







主要内容
第一部分 论文内容介绍
Abstract
知识追踪–即在学生与课程作业互动的过程中,由机器对其知识进行建模–是计算机支持教育中的一个公认问题。尽管有效地对学生的知识进行建模会对教育产生很大的影响,但这项工作有许多内在的挑战。在本文中,我们探讨了使用递归神经网络(RNN)对学生学习进行建模的效用。与以前的方法相比,RNN系列模型具有重要的优势,因为它们不需要对人类的领域知识进行明确的编码,而且可以捕捉到更复杂的学生知识的表现。使用神经网络可以大幅提高一系列知识追踪数据集的预测性能。此外,学到的模型可用于智能课程设计,并允许直接解释和发现学生任务中的结构。这些结果表明,知识追踪的研究是一个有前途的新方向,也是RNN的一个示范性应用任务。
1 Introduction
计算机辅助教育承诺开放世界一流的教学,并减少日益增长的学习成本。我们可以通过在流行的教育平台(如Khan Academy、Coursera和EdX)上构建大规模学生跟踪数据模型来实现这一承诺。
知识追踪的任务是随着时间的推移对学生的知识进行建模,以便我们能够准确地预测学生在未来的互动中的表现。对这项任务的改进意味着可以根据学生的个人需要向他们推荐资源,并且可以跳过或延迟那些预计太容易或太难的内容。目前,尝试定制内容的手动调整智能教学系统已经显示出有希望的结果[28]。一对一的人工辅导可以为普通学生带来两个标准差量级的学习收益[5]。机器学习解决方案可以为世界上任何人免费提供高质量个性化教学的好处。知识追踪问题本来就很困难,因为人类的学习是建立在人脑和人类知识的复杂性之上的。因此,使用丰富的模型似乎是合适的。然而,以往的研究大多依赖于函数形式受限的一阶马尔可夫模型。
本文提出了一种称为深度知识追踪(Deep Knowledge Tracing,DKT)的公式,将时间上“深”的柔性递归神经网络应用于知识追踪。这一系列模型利用人工神经元的大向量来表示潜在知识状态及其时间动态,并允许从数据中学习学生知识的潜在变量表示,而不是硬编码。这项工作的主要贡献是:
- 循环神经网络在追踪学生知识方面的新应用。
- 在知识追踪的基准上,AUC比以前的最佳结果提高了25%。
- 证明了我们的知识追踪模型不需要专家的注释。
- 发现练习的影响,并生成改进的练习课程。
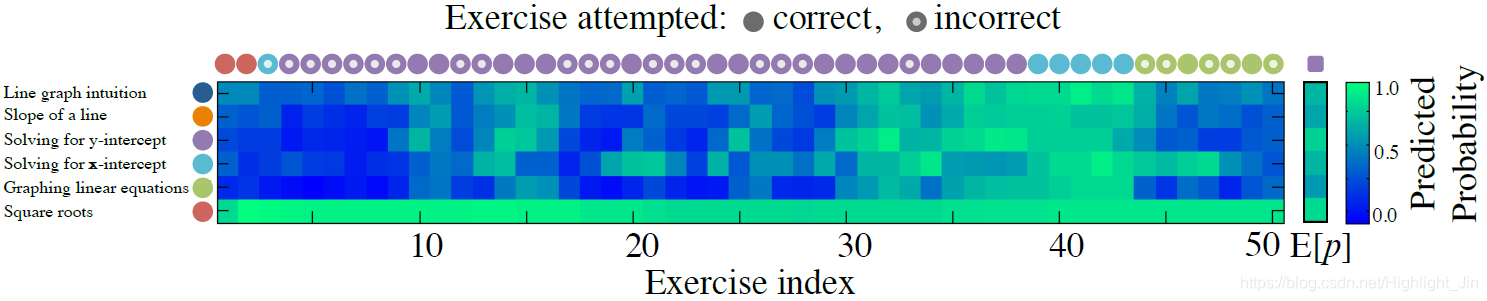
图1:一个学生和她在解决可汗学院八年级数学课程的50道练习时的预测反应。 她似乎掌握了寻找x和y的截距,但在将知识转移到绘制线性方程上时遇到了困难。
知识追踪的任务可以被形式化为:给定学生在一个特定学习任务上的互动观察 x 0 . . . x t x_0 ... x_t x0...xt,预测他们下一次互动 x t + 1 x_{t+1} xt+1的各个方面[6]。在知识追踪的最普遍的实例中,交互的形式是 x t = { q t , a t } x_t = \{q_t, a_t\} xt={qt,at}的元组,该元组将正在回答的练习的标签qt与该练习是否被正确回答相结合。当进行预测时,模型被提供给被回答的练习的标签 q t q_t qt,并且必须预测学生是否会得到正确的练习 a t a_t at。 图1显示了一个学习八年级数学的学生追踪知识的可视化情况。该学生首先正确地回答了两个平方根问题,然后得到了一个错误的x-截距练习。在随后的47次互动中,学生解决了一系列的x-截距、y-截距和绘图练习。每次学生回答练习时,我们都可以预测她是否会在下一次互动中正确回答每种类型的练习。在可视化中,我们只显示了随着时间的推移对相关的练习类型子集的预测。
