







PyTorch 简介
PyTorch是一个基于Python的科学计算包,它主要有两个用途:
- 类似Numpy但是能利用GPU加速
- 一个非常灵活和快速的用于深度学习的研究平台
PyTorch 安装
需要配置好CUDA,然后安装对应版本的torch,可以选择下载好包后本地pip install。
Tensor
Tensor类似于numpy的ndarry,但是可以用GPU加速来计算。
使用前需要导入torch的包:
from __future__ import print_function
import torch
Tensor的主要函数
Tensor的一些主要函数:
x = torch.empty(5, 3) # 构造一个5x5的未初始化矩阵
print(x)
# tensor([[9.2755e-39, 1.0561e-38, 4.5919e-39],
# [4.5000e-39, 4.4082e-39, 5.9694e-39],
# [1.0286e-38, 8.9081e-39, 8.9082e-39],
# [6.9796e-39, 9.0919e-39, 9.9184e-39],
# [7.3470e-39, 1.0194e-38, 1.0469e-38]])
x = torch.rand(5, 3) # 随机初始化一个5x3的矩阵
print(x)
# 输出
# tensor([[0.8470, 0.3398, 0.5657],
# [0.2300, 0.8812, 0.5408],
# [0.0290, 0.9524, 0.5187],
# [0.8870, 0.7722, 0.1659],
# [0.1848, 0.3879, 0.9369]])
x = torch.zeros(5, 3, dtype=torch.long) # 构造一个零矩阵,类型是long
print(x)
#输出:
# tensor([[ 0, 0, 0],
# [ 0, 0, 0],
# [ 0, 0, 0],
# [ 0, 0, 0],
# [ 0, 0, 0]])
x = torch.tensor([5.5, 3]) # 用数组来构造tensor
print(x)
# 输出
# tensor([5.5000, 3.0000])
# 用现有的tensor来构造新的tensor(可以用不同的dtype)
x = x.new_ones(5, 3, dtype=torch.double) # new_* methods take in sizes
print(x)
x = torch.randn_like(x, dtype=torch.float) # override dtype!
print(x)
print(x.size()) # 用size()来查看tensor的shape
Operation
Operation一般可以使用函数的方式使用,但是为了方便使用,PyTorch重载了一些常见的运算符。
x = torch.rand(5, 3) # 随机初始化一个5x3的矩阵
y = torch.rand(5, 3)
print(x + y) # tensor的加法
print(torch.add(x, y)) # 用add函数来实现加法
result = torch.empty(5, 3) # 给加法提供一个返回值
torch.add(x, y, out=result) # x + y的结果放到result里。
print(result)
# 把相加的结果直接加到第一个加数上
y.add_(x) # 把x加到y
print(y)
就地修改tensor的operation以下划线结尾。比如:
x.copy_(y), x.t_(), 都会修改x。
Tensor的变换
# 用类似于下标的形式来操作Tensor
#打印x的第一列
print(x[:, 1])
# 同tensor.view来reShape一个Tensor
x = torch.randn(4, 4)
y = x.view(16)
z = x.view(-1, 8) # -1的意思是让PyTorch自己推断出第一维的大小。
print(x.size(), y.size(), z.size())
# 如果一个tensor只有一个元素,可以使用item()函数来把它变成一个Python number
x = torch.randn(1)
print(x) # 输出的是一个Tensor
print(x.item()) # 输出的是一个数
Tensor、Numpy桥
Tensor和Numpy的相互转换很容易,但是要注意一点:它们会共享地址,修改一方会影响另一方。
a = torch.ones(5)
print(a)
# tensor([ 1., 1., 1., 1., 1.])
b = a.numpy()
print(b)
# [1. 1. 1. 1. 1.]
a.add_(1)
print(a)
# tensor([ 2., 2., 2., 2., 2.])
print(b)
# [2. 2. 2. 2. 2.]
import numpy as np
a = np.ones(5)
b = torch.from_numpy(a)
np.add(a, 1, out=a)
print(a)
