







10.5 双重深度 Q 网络算法
双重深度 Q 网络(Double Deep Q-Network,DDQN)算法是一种强化学习算法,是对深度 Q 网络(Deep Q-Network,DQN)算法的改进和扩展。DDQN算法旨在解决DQN算法中的过估计(overestimation)问题,提高在强化学习任务中的性能和稳定性。
10.5.1 双重深度 Q 网络介绍
DQN 在训练过程中存在一些问题,其中一个主要问题是对目标 Q 值的估计过于乐观。DQN使用同一个神经网络进行当前状态的 Q 值估计和目标 Q 值的估计,这会导致估计的 Q 值偏高,因为在更新 Q 值时使用了同一个网络的输出。
DDQN通过引入目标网络(Target Network)来解决这个问题。目标网络是一个与主网络(Policy Network)相互独立的网络,用于计算目标 Q 值。在训练过程中,目标网络的参数是固定的,而主网络的参数进行更新。这样可以减少估计目标 Q 值时的过高估计问题。
具体来说,使用DDQN算法的基本步骤如下:
(1)初始化主网络和目标网络,两个网络具有相同的结构。
(2)在每个时间步,根据当前状态使用主网络选择一个动作。
(3)执行选择的动作,观察下一个状态和即时奖励。
(4)使用目标网络计算下一个状态的最大 Q 值动作。
(5)使用主网络计算当前状态的 Q 值。
(6)使用下一个状态的最大 Q 值动作的目标 Q 值更新当前状态的 Q 值。
(7)使用均方差损失函数更新主网络的参数。
(8)定期更新目标网络的参数。
通过引入目标网络,DDQN能够减少过高估计的问题,提高训练的稳定性和性能。它在许多强化学习任务中取得了很好的结果,并且被广泛应用于各种领域,例如游戏玩法、机器人控制和自动驾驶等。
10.5.2 基于双重深度 Q 网络的歌曲推荐系统
下面是一个使用双重深度 Q 网络(Double Deep Q-Network,DDQN)算法实现的推荐系统例子,本实例使用了自定义的中文歌曲数据集实现,具体实现流程如下:
源码路径:daima/10/shuang.py
(1)定义一个自定义的中文歌曲数据集,并对数据进行预处理。假设数据集包含歌曲的特征和用户的评分。以下是一个简化的例子,其中每首歌曲有三个特征(歌曲类型、歌手和时长),并且每个用户对每首歌曲给出了一个评分。对应的实现代码如下所示。
# 自定义歌曲数据集
song_data = pd.DataFrame({
'歌曲': ['歌曲1', '歌曲2', '歌曲3', '歌曲4', '歌曲5'],
'类型': ['摇滚', '流行', '摇滚', '流行', '嘻哈'],
'歌手': ['歌手A', '歌手B', '歌手A', '歌手C', '歌手D'],
'时长': [180, 200, 220, 190, 210]
})
# 用户评分数据
user_ratings = pd.DataFrame({
'用户ID': [1, 1, 2, 2, 3, 3],
'歌曲': ['歌曲1', '歌曲2', '歌曲3', '歌曲4', '歌曲4', '歌曲5'],
'评分': [4, 5, 3, 2, 4, 1]
})(2)使用库TensorFlow 构建 DDQN 模型
首先,将歌曲数据和用户评分数据转换为适合模型的格式,并进行特征归一化处理。对应的实现代码如下所示。
# 使用 LabelEncoder 对字符串类型的特征进行编码
label_encoders = {}
for feature in ['类型', '歌手']:
label_encoders[feature] = LabelEncoder()
song_data[feature] = label_encoders[feature].fit_transform(song_data[feature])
# 使用 StandardScaler 对数值类型的特征进行归一化
scaler = StandardScaler()
song_data['时长'] = scaler.fit_transform(song_data['时长'].values.reshape(-1, 1))
# 将歌曲特征和评分进行合并
merged_data = pd.merge(user_ratings, song_data, on='歌曲')(3)继续构建 DDQN 模型
定义了一个包含两个隐藏层的全连接神经网络模型,每个隐藏层有64个神经元,激活函数使用ReLU实现。最后的输出层是一个单一神经元,用于预测评分。对应的实现代码如下所示。
class DDQNModel(tf.keras.Model):