在以前的大多数工作中,练习标签表示人类专家赋予一个练习的单一 “概念”。我们的模型可以利用,但不需要这种专家的注释。我们证明,在没有注释的情况下,该模型可以自主地学习内容的子结构。
2 Related Work
建模和预测人类学习方式的任务受到教育、心理学、神经科学和认知科学等不同领域的影响。从社会科学的角度来看,学习被理解为受到复杂的宏观层面互动的影响,包括情感[21]、动机[10]甚至认同[4]。目前的挑战进一步暴露在微观层面。学习从根本上说是人类认知的反映,是一个高度复杂的过程。认知科学领域中两个特别相关的主题是,人类的思维及其学习过程是递归的[12]和类比驱动的[13]。
知识追踪问题最早被提出,并在智能教学界得到了广泛的研究。面对前面提到的挑战,建立一个模型是一个主要的目标,这个模型可能不能捕捉所有的认知过程,但是仍然是有用的。
2.1 贝叶斯知识追踪
贝叶斯知识追踪(BKT)是建立学生学习的时间模型的最流行的方法。BKT将学习者的潜在知识状态建模为一组二元变量,每个变量代表对一个概念的理解或不理解[6]。当学习者正确或错误地回答一个给定概念的练习时,一个隐马尔可夫模型(HMM)被用来更新这些二元变量的概率。原始模型的表述假定,一旦学会了一项技能,就永远不会忘记。最近对这个模型的扩展包括猜测和失误估计的背景化[7],个别学习者的先前知识估计[33],以及问题难度估计[23]。
无论是否有这样的扩展,知识追踪都存在着一些困难。首先,对学生理解的二元表述可能是不现实的。其次,隐藏变量的含义和它们在练习中的映射可能是模糊的,很少能满足模型对每个练习的单一概念的期望。已经开发了几种技术来创建和完善概念类别和概念-练习的映射。目前的黄金标准,认知任务分析[31]是一个艰巨的、反复的过程,领域专家要求学习者在解决问题的时候谈出他们的思维过程。最后,用于建立过渡模型的二元反应数据对可以建模的练习种类造成了限制。
2.2 其他动态概率模型
部分可观察的马尔科夫决策过程(POMDPs)已被用于模拟学习者随时间变化的行为,在这种情况下,学习者遵循一个开放的路径来到达一个解决方案[29]。尽管POMDPs提供了一个非常灵活的框架,但它们需要探索一个指数级的大状态空间。目前的实现也被限制在一个离散的状态空间,潜变量的含义是硬编码的。这使得它们在实践中难以解决或不灵活,尽管它们有可能克服这两个限制。
来自性能因素分析(PFA)框架[24]和学习因素分析(LFA)框架[3]的较简单的模型已经显示出与BKT[14]相当的预测能力。为了获得比单独使用任何一个模型更好的预测结果,各种集合方法被用来结合BKT和PFA[8]。由AdaBoost、随机森林、线性回归、逻辑回归和前馈神经网络支持的模型组合都被证明比单独的BKT和PFA有更好的结果。但是,由于他们所依赖的学习者模型,这些组合技术也面临着同样的限制,包括对准确的概念标签的要求。
最近的工作探索了将项目反应理论(IRT)模型与交换式非线性卡尔曼过滤器[20]以及知识追踪[19, 18]相结合。虽然这些方法很有前途,但目前它们在功能形式上的限制更多,而且比我们这里介绍的方法更昂贵(由于对潜变量的推断)。
2.3 循环神经网络
循环神经网络是一系列灵活的动态模型,它随着时间的推移连接人工神经元。信息的传播是递归的,即隐藏的神经元根据对系统的输入和它们之前的激活而进化[32]。与教育中出现的同样是动态的隐马尔科夫模型相比,RNNs有一个高维的、连续的、潜在状态的表示。RNNs更丰富的表征的一个明显优势是它们能够在更晚的时间点上使用输入的信息进行预测。这对于长短时记忆(LSTM)网络来说尤其如此–一种流行的RNN类型[16]。
