







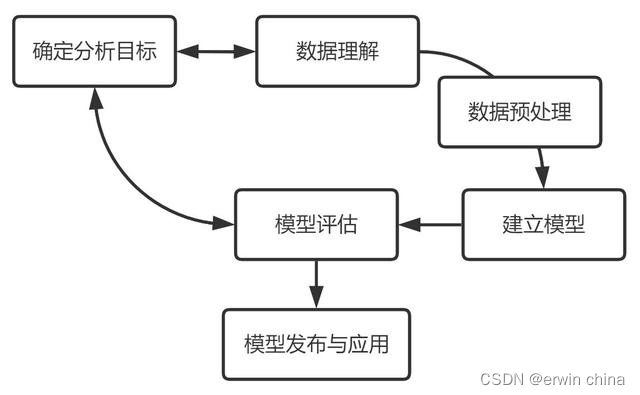
数据建模的基本流程主要包含六个步骤:确定分析目标、数据理解、数据准备、建立模型、模型评估、模型发布与应用。
数据建模是以业务为驱动,基于数据构建科学模型应用于实际中去解决问题的过程。这个过程并不以模型构建、或者模型落地就终止的,而是随着业务在不断地循环改进的。我参考了跨行业数据挖掘标准流程 CRISP-DM 和个人的一些拙见,对数据建模的六个环节进行整理,具体如下:
1.确定分析目标
一切分析的开始都是要基于明确的分析目标,不论何种业务场景,在分析前都需要了解好业务背景、业务需求,明确这次分析是为了解决什么业务问题,分析工作的最核心的需求是什么。如何理解业务需求可以做好以下两点:
与相关进行需求讨论,内容围绕业务逻辑、需求合理性、可行性等方面进行。
确定好分析需求后,指定分析框架和项目计划表。分析框架主要包括:目标变量的定义,大致的分析思路,数据抽样规则,潜在自变量的罗列,项目风险评估,大致的落地应用方案。
2.数据理解
数据理解阶段的重点是放在数据采集获取上。在工作中就是常说的“提数”,这个过程可以进行一系列的数据探索和熟悉,识别数据质量问题,发现数据的内部属性等,可以初步形成一些对数据的假设。
提数是数据建模的基础工作,也是影响模型输出结论的最重要的一步。如果源数据就错了,就不要想分析结果是对的。所以常常会有人说,数据分析工作其实是需要花大概80%的时间在数据上的。
在提数的过程中,需要注意:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2371
2371











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