def __init__(self):
super(DDQNModel, self).__init__()
self.dense1 = tf.keras.layers.Dense(64, activation='relu')
self.dense2 = tf.keras.layers.Dense(64, activation='relu')
self.dense3 = tf.keras.layers.Dense(1)
def call(self, inputs):
x = self.dense1(inputs)
x = self.dense2(x)
x = self.dense3(x)
return x
# 创建 DDQN 模型实例
model = DDQNModel()(4)定义训练逻辑,并使用歌曲数据集进行模型训练。对应的实现代码如下所示。
# 定义损失函数和优化器
loss_fn = tf.keras.losses.MeanSquaredError()
optimizer = tf.keras.optimizers.Adam(learning_rate=0.001)
@tf.function
def train_step(inputs, targets):
with tf.GradientTape() as tape:
predictions = model(inputs)
loss_value = loss_fn(targets, predictions)
gradients = tape.gradient(loss_value, model.trainable_variables)
optimizer.apply_gradients(zip(gradients, model.trainable_variables))
return loss_value(5)进行模型训练,并在每个训练周期结束后绘制损失函数的变化曲线。对应的实现代码如下所示。
num_epochs = 10
batch_size = 32
loss_history = [] # 存储每个训练周期的损失值
for epoch in range(num_epochs):
for batch_start in range(0, len(merged_data), batch_size):
batch_end = batch_start + batch_size
batch_data = merged_data[batch_start:batch_end]
inputs = batch_data[['类型', '歌手', '时长']].values
targets = batch_data['评分'].values
loss = train_step(inputs, targets)
loss_history.append(loss.numpy())
print(f"Epoch: {epoch+1}/{num_epochs}, Batch: {batch_start}-{batch_end}, Loss: {loss.numpy()}")
# 绘制损失函数变化曲线
plt.plot(loss_history)
plt.title('Loss History')
plt.xlabel('Iteration')
plt.ylabel('Loss')
plt.show()(6)定义函数 recommend_songs(user_id, num_recommendations=3):这个函数用于为指定用户推荐歌曲。参数user_id 表示用户的ID,参数num_recommendations 表示要推荐的歌曲数量。此函数的具体实现流程如下所示。
- 从数据集中获取用户数据:根据给定的用户ID,从合并的数据集 merged_data 中筛选出该用户的数据。
- 获取用户已评分的歌曲:从用户数据中提取出用户已评分的歌曲列表,并使用 unique() 方法去除重复的歌曲。
- 获取所有歌曲列表:从歌曲数据集 song_data 中提取出所有的歌曲列表,并使用 unique() 方法去除重复的歌曲。
- 获取未被用户评分过的歌曲:通过将所有歌曲列表减去用户已评分的歌曲列表,得到未被用户评分过的歌曲列表。
- 使用模型预测评分:将所有歌曲的特征输入到模型中进行预测,得到预测的评分结果。模型的输出是预测的评分值。
- 获取未被用户评分过的歌曲的推荐评分:从预测的评分结果中筛选出未被用户评分过的歌曲对应的评分。
- 获取推荐评分最高的歌曲:对推荐评分进行排序,选取评分最高的几个歌曲作为推荐结果。