循环神经网络在一些时间序列任务中具有竞争力或最先进的水平–例如,语音转文本[15]、翻译[22]和图像字幕[17]–在这些任务中,有大量的训练数据可用。这些结果表明,如果我们把这项任务制定为时间神经网络的新应用,那么我们在追踪学生知识方面会更加成功。
3 Deep Knowledge Tracing
3.2 输入和输出的时间序列
为了在学生交互上训练 RNN 或 LSTM,有必要将这些交互转换为一系列固定长度的输入向量 xt。我们根据这些交互的性质使用两种方法来做到这一点:对于具有少量 M 个独特练习的数据集,我们将 xt 设置为学生交互元组 ht = {qt, at} 的单热编码,表示结合哪个练习被回答和如果练习被正确回答,所以 xt ∈ {0, 1} 2M。我们发现对 qt 和性能下降有单独的表示。
对于大型特征空间,one-hot 编码可能很快变得不切实际。对于具有大量独特练习的数据集,我们改为为每个输入元组分配一个随机向量 nq,a ∼ N (0, I),其中 nq,a ∈ RN 和 N M。然后我们设置每个输入向量xt 到相应的随机向量, xt = nqt,at 。
这种单热高维向量的随机低维表示是由压缩感知驱动的。压缩感知指出,d 维中的 k-稀疏信号可以从 k log d 随机线性投影(最多缩放和加性常数)中精确恢复 [2]。由于 one-hot 编码是 1-sparse 信号,学生交互元组可以通过将其分配给长度为 ∼ log 2M 的固定随机高斯输入向量来精确编码。尽管当前的论文仅涉及 1-hot 向量,但该技术可以轻松扩展以捕获固定长度向量中更复杂的学生互动的各个方面。
输出 yt 是一个长度等于问题数量的向量,其中每个条目表示学生正确回答该特定问题的预测概率。因此,可以从对应于 qt+1 的 yt 条目中读取 at+1 的预测。
3.3 优化
训练目标是模型下观察到的学生反应序列的负对数似然。 令 δ(qt+1) 是在时间 t + 1 时回答的唯一热编码,并令为二元交叉熵。 给定预测的损失为(y T i δ (qt+1), at+1),单个学生的损失为:L = X t (y T i δ (qt+1), at +1) (3) 在小批量上使用随机梯度下降最小化这个目标。 为了防止训练过程中的过度拟合,在计算读数 yt 时对 ht 应用了 dropout,但在计算下一个隐藏状态 ht+1 时则没有。 我们通过截断范数高于阈值的梯度长度来防止梯度“爆炸”,因为我们通过时间反向传播。 对于本文中的所有模型,我们始终使用 200 的隐藏维度和 100 的小批量大小。
4 Educational Applications
知识追踪的训练目标是根据学生过去的活动来预测他们未来的表现。这是直接有用的–例如,如果一个学生的能力经历了持续的评估,那么正式的测试就不再需要了。正如第6节所探讨的实验,DKT模型也可以为其他一些进步提供动力。
4.1 改进课程
我们的模型最大的潜在影响之一是在选择最佳的学习项目顺序来呈现给学生。给定一个具有估计隐藏知识状态的学生,我们可以查询我们的RNN来计算如果我们给他们分配一个特定的练习,他们的预期知识状态会是什么。例如,在图1中,在学生回答了50个练习后,我们可以测试每一个可能的下一个练习,我们可以给她看,并计算出她的预期知识状态,鉴于这个选择。预测这个学生的最佳下一个问题是重新审视解Y截距。
一般来说,选择下一个练习的整个序列以使预测的准确性最大化可以被表述为一个马尔可夫决策问题。在第6.1节中,我们将使用expectimax解决这个问题与教育文献中的两个经典课程规则进行比较:混合,即不同主题的练习混合在一起,以及阻断,即学生回答相同类型的系列练习[30]。课程是由一个有500个粒子的粒子过滤器来测试的,其中的概率是由一个训练有素的DKT模型得出。
4.2 发现习题之间的关系
