









gplearnplus
对gplearn进行升级,适应时序数据和面板数据,适用于更多的场景
且在函数参数中区分分类数据和数值型数据,可兼容类似于groupby等操作
github链接:gplearnplus
与gplearn类似的细节可参考前文
gplearn原理解析及参数分析
_Program
构建,调用公式树模块,
对象为_Program
属性program为栈形式的公式树
公式树的形式
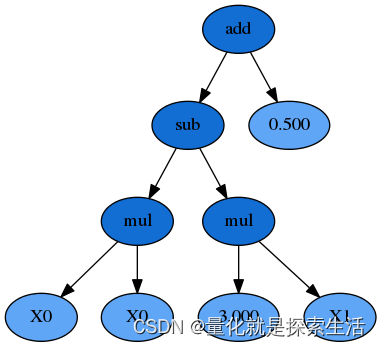
该公式表达是为
(
(
X
0
×
X
0
)
−
(
3.0
×
X
1
)
)
+
0.5
((X_0 \times X_0) - (3.0 \times X_1)) + 0.5
((X0×X0)−(3.0×X1))+0.5
program结果栈为:
['add', 'sub', 'mul', '0', '0', 'mul', 3.0, '1', 0.5]
公式树初始化
build_program
通过stack对树进行深度优先搜索构建
树的检验
validate_program
对树一次深度优先搜索,保证所有节点完备,即每一个函数参数量足够
_depth
深度优先搜索的同时记录最大深度
_length
返回program长度,即树的节点数量
树的打印
__str__:打印树
export_graphviz:可视化整个树
公式树的计算
execute:接受pandas或者二位nd_array,shape = [n_samples, n_features]
执行过程中,将program中的字符串和常数处理成可接受参数
- 常数需要广播成常向量
- 字符串转换为输入X中对应的列
- 若数据类型为面板数据
panel,X中需要额外输入证券列和时间列,
raw_fitness:原始适应度
- 由公式树计算出 y ^ \hat{y} y^
- 对 y ^ \hat{y} y^进行调整
- 计算
y
y
y与
y
^
\hat{y}
y^的适应度
metric
fitness:带惩罚项适应度
p
e
n
a
l
t
y
=
p
_
c
o
e
f
×
p
r
o
g
r
a
m
_
l
e
n
×
s
i
g
n
(
m
e
t
r
i
c
)
penalty=p\_coef \times program\_len \times sign(metric)
penalty=p_coef×program_len×sign(metric)
样本选择(防止过拟合)
为了防止过拟合,仅选择部分样本
get_all_indices 输入总样本量和抽样样本量
返回抽样内样本index和抽样外样本index
公式树交叉变异
get_sub_tree(random_state, program=None):获取子树



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











