







当我们得到数据模型后,该如何评价模型的优劣呢?之前看到过这样一句话 :“尽管这些模型都是错误的,但是有的模型是有用的”,想想这句话也是挺有道理的!评价和比较分类模型时,关注的是其泛化能力,因此不能仅关注模型在某个验证集上的表现。事实上,如果有足够多的样本作为验证集来测试模型的表现是再好不过的,但即使是这样也存在一个难点,比如难界定多大的样本才能足够表现出模型的泛化能力。因此,一般的做法是借助统计学的方法,评估模型在某个验证集分类表现的显著性。
评价及比较分类模型的过程,涉及到三个问题,一个是如何获取验证集,另一个是用什么度量指标表示分类表现,最后一个则是如何评估分类表现的显著性。
1. 验证集获取
数据样本的数量总是有限的,这就导致在选择训练集和验证集时出现了诸多方法,常用的方法有留出法、交叉验证法、bootstrap方法,下面分别介绍。
1.1 留出法
留出法一般用在样本数据量较大的情况。在使用留出法时,将样本数据分为两部分,一部分为训练集
,另一部分为验证集
,训练集
用来生成模型,验证集
用来评估其测试误差,将其作为对泛化误差的估计,这个思路比较简单,但是数据集
的划分过程需要注意两点:
与
的划分比例、
与
中样本的抽样方式。
与
的划分比例偏大时,由于
中数据样本量及包含的样本信息较少(糟糕的情况是其中还包含了较多噪声,这或许直接导致非常离谱的评估结果),因此其评估结果可能不够准确。即使
中包含了比较准确的样本信息,在换一个同等数量新的验证集时,可能包含的信息就不那么准确,评估结果也可能会有较大差别,故其评估结果不稳定;
与
的划分比例偏小时,由于训练数据包含较少的样本信息,这样得到的模型本身就不可取,这种情况比“
与
的划分比例偏大”更糟糕,之后用
得到的评估结果,已经是失真的了。那该如何选取训练集
与验证集
的划分比例呢?一般选用样本数据集
的2/3~4/5用来训练模型,剩余数据用来测试,验证集
应至少包含30个样本。
选择合适的划分比例后,还有(在
个样本中选取
个)的问题,因为此时样本选择仍有多种情况,单次使用留出法得到的评估结果往往不够可靠,一般采用多次随机划分、取评估结果的平均值的方式得到最终的评估结果。
1.2 交叉验证法
交叉验证法中,将样本数据集均分为
等份(注意,这个均分过程仍然要考虑1.1节中提到的信息均匀问题),前
份作为训练集,剩余一份作为测试集,得到测试结果。由于测试集的选择方式有
种,因此在数据集
的一次划分过程中可以得到
个测试结果,将这
个测试结果的平均值返回作为最终结果,这个过程通常称为“
折交叉验证”。当
=10时,交叉验证的过程示意图如下
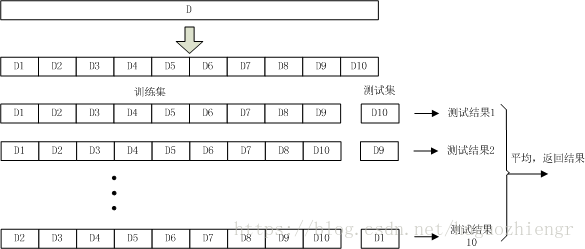
在交叉验证过程中,在确定样本数据集划分份数
时需要考虑1.1节中提到的训练集与测试集比例问题,除此之外,从数据集
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 6万+
6万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