DKT模型可以进一步应用于发现数据中的潜在结构或概念的任务,这项任务通常由人类专家来完成。我们通过给每一对练习 i i i和 j j j分配一个影响 J i j J_{ij} Jij来解决这个问题, J i j = y ( j ∣ i ) ∑ k y ( j ∣ k ) J_{ij} = \frac{y(j|i)}{\sum_{k}y(j|k)} Jij=∑ky(j∣k)y(j∣i), 其中 y ( j ∣ i ) y(j|i) y(j∣i) 是当练习 i i i在第一时间步骤中被正确回答时,RNN分配给练习 j j j的正确性概率。在第6.2节中,我们表明,RNN所捕获的依赖关系的这一特征可以恢复与练习相关的前提条件。
5 Datasets
为了评估性能,我们在三个数据集上测试了知识跟踪模型:模拟数据、Khan Academy数据和Assistments benchmark数据集。在每个数据集上,我们测量曲线下面积(AUC)。对于非模拟数据,我们使用5倍交叉验证来评估我们的结果,并且在所有情况下,超参数都是在训练数据上学习的。我们将深度知识追踪的结果与标准BKT进行比较,并在可能的情况下与BKT的最佳变化进行比较。此外,我们还将我们的结果与通过简单计算学生正确完成某一特定练习的边际概率得出的预测进行了比较。
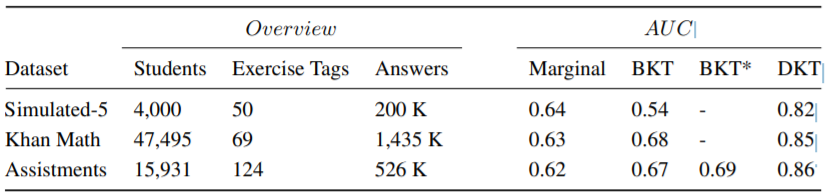
表1:所有测试数据集的AUC结果。 BKT是标准BKT。 BKT *是文献(literature for Assistments)中报道最好的结果。 DKT是使用LSTM深度知识跟踪的结果。
Sinulated Data: 我们模拟虚拟的学生学习虚拟的概念,并测试我们在这种受控环境下预测反应的能力如何。在这个实验的每一次运行中,我们产生两千名学生,他们回答50道来自k∈1 . . 5个概念。每个学生对每个概念都有一个潜在的知识状态,而每个练习都有一个单一的概念和一个难度。如果一个学生拥有概念技能α,那么他在难度为β的练习中获得正确答案的概率用经典的项目反应理论[9]建模为:
P
(
正
确
∣
α
,
β
)
=
c
+
1
−
c
1
+
e
−
α
β
P(正确|α,β)=c+ \frac{1-c}{1+e^{-αβ}}
P(正确∣α,β)=c+1+e−αβ1−c 其中c是随机猜测的概率(设定为0.25)。学生通过对技能的简单仿射变换,随着时间的推移而 “学习”,这与他们回答的练习相对应。为了了解不同的模型如何纳入无标签的数据,我们不向模型提供隐藏的概念标签(相反,输入只是练习索引和练习是否被正确回答)。我们在另外两千名模拟测试学生身上评估预测性能。
对于每个概念的数量,我们用不同的随机生成的数据重复实验20次,以了解准确性的平均值和方差。
6 Results
在所有三个数据集上,深度知识追踪的表现都大大超过了以前的方法。在Khan数据集上,使用LSTM神经网络模型的AUC为0.85,比标准的BKT(AUC=0.68)有明显的改进,特别是与BKT比边缘基线(AUC=0.63)的小幅改进相比。见表1和图3(b)。在Assistments数据集上,DKT比之前报告的最佳结果有25%的增益(AUC=0.86和0.69)[23]。与边缘基线(0.24)相比,我们报告的AUC收益是迄今为止在数据集上取得的收益(0.07)的三倍多。
合成数据集的预测结果为深度知识追踪的能力提供了一个有趣的证明。LSTM和RNN模型在预测学生反应方面的表现都不亚于对所有模型参数有完美了解的先知(只需要拟合潜在的学生知识变量)。见图3(a)。为了获得与预测不相上下的精确度,模型必须模仿一个包含以下内容的函数:潜在的概念、每个练习的难度、学生知识的先验分布和每个练习后发生的学习的仿生转换。相比之下,BKT预测随着隐藏概念数量的增加而大幅下降,因为它没有学习未标记概念的机制。