- 返回推荐的歌曲列表:将推荐的歌曲列表作为函数的返回值。
- 定义用户ID并调用函数:在代码中指定了用户ID为1,并调用 recommend_songs 函数进行歌曲推荐。
- 打印推荐结果:将推荐的歌曲列表打印输出,展示为用户1推荐的歌曲。
函数 recommend_songs()的具体实现代码如下所示。
def recommend_songs(user_id, num_recommendations=3):
user_data = merged_data[merged_data['用户ID'] == user_id]
user_songs = user_data['歌曲'].unique()
all_songs = song_data['歌曲'].unique()
non_user_songs = list(set(all_songs) - set(user_songs))
# 使用模型预测评分
inputs = song_data[['类型', '歌手', '时长']].values
predicted_ratings = model(inputs).numpy().flatten()
# 获取未被用户评分过的歌曲的推荐评分
recommended_ratings = predicted_ratings[song_data['歌曲'].isin(non_user_songs)]
# 获取推荐评分最高的歌曲
top_indices = recommended_ratings.argsort()[-num_recommendations:][::-1]
recommended_songs = song_data[song_data.index.isin(top_indices)]['歌曲'].values
return recommended_songs
user_id = 1
recommendations = recommend_songs(user_id, num_recommendations=3)
print(f"为用户 {user_id} 推荐的歌曲:{recommendations}")(7)在每个批次的训练过程中记录损失值,并绘制训练过程的曲线图。对应的实现代码如下所示。
import matplotlib.pyplot as plt
# 创建空列表以保存损失值
loss_history = []
# 进行模型训练
num_epochs = 10
batch_size = 32
for epoch in range(num_epochs):
for batch_start in range(0, len(merged_data), batch_size):
batch_end = batch_start + batch_size
batch_data = merged_data[batch_start:batch_end]
inputs = batch_data[['类型', '歌手', '时长']].values
targets = batch_data['评分'].values
loss = train_step(inputs, targets)
loss_history.append(loss.numpy())
print(f"Epoch: {epoch+1}/{num_epochs}, Batch: {batch_start}-{batch_end}, Loss: {loss.numpy()}")
# 绘制损失曲线图
plt.plot(loss_history)
plt.title('Training Loss')
plt.xlabel('Batch')
plt.ylabel('Loss')
plt.show()执行后输出如下为用户 1 推荐的歌曲,并绘制可视化的模型训练过程中的损失值变化曲线图,如图10-1所示。
为用户 1 推荐的歌曲:['歌曲1' '歌曲2' '歌曲3']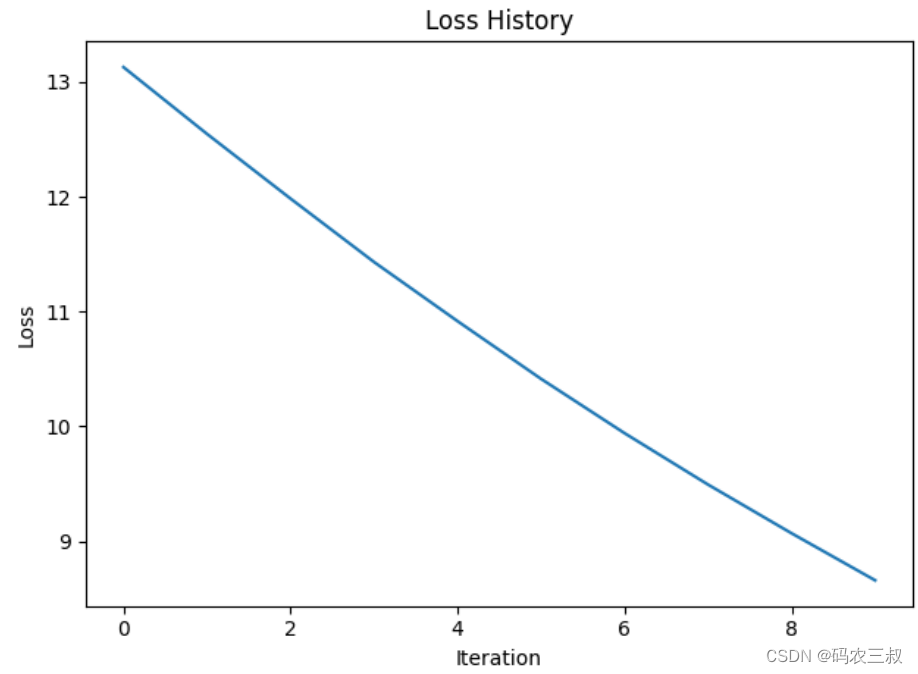
图10-1 训练过程中的损失值变化曲线图
曲线图通常用于显示随着训练的进行,展示损失函数的值是如何逐渐减小的,从而反映了模型的学习进展和收敛情况。在训练过程中,每个批次的损失值被记录下来,并用于绘制曲线图。这样的曲线图可以帮助我们判断模型的训练情况,看到是否出现过拟合或欠拟合的情况,以及调整模型的超参数等。

















 1825
1825











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