# [2. 2. 2. 2. 2.]
print(b)
# tensor([ 2., 2., 2., 2., 2.], dtype=torch.float64)
CPU上的所有类型的Tensor(除了CharTensor)都可以和Numpy数组来回转换。
Tensor+CDUA
Tensor可以用to方法来移到任意设备上
from __future__ import print_function
import torch
x = torch.randn(4, 4)
# 如果有CUDA
# 我们会使用``torch.device``来把tensors放到GPU上
if torch.cuda.is_available():
device = torch.device("cuda") # 一个CUDA device对象。
y = torch.ones_like(x, device=device) # 直接在GPU上创建tensor
x = x.to(device) # 也可以使用``.to("cuda")``把一个tensor从CPU移到GPU上
z = x + y
print(z)
print(z.to("cpu", torch.double)) # ``.to``也可以在移动的过程中修改dtype
# 输出
# tensor([[-0.4190, 0.2814, -0.0858, 1.1612],
# [ 0.2115, -0.9426, 0.9703, 1.7138],
# [ 1.8401, -0.5685, 0.9426, 2.0110],
# [ 0.9490, 1.4329, 2.9558, 1.1631]], device='cuda:0')
# tensor([[-0.4190, 0.2814, -0.0858, 1.1612],
# [ 0.2115, -0.9426, 0.9703, 1.7138],
# [ 1.8401, -0.5685, 0.9426, 2.0110],
# [ 0.9490, 1.4329, 2.9558, 1.1631]], dtype=torch.float64)
PyTorch中的神经网络
Autograd: 自动求导
Autograd为所有用于Tensor的operation提供自动求导的功能
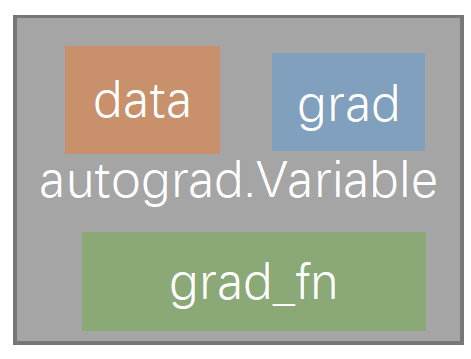
autograd.Variable 是这个包中最核心的类。 它包装了一个Tensor,并且几乎支持所有的定义在其上的操作。一旦完成了运算,可以调用 .backward()来自动计算出所有的梯度。
.data用来访问原始的 Tensor;
.grad用来累加这一 Variable 的梯度;还有一个在自动求导中非常重要的类 Function,Variable 和 Function 二者相互联系并且构建了一个描述整个运算过程的无环图。每个 Variable 拥有一个
.grad_fn属性,其引用了一个创建 Variable 的 Function。(除了用户创建的Variable 其 creator 部分是 None)。
计算Tensor的梯度,可以对一个Tensor调用它的backward()方法。如果这个Tensor是一个scalar(只有一个数),那么调用时不需要传任何参数。如果Tensor多于一个数,那么需要传入和它的shape一样的参数,表示反向传播过来的梯度。
from __future__ import print_function
from torch.autograd import Variable
import torch
x = torch.ones(2, 2, requires_grad=True)
print(x)
tensor([[1., 1.],
[1., 1.]], requires_grad=True)
y = x + 2
print(y)
tensor([[3., 3.],
[3., 3.]], grad_fn=)
print(y.grad_fn)
<AddBackward0 object at 0x0000026081C97148>
z = y * y * 3
out = z.mean()
print(z, out)
tensor([[27., 27.],
[27., 27.]], grad_fn=) tensor(27., grad_fn=)
requires_grad_()函数会修改一个Tensor的requires_grad。
梯度
out.backward()
print(x.grad)
tensor([[4.5000, 4.5000],
[4.5000, 4.5000]])
o = 1 4 ∑ i z i , z i = 3 ( x i + 2 ) 2 , z i ∣ x i = 1 = 27 , o=\frac{1}{4} \sum_{i} z_{i}, \\ z_{i}=3\left(x_{i}+2\right)^{2},\\[8pt] \left.z_{i}\right|_{x_{i}=1}=27, o=41i∑zi,zi=3(xi+2)2,zi∣xi=1=27,
因 此 , ∂ o ∂ x i = 3 2 ( x i + 2 ) , \text因此,\quad \frac{\partial o}{\partial x_{i}}=\frac{3}{2}\left(x_{i}+2\right), 因此,∂xi∂o=23(xi+2),
最 后 , 有 ∂ o ∂ x i ∣ x i = 1 = 9 2 = 4.5 \text最后,有 \left.\frac{\partial o}{\partial x_{i}}\right|_{x_{i}=1}=\frac{9}{2}=4.5 最后,有∂xi∂o∣∣∣∣xi=1=29=4.5
神经网络
神经网络可以使用torch.nn包来创建,nn使用我们上面了解过的autograd来进行模型的定义和求导。nn.Module包含了许多神经网络层(layer),并且forward(input)方法能返回output。