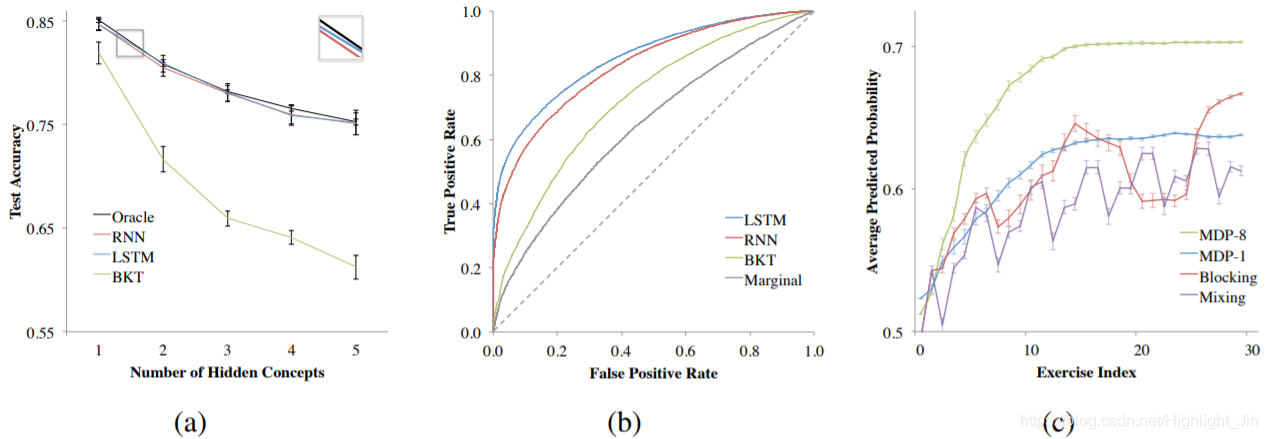
图3:左:(A)模拟数据和(B)Khan Academy Data的预测结果。右:©关于不同练习课程的辅助数据的预测知识。误差条是平均值的标准误差。
6.1 Expectimax课程
我们测试了不同的课程,从Assistment数据集中的30个练习中选出5个概念的子集。在这种情况下,阻塞似乎比混合有显著的优势。见图3(c)。虽然模块化的表现与解决预期相当,但如果我们在选择下一个问题时展望未来,我们会制定课程,让学生在解决较少的问题后获得更高的预测知识(MDP-8)。
6.2 发现的习题关系
对合成数据集的预测精度表明,利用DKT模型提取数据集中各评价之间的潜在结构是可能的。我们的模型对合成数据集的条件影响图显示了五个潜在概念的完美聚类(见图4),使用等式4中的影响函数设置了有向边。有趣的观察是,来自同一概念的一些练习在时间上相距很远。例如,在合成数据集中,节点编号描述序列,合成数据集中的第5个练习来自隐藏的概念1,即使直到第22个问题,来自同一概念的另一个问题才被提出,我们能够了解到两者之间有着很强的条件依赖性。
我们使用相同的技术分析了Khan数据集。由此产生的图表令人信服地阐述了8年级公共核心中的概念是如何相互关联的(见图4)。
节点编号表示运动标签)。我们将分析限制在练习A、B的有序配对上,以便在A出现后,B在序列的剩余部分出现超过1%的时间。
为了确定产生的条件关系是否是数据中明显潜在趋势的产物,我们将我们的结果与两个基线测量值进行了比较:(1)学生回答B的转移概率(假设他们刚刚回答了a)和(2)数据集中回答B的概率(不使用DKT模型)假设a是正确的学生答对了。两种基线方法都生成了不一致的图,如附录所示。虽然我们发现的许多关系对教育专家来说并不奇怪,但它们不需要人为干预,其微妙之处可能对课程设计有用。以上结果肯定了DKT网络学习到了一个连贯的模型。
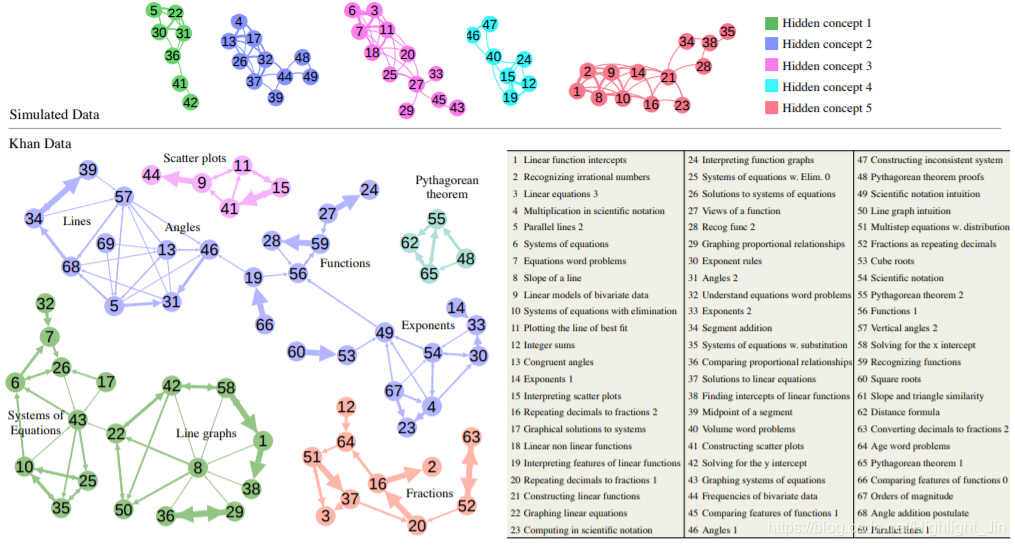
图4:DKT模型中练习之间的条件影响图。上图:我们在合成数据中观察到了潜在概念的完美聚类。下面是对8年级数学共同核心练习如何相互影响的令人信服的描述。箭头大小表示连接强度。注意,节点可以在两个方向上连接。幅值小于0.1的边已设置阈值。群集标签是手工添加的,但与每个群集中的练习完全一致。
7 Discussion
在本文中,我们将RNN应用于教育中的知识跟踪问题,在Assistments测试和Khan Academy Data上显示出比以往更先进的性能。我们的新模型有两个特别有趣的新特性:(1)它不需要专家注释(它可以自己学习概念模式)和(2)它可以对任何可以矢量化的学生输入进行操作。与简单的隐马尔可夫方法相比,RNNs的一个缺点是需要大量的训练数据,因此非常适合于在线教育环境,而不是小型课堂环境。
RNNs在知识追踪中的应用为今后的研究提供了许多方向。进一步的调查可以结合其他特征作为输入(如所用时间),探索其他教育影响(如提示生成、dropout预测),并验证教育文献中提出的假设(如间隔重复、学生如何遗忘的建模)。因为dkt采用向量输入,所以理论上我们可以在更复杂的学习活动中跟踪知识。一个特别有趣的扩展是跟踪学生在解决开放式编程任务时的知识[26,27]。利用最近开发的程序矢量化[25],我们希望能够随着时间的推移,在学生学习编程的过程中,对他们的知识进行智能建模。为了便于研究,补充材料中包括了DKTs规范。
在与Khan Academy的合作中,我们计划在一个对照实验中测试DKT对课程规划的有效性,通过在网站上提出练习。
