎嘎,结合了MC和TD,明天接着写。。
晚安
reference:
【1】https://datawhalechina.github.io/easy-rl/














 694
694











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









