







1.Model
使用的是动态图版本的Paddle。所以用了Paddle.nn。
输入维度为obs_dim;输出维度为act_dim。中间隐藏层是100个神经元。第一层网络输出使用tanh激活函数;第二层网络输出使用softmax函数将数值转化为概率。
class CartpoleModel(parl.Model):
def __init__(self, obs_dim, act_dim):
super(CartpoleModel, self).__init__()
self.fc1 = nn.Linear(obs_dim, 100)
self.fc2 = nn.Linear(100, act_dim)
def forward(self, x):
out = paddle.tanh(self.fc1(x))
prob = F.softmax(self.fc2(out))
return prob
可以输出下列代码查看网络的结构:
import paddle
import paddle.nn as nn
import paddle.nn.functional as F
import parl
class CartpoleModel(parl.Model):
def __init__(self, obs_dim, act_dim):
super(CartpoleModel, self).__init__()
self.fc1 = nn.Linear(obs_dim, 100)
self.fc2 = nn.Linear(100, act_dim)
def forward(self, x):
out = paddle.tanh(self.fc1(x))
prob = F.softmax(self.fc2(out))
return prob
model = CartpoleModel(4,2)
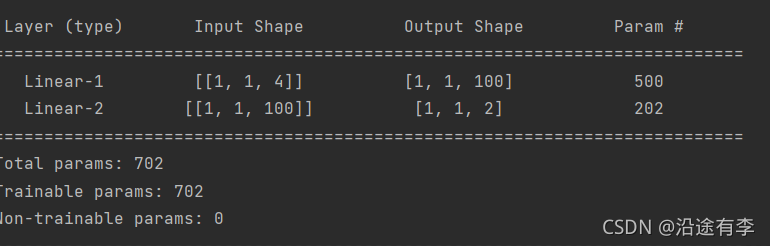
paddle.summary(model,(1,1,4))#输入是(1,4)的矩阵
得到的结果是:
2.Agent
继承parl.Agent基类,从说明文档中可以知道,self.alg就等于self.algorithm。
sample()函数实现探索
predict()函数实现预测——用Q-learning(取max)
class CartpoleAgent(parl.Agent):
def __init__(self, algorithm):
super(CartpoleAgent, self).__init__(algorithm)
def sample(self, obs):
obs = paddle.to_tensor(obs, dtype='float32')
prob = self.alg.predict(obs)
prob = prob.numpy()
act = np.random.choice(len(prob), 1, p=prob)[0]
return act
def predict(self, obs):
obs = paddle.to_tensor(obs, dtype='float32')
prob = self.alg.predict(obs) ##是由于继承了parl.agent这个基类,所以alg=algorithm
act = prob.argmax().numpy()[0]
return act
def learn(self, obs, act, reward, next_obs, terminal):
act = np.expand_dims(act, axis=-1)
reward = np.expand_dims(reward, axis=-1)
terminal = np.expand_dims(reward, axis=-1)
obs = paddle.to_tensor(obs, dtype='float32')
act = paddle.to_tensor(act, dtype='int32')
reward = paddle.to_tensor(reward, dtype='float32')
next_obs = paddle.to_tensor(next_obs, dtype='float32')
terminal = paddle.to_tensor(terminal, dtype='float32')
loss = self.alg.learn(obs, act, reward, next_obs, terminal) ##将数据送到了当前算法DQN的learn中
return loss.numpy()[0]
3.Train
rpm表示经验池
def run_episode(agent, env, rpm):
obs_list, action_list, reward_list, next_obs_list, done_list = [], [], [], [], []
total_reward = 0
obs = env.reset()
step = 0
while True:
step += 1
action = agent.sample(obs)
next_obs, reward, done, _ = env.step(action)
rpm.append((obs, action, reward, next_obs, done))
# obs_list.append(obs)
# action_list.append(action)
# reward_list.append(reward)
# next_obs_list.append(next_obs)
# done_list.append(done)
if (len(rpm) >MEMORY_WARMUP_SIZE) and (step % LEARN_FREQ == 0):
(batch_obs, batch_action, batch_reward, batch_next_obs,
batch_done) = rpm.sample(32)
train_loss = agent.learn(batch_obs, batch_action, batch_reward,
batch_next_obs,
batch_done) ###在这里去学习就是agent.learm负责转换数据交给DQN.learn
total_reward += reward
obs = next_obs
if done:
break
return total_reward
4.RelayMemory
就是为了实现DQN的经验回放。
其将系统探索环境得到的数据储存起来,然后随机采样样本更新深度神经网络的参数。
由于agent与环境交互得到的训练样本并不是独立同分布的,为了解决这一问题DQN引入了经验回放机制。利用一个回放以往经验信息的buffer,将过去的experience和目前的experience混合,降低了数据相关性。并且,经验回放还使得样本可重用,从而提高学习效率。
class ReplayMemory(object):
def __init__(self, max_size):
self.buffer = collections.deque(maxlen=max_size)
def append(self, exp):
self.buffer.append(exp)
def sample(self, batch_size):
mini_batch = random.sample(self.buffer, batch_size)