附录
Figure A.5: 最好的学生和一般以下的学生有何不同?他们知识增长的差异似乎小得多。红色曲线表示50个问题后最接近班级第40百分位的学生的平均预测准确率,而蓝色曲线表示50个问题后最接近班级第100百分位的学生的平均预测准确率。
第二部分 写作积累
Abstract
Knowledge tracing 知识追踪
- XXX is a well established problem in computer supported education. xxx问题在计算机辅助教育中是一个公认的问题。
- inherent challenges 内在的挑战
- explore the utility of 探讨……的效用
- XXX have important advantages over previous methods in that + 句子. 与以前的方法相比,XXX具有重要的优势,因为……
- XXX results in substantial improvements in prediction performance on BBB. XXX在很大程度上提高了在BBB上的预测性能。
- These results suggest a promising new line of research for knowledge tracing and an exemplary application task for RNNs. 这些结果为知识追踪提供了一个新的研究方向,同时也为RNNs的应用提供了一个范例。
- effectively 有效地
1 Introduction
- a reduction in the growing cost of learning 减少日益增长的学习成本
- develop on this promise 实现这个承诺
- accurately 准确地
- promising results 令人满意的结果
- average student 学生,中等生,普通学生
- on the order of 大约,与……相似
- inherently 天生地,固有地,本身地
- ground
- latent knowledge state 潜在的知识状态
- A 25% gain in AUC over the best previous result on a knowledge tracing benchmark. 在知识跟踪的基准上,AUC比以前的最佳结果提高了25%。over表示比
- ubiquitous 最普遍的
- leverage v.利用
- We demonstrate that…… 我们证实了……
2 Related Work
- inform v.对……有影响
- as diverse as+举例 包括,例如
- for instance
- for example
- macro 宏观的;micro 微观的
- fundamentally 根本上,完全地
- In the face of aforementioned challenges 面对上述挑战
- represent v.代表
- First,…Second,…Finally…
- ambiguous 模糊的
- rarely 很少,罕见地
- meet 满足
- refine 改进,改善
- an arduous and iterative process 一个艰难迭代的过程
- impose a limit on 对……有限制
- in cases 在这种情况下
- present 提出
- arrive at a solution 得出一个解决方案
