






摘要:
知识追踪是指机器在学生与课程互动时对他们的知识进行建模,这是计算机支持教育中一个公认的问题。尽管对学生知识进行有效建模具有很高的教育影响,但这项任务具有许多固有的挑战。在本文中,我们探讨了使用循环神经网络(RNNs)来模拟学生学习的效用。与以前的方法相比,RNN系列模型具有重要的优势,因为它们不需要对人类领域知识进行显式编码,并且可以捕获更复杂的学生知识表示。使用神经网络在一系列知识跟踪数据集上的预测性能有了实质性的提高。此外,学习模型可以用于智能课程设计,并允许直接解释和发现学生任务的结构。这些结果为知识追踪提供了一条有希望的新研究路线,并为RNNs提供了一个示范应用任务。
拓展:循环神经网络是Recurrent Neural Network,递归神经网络是Recursive Neural Network。循环神经网络是时间上的展开,处理的是序列结构的信息;递归神经网络是空间上的展开,处理的是树状结构的信息。LSTM是基于Recurrent Neural Network(循环神经网络)改进的。(参考:(6 封私信 / 72 条消息) 如何有效的区分和理解RNN循环神经网络与递归神经网络? - 知乎 (zhihu.com))
1. Introduction
在本文中,作者将RNNs应用到了知识追踪任务。“该系列模型使用人工“神经元”的大向量来表示潜在的知识状态及其时间动态,并允许从数据中学习学生知识的潜在变量表示,而不是硬编码。”
主要贡献:
(1)一种将学生互动编码为循环神经网络输入的新方法。
(2)在知识跟踪基准上,AUC比之前的最佳结果增加25%。
(3)证明我们的知识跟踪模型不需要专家注释。
(4)练习影响的发现和练习课程的改进。
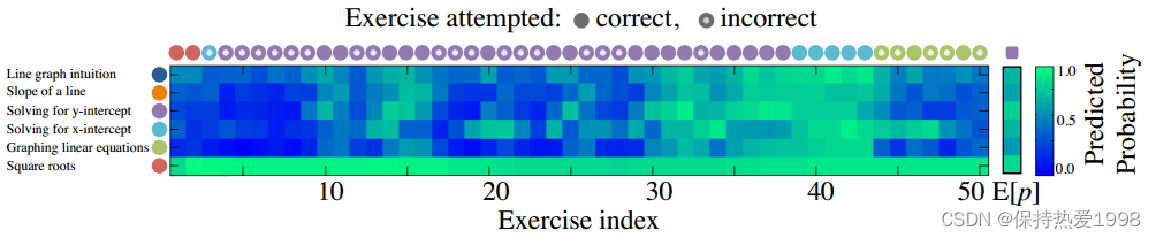
Figure 1: A single student and her predicted responses as she solves 50 Khan Academy exercises. She seems to master finding x and y intercepts and then has trouble transferring knowledge to graphing linear equations.
图1:一个学生和她解决50道可汗学院习题时的预测答案。她似乎掌握了找到x和y截距的方法,但在将知识转化为绘制线性方程时却遇到了困难。
图1解析(个人见解,敬请批评指正):
左侧列出了要对学生进行预测的6个知识点,分别有不同的颜色,从上到下依次为线形图直观、直线的斜率、求y轴截距、求x截距、绘制线性方程、根。上面有一排圈圈,表示的是学生回答问题的序列,颜色表示该题对应的知识点,实心圈表示回答正确,空心圈表示回答错误。例如前两个是实心的砖红色圈圈,这就表示这两道题考察的知识点是“根”,且该同学回答正确。以此类推。
“Each time the student answers an exercise we can make a prediction as to whether or not she would answer an exercise of each type correctly on her next interaction. 每次学生回答一个练习时,我们可以预测她是否会在下一次互动中正确回答每种类型的练习。”
中间蓝色绿色的小块块表示对学生能否答对下一道题的预测概率。最右边单独的竖条表示答对概率为0时小块是深蓝色,随着答对概率的增加块的颜色慢慢变绿,纯绿色表示学生答对的概率为1。看从左边数第1列,从上到下一共6个小块,对应6个知识点的预测概率。学生在回答了第1道题后,模型对学生答对第2道题的概率进行了预测,第1个小块表示对下一题答对线形图直观的概率,第2个小块表示对下一题答对直线的斜率的概率,……,第6个小块表示对下一题答对根的概率(大概为0.7)。第2题给出的题是跟相关的问题,预测答对概率0.7,实际情况:答对。以此类推。随着每次答题的进行,预测概率也在不断变化。