训练神经网络的基本步骤:
- 定义一个神经网络,包含一些可以训练的参数;
- 迭代一个训练数据集;
- 处理数据的输入;
- 计算loss(调用Module对象的forward方法);
- 计算loss对参数的梯度;
- 更新参数(通常使用梯度下降法来更新)weight = weight - learning_rate $ {\star} $ gradient
定义神经网络
import torch
import torch.nn as nn
import torch.nn.functional as F
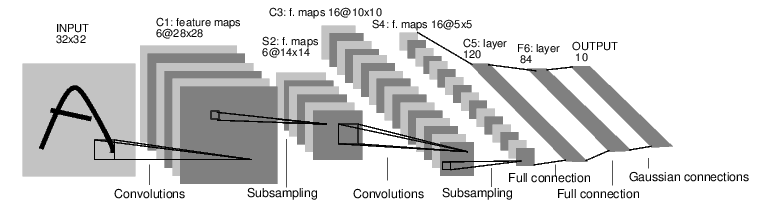
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
# 输入是1个通道的灰度图,输出6个通道(feature map),使用5x5的卷积核
self.conv1 = nn.Conv2d(1, 6, 5)
# 第二个卷积层的卷积核也是5x5,有16个通道
self.conv2 = nn.Conv2d(6, 16, 5)
# 全连接层
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
# 32x32 -> 28x28 -> 14x14
x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2))
# 14x14 -> 10x10 -> 5x5
x = F.max_pool2d(F.relu(self.conv2(x)), 2)
x = x.view(-1, self.num_flat_features(x))
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
def num_flat_features(self, x):
size = x.size()[1:] # 除了batch维度之外的其它维度。
num_features = 1
for s in size:
num_features *= s
return num_features
net = Net()
print(net)
# 输出
# Net(
# (conv1): Conv2d(1, 6, kernel_size=(5, 5), stride=(1, 1))
# (conv2): Conv2d(6, 16, kernel_size=(5, 5), stride=(1, 1))
# (fc1): Linear(in_features=400, out_features=120, bias=True)
# (fc2): Linear(in_features=120, out_features=84, bias=True)
# (fc3): Linear(in_features=84, out_features=10, bias=True)
# )
num_flat_features方法:将所有特征展开,然后传给下面只能接收一维特征的层,比如全连接层。可以写成:
x.view(-1, x.size()[1:].numel())
只需要定义forward函数,backward函数会自动通过autograd来生成。
- 方法
net.parameters()可以返回所有模型中可学习的参数
params = list(net.parameters())
print(len(params))
print(params[0].size()) # conv1的weight
# 输出
# 10
# torch.Size([6, 1, 5, 5])
测试神经网络
随机生成一个32x32的输入来检验网络的定义没有问题。
input = torch.randn(1, 1, 32, 32)
print(input)
out = net(input)
print(out)
# 输出
# tensor([[[[-1.1902, -1.0143, -0.6984, ..., 1.9511, -0.0156, 0.9260],
# [-0.9327, 0.0150, 1.0843, ..., -0.2636, -0.1169, -0.9445],
# [-0.1803, -0.9106, 0.1845, ..., -2.1039, -1.7185, 2.2898],
# ...,
# [-2.1018, 0.3044, 0.1973, ..., -1.6752, -0.1317, -0.0458],
# [-1.3928, 1.3621, 0.3082, ..., -0.8913, -0.4222, 0.7720],
# [ 0.8327, -0.2097, 1.3220, ..., -0.5530, -0.1954, -0.6375]]]])
# tensor([[-0.0855, 0.0118, -0.0287, 0.0216, 0.0339, -0.0606, 0.0537, 0.1262,
# -0.1251, -0.0410]], grad_fn=<AddmmBackward>)
由于梯度默认会叠加,所以我们通常在backward之前清除掉之前的梯度。
net.zero_grad()
out.backward(torch.randn(1, 10))
backward函数详解
Pytorch中是根据前向传播生成计算图的,如果最终生成的函数是标量,是一般情况下的backward反向传播,但是事实上backward中有个retain_graph和create_graph参数。
一般情况:
import torch
x = torch.tensor([1.0,2.0],requires_grad=True)
y = (x + 2)**2
z = torch.mean(y)
z.backward()