- be restricted to
- intractable 难以解决的
- inflexible 不灵活的
- have the potential to
- comparable to 与……相当
- grapple with 努力克服,努力解决
- approach 方法
- Though these approaches are promising, at present they are both more restricted in functional form and more expensive (due to inference of latent variables) than the method we present here. 虽然这些方法很有前途,但目前它们在功能形式上的限制更多,而且比我们这里介绍的方法更昂贵(由于对潜变量的推断)。
- a family of 一系列
- in contrast to 与……相比
- a notable advantage 一个明显的优势
- suggest v.表明,显示
- These results suggest that……
3 Deep Knowledge Tracing
- We believe that…… 我们认为……
- be difficult to quantify 很难去量化
- based upon
- a sequence of 一系列的
- be viewed as 被视为
- 3.1部分对于公式的介绍说明之后写论文中可以用到
- retain v.保留
- additionally 此外
- convert …… into …… 把……转变成……
- degrade performance 降低性能
- impractically 不切实际地
- consistently
4 Educational Applications
- undergo v.经历,经受
- As explored experimentally in Section 6, 正如第6节中的实验所探讨的那样
- power a number of other advancements 推动一些其他的改进 power v.推动,驱动
- optimal a.最佳的
- in general 一般来说
- be phrased as 被表述为
- so as to
- be typically performed by 通常由……执行
- approach this problem 解决这个问题
- related to;associated with 与……相关
5 Datasets
- For the non-simulated data we evaluate our results using 5-fold cross validation and in all cases hyper-parameters are learned on training data. 对实验细节的描述
- compare …… to ……
- 从table 1中获得的启示:(1)在论文中如果出现数字,千分位要加逗号,如:4,000(2)BKT* is the best reported result from the literature for Assistments. 论文写作中,对于表格中的数据结果,如果是引用别人的,则可以这样说明。
- for each run of this experiment 在这个实验的每一次运行中
- correspond to
- incorporate