有趣的是,学生在第40题左右的时候几乎全绿了,这表示模型对学生的预测是学生对这6个知识点几乎掌握了。但是我们发现,从44题开始,在答错几道绘制线性方程的题目后,前4个知识点(线形图直观、直线的斜率、求y轴截距、求x截距)的概率也下降了,这就意味了,绘制线性方程与这4个知识点是有联系的。因为绘制线性方程的题目答错了,所以,前4个知识点的预测概率也下来了。
在图1中,在学生回答了50个练习之后,我们可以测试我们可能展示给她的下一个练习,并计算她在该选择下的预期知识状态。预计这个学生的下一个最优问题是重新求解y截距。
知识追踪的最终目的是根据给出的前t次的观察结果,预测学生第t+1题的各个方面。
2. Related Work
这一部分介绍了各种模型:贝叶斯知识追踪、其他动态概率模型、循环神经网络。前两个不大用看,循环神经网络这一块可以看看。
3. Deep Knowledge Tracing
进入正题!RNN模型。
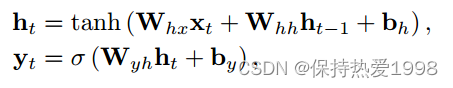
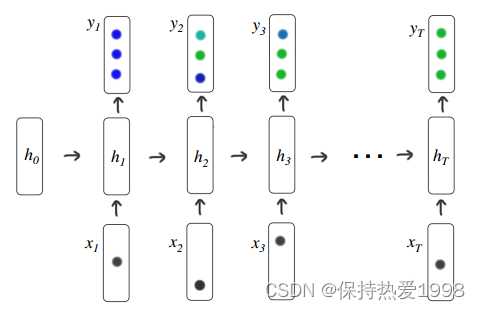
Figure 2: The connection between variables in a simple recurrent neural network. The inputs (xt) to the dynamic network are either one-hot encodings or compressed representations of a student action, and the prediction (yt) is a vector representing the probability of getting each of the dataset exercises correct.
图2:简单递归神经网络中变量之间的联系。动态网络的输入(xt)要么是单热编码,要么是学生动作的压缩表示,而预测(yt)是表示正确获得每个数据集练习的概率的向量
其中tanh和sigmoid函数σ(·)都是按元素应用的。模型由输入权矩阵Whx、循环权矩阵Whh、初始状态h0和读出权矩阵Wyh进行参数化。隐藏单元和读出单元的偏差由bh和by给出。
为了训练RNN或LSTM的学生交互,根据这些交互的性质,使用两种方法来实现这一点将这些交互转换为固定长度的输入向量序列xt:
小的特征空间:对于具有少量M个唯一练习的数据集,我们将设置为学生交互元组
的独热编码来表示回答了哪道题的组合以及是否答案正确,所以
。
和
的单独表示会降低性能。
大的特征空间:对于具有大量唯一练习的数据集,转而分配一个随机向量到每个输入元组,其中
,
。将每个输入向量
设置为相应的随机向量,
。这种独热高维向量的随机低维表示是由压缩感知驱动的。压缩感知表明,d维的k-稀疏信号可以从 klogd 随机线性投影(直至缩放和可加性常数)中精确恢复。由于独热编码是1-稀疏信号,学生交互元组可以通过将其分配给长度为~ log 2M的固定随机高斯输入向量来精确编码。
输出yt是一个长度等于问题数量的向量,其中每个条目表示学生正确回答该特定问题的预测概率。因此,at+1的预测值可以从对应于qt+1的yt项中读取。
损失函数:
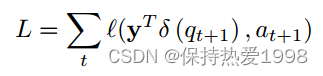
4. Educational Applications
我们使用经过训练的DKT来测试来自教育文献的两个经典课程规则:混合(mixing),即不同主题的练习混合在一起,以及阻塞(blocking),即学生回答一系列相同类型的练习。
5. Datasets
用到了3个数据集:Simulated Data、Khan Academy Data、Benchmark Dataset。
6. Results
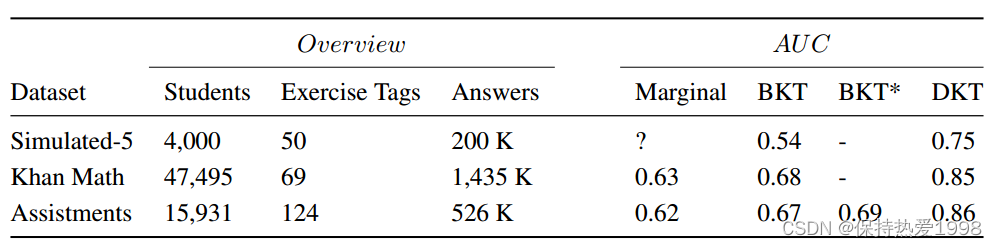
Table 1: AUC results for all datasets tested. BKT is the standard BKT. BKT* is the best reported result from the literature for Assistments. DKT is the result of using LSTM Deep Knowledge Tracing.