x.grad
# 输出
# tensor([3., 4.])
z = ( x 1 + 2 ) 2 + ( x 2 + 2 ) 2 2 ∂ z ∂ x 1 = x 1 + 2 = 3.0 ∂ z ∂ x 2 = x 2 + 2 = 4.0 \begin{aligned} z= \frac{\left(x_{1}+2\right)^{2}+\left(x_{2}+2\right)^{2}}{2} \end{aligned}\\\begin{aligned} \frac{\partial z}{\partial x_{1}}=x_{1}+2=3.0\end{aligned} \\\begin{aligned} \frac{\partial z}{\partial x_{2}}=x_{2}+2=4.0 \end{aligned} z=2(x1+2)2+(x2+2)2∂x1∂z=x1+2=3.0∂x2∂z=x2+2=4.0
x = torch.tensor([1.0,2.0,3.0],requires_grad=True)
y = (x + 2)**2
z = 4*y
z.backward()
# 会报错,因为只有标量输出才能求导
解决方法:为backward添加一个tensor参数:
x = torch.tensor([1.0,2.0,3.0],requires_grad=True)
y = (x + 2)**2
z = 4*y
z.backward(torch.tensor([1.,1.,1.]))
print(x.grad)
# 输出
# tensor([24., 32., 40.])
z = [ 4 ∗ ( x 1 + 2 ) 2 , 4 ∗ ( x 2 + 2 ) 2 ] ∂ z 1 ∂ x 1 = 8 ∗ ( x 1 + 2 ) = 24.0 ∂ z 2 ∂ x 2 = 8 ∗ ( x 2 + 2 ) = 32.0 ∂ z 2 ∂ x 3 = 8 ∗ ( x 3 + 2 ) = 40.0 \begin{aligned} z=[4 *&\left.\left(x_{1}+2\right)^{2}, 4 *\left(x_{2}+2\right)^{2}\right] \\ \frac{\partial z_{1}}{\partial x_{1}} &=8 *\left(x_{1}+2\right)=24.0 \\ \frac{\partial z_{2}}{\partial x_{2}} &=8 *\left(x_{2}+2\right)=32.0 \\ \frac{\partial z_{2}}{\partial x_{3}} &=8 *\left(x_{3}+2\right)=40.0 \end{aligned} z=[4∗∂x1∂z1∂x2∂z2∂x3∂z2(x1+2)2,4∗(x2+2)2]=8∗(x1+2)=24.0=8∗(x2+2)=32.0=8∗(x3+2)=40.0
添加的这个tensor是待求得x得梯度的系数,如果将其改变为[10.,10.,10.],则会变为
tensor([240., 320., 400.])
计算损失函数
损失函数的参数是(output, target)元组对,output是模型的预测,target是实际的值。损失函数会计算预测值和真实值的差别,损失越小说明预测的越准。
PyTorch提供了这里有许多不同的损失函数:跳转链接。
最简单的一个损失函数是:nn.MSELoss,它会计算预测值和真实值的均方误差。
output = net(input)
target = torch.arange(1, 11) # 随便伪造的一个“真实值”
target = target.view(1, -1) # 把它变成output的shape(1, 10)
criterion = nn.MSELoss()
loss = criterion(output, target)
print(loss)
计算梯度
在调用loss.backward()之前,我们需要清除掉tensor里之前的梯度,否则会累加进去。
net.zero_grad() # 清掉tensor里缓存的梯度值。
print('conv1.bias.grad before backward')
print(net.conv1.bias.grad)
loss.backward()
print('conv1.bias.grad after backward')
print(net.conv1.bias.grad)
更新参数
- 更新参数最简单的方法是使用随机梯度下降(SGD):
learning_rate = 0.01
for f in net.parameters():
f.data.sub_(f.grad.data * learning_rate)
- 通常我们会使用更加复杂的优化方法,比如SGD, Nesterov-SGD, Adam, RMSProp等等。为了实现这些算法,我们可以使用torch.optim包,它的用法也非常简单:
import torch.optim as optim
# 创建optimizer,需要传入参数和learning rate
optimizer = optim.SGD(net.parameters(), lr=0.01)
# 清除梯度
optimizer.zero_grad()
output = net(input)
loss = criterion(output, target)
loss.backward()
optimizer.step() # optimizer会自动帮我们更新参数
注意:即使使用optimizer,我们也需要清零梯度。但是我们不需要一个个的清除,而是用optimizer.zero_grad()一次清除所有。
参考资料
[1]. PyTorch深度学习:60分钟入门(Translation) 胡莱人形;
[2]. Pytorch中的backward函数 不吃猪肉的M;
[3]. PyTorch中文文档
附加产物
在服务器上部署了 J u p y t e r N o t e b o o k Jupyter Notebook JupyterNotebook,并且增加了多用户服务,虽然用起来没有markdown方便,但是拿来跑跑代码还是很清晰的,需要的朋友可以联系我获取链接。















 2703
2703

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