- evaluate prediction performance
- additional
- For each number of concepts we repeat the experiment 20 times with different randomly generated data to understand accuracy mean and variance. 写作中,实验细节中可能用到。
- have access to
- be governed by 受……控制,受……约束
- in accordance with 符合;和……一致
- to the best of our knowledge 据我们所知
- It is, to the best of our knowledge, the largest publicly available knowledge tracing dataset. 它是最大的公开可用的知识追踪数据集。
6 Results
- outperform v.优于
- On all three datasets Deep Knowledge Tracing substantially outperformed previous methods. 论文写作中可以用
- notable improvement 明显的改进
- especially 特别地
- to date 迄今,到目前为止
- substantially 大大地
- have a notable advantage over 比……有显著的优势
- on par with 与……同等水平;与……平分秋色
- reveal v.揭示
- compelling articulation 令人信服的表达
- depict v.描绘,描写,描述
- restrict
- we compared our results to two baseline measures 论文写作比较的句子
- uncover v.发现
- subtlety n.巧妙,微妙
- discordant a.不一致的
7 Discussion
- In this paper we apply RNNs to the problem of knowledge tracing in education, showing improvement over prior state-of-the-art performance on the Assistments benchmark and Khan dataset. 论文写作中可以用
- be consistent with 与……一致
- they require large amounts of training data 深度学习模型的特点,论文写作中可以用到
- to facilitate research 为了便于研究
附录
对图片的描述:
The red curve shows the mean predicted accuracy for students closest to the 40th percentile of the class after 50 questions, while the blue curve is for students closest to the 100th percentile of the class after 50 questions. 红色曲线表示……,蓝色曲线表示……

















 661
661

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