表1:所有测试数据集的AUC结果。BKT是标准的BKT。BKT*是Assistments文献中报道的最佳结果。DKT是使用LSTM深度知识跟踪的结果。
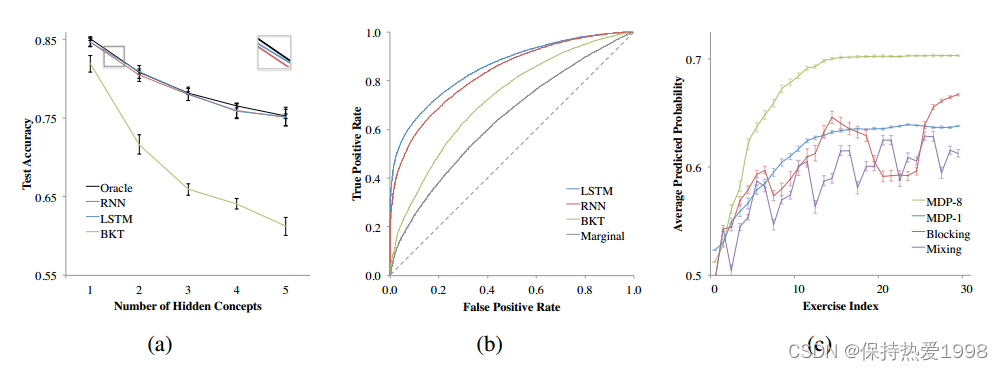
Figure 3: Left: Prediction results for (a) simulated data and (b) Khan Academy data. Right: (c) Predicted knowledge on Assistments data for different exercise curricula. Error bars are standard error of the mean.
图3:左:(a)模拟数据和(b)可汗学院数据的预测结果。右:(c)不同练习课程的Assistments数据预测知识。误差条是均值的标准误差。
图3解析(个人见解,敬请批评指正):
图(a):BKT预测随着隐藏概念数量的增加而大幅下降,因为它没有学习未标记概念的机制。这也说明了DKT模型具有更好的性能。
图(b):可汗学院数据的预测结果。结合表1可以看出,最上面蓝色的是使用了LSTM神经网络模型后的预测结果,AUC值为0.85,比标准的BKT模型(AUC=0.63)有了显著的改善。
图(c):我们测试了我们在Assistment数据集中的五个概念的子集上智能选择练习的能力。在辅助环境中,阻塞策略比混合策略有显著的优势。阻塞法的性能与解期望值深度练习(MDP-1)不相上下,如果在选择下一个问题时将目光放得更远,那么学生在解决更少的问题后就能获得更多的预测知识(MDP-8)。
7. Discussion
我们新模型的两个特别有趣的新特性是:(1)它不需要专家注释(它可以自己学习概念模式)和(2)它可以对任何可以矢量化的学生输入进行操作。相对于简单的隐马尔可夫方法,rnn的一个缺点是它们需要大量的训练数据,因此非常适合在线教育环境,但不适用于小型教室环境。
未来方向:对RNNs的进一步的调查可以将其他特征作为输入(如花费的时间),探索其他教育影响(如提示生成,辍学预测),并验证教育文献中提出的假设(如间隔重复,学生遗忘)。由于DKT采用向量输入,因此可以在更复杂的学习活动中跟踪知识。一个特别有趣的扩展是追踪学生在解决开放式编程任务时的知识。使用最近开发的程序向量化方法,我们希望能够随着学生学习编程的时间推移,智能地对他们的知识进行建模。
疑问?
 这里的这个expectimax是最大期望值吗?MDP-1和MDP-8是什么意思呢?
这里的这个expectimax是最大期望值吗?MDP-1和MDP-8是什么意思呢?

















 653
653

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