obs_batch, action_batch, reward_batch, next_obs_batch, done_batch = [], [], [], [], []
for experience in mini_batch:
s, a, r, s_p, done = experience
obs_batch.append(s)
action_batch.append(a)
reward_batch.append(r)
next_obs_batch.append(s_p)
done_batch.append(done)
return np.array(obs_batch).astype('float32'), \
np.array(action_batch).astype('float32'), np.array(reward_batch).astype('float32'), \
np.array(next_obs_batch).astype('float32'), np.array(done_batch).astype('float32')
def __len__(self):
return len(self.buffer)
5.总的代码
import os
import gym
import paddle
import paddle.nn as nn
import paddle.nn.functional as F
import parl
from parl.utils import logger
import random
import collections
import numpy as np
LEARN_FREQ = 5 # 训练频率,不需要每一个step都learn,攒一些新增经验后再learn,提高效率
MEMORY_SIZE = 20000 # replay memory的大小,越大越占用内存
MEMORY_WARMUP_SIZE = 200 # replay_memory 里需要预存一些经验数据,再从里面sample一个batch的经验让agent去learn
BATCH_SIZE = 32 # 每次给agent learn的数据数量,从replay memory随机里sample一批数据出来
GAMMA = 0.99 # reward 的衰减因子,一般取 0.9 到 0.999 不等
LEARNING_RATE = 0.001 # 学习率
class ReplayMemory(object):
def __init__(self, max_size):
self.buffer = collections.deque(maxlen=max_size)
def append(self, exp):
self.buffer.append(exp)
def sample(self, batch_size):
mini_batch = random.sample(self.buffer, batch_size)
obs_batch, action_batch, reward_batch, next_obs_batch, done_batch = [], [], [], [], []
for experience in mini_batch:
s, a, r, s_p, done = experience
obs_batch.append(s)
action_batch.append(a)
reward_batch.append(r)
next_obs_batch.append(s_p)
done_batch.append(done)
return np.array(obs_batch).astype('float32'), \
np.array(action_batch).astype('float32'), np.array(reward_batch).astype('float32'), \
np.array(next_obs_batch).astype('float32'), np.array(done_batch).astype('float32')
def __len__(self):
return len(self.buffer)
class CartpoleModel(parl.Model):
def __init__(self, obs_dim, act_dim):
super(CartpoleModel, self).__init__()
self.fc1 = nn.Linear(obs_dim, 100)
self.fc2 = nn.Linear(100, act_dim)
def forward(self, x):
out = paddle.tanh(self.fc1(x))
prob = F.softmax(self.fc2(out))
return prob
##输入是(1,4)的obs矩阵,输出是(1,2)的动作概率
class CartpoleAgent(parl.Agent):
def __init__(self, algorithm):
super(CartpoleAgent, self).__init__(algorithm)
def sample(self, obs):
obs = paddle.to_tensor(obs, dtype='float32')
prob = self.alg.predict(obs)
prob = prob.numpy()
act = np.random.choice(len(prob), 1, p=prob)[0]
return act
def predict(self, obs):
obs = paddle.to_tensor(obs, dtype='float32')
prob = self.alg.predict(obs) ##是由于继承了parl.agent这个基类,所以alg=algorithm
act = prob.argmax().numpy()[0]
return act
def learn(self, obs, act, reward, next_obs, terminal):
act = np.expand_dims(act, axis=-1)
reward = np.expand_dims(reward, axis=-1)
terminal = np.expand_dims(reward, axis=-1)
obs = paddle.to_tensor(obs, dtype='float32')
act = paddle.to_tensor(act, dtype='int32')
reward = paddle.to_tensor(reward, dtype='float32')
next_obs = paddle.to_tensor(next_obs, dtype='float32')
terminal = paddle.to_tensor(terminal, dtype='float32')
loss = self.alg.learn(obs, act, reward, next_obs, terminal) ##将数据送到了当前算法的learn中
return loss.numpy()[0]
def run_episode(agent, env, rpm):
obs_list, action_list, reward_list, next_obs_list, done_list = [], [], [], [], []
total_reward = 0
obs = env.reset()
step = 0
while True:
step += 1
action = agent.sample(obs)
next_obs, reward, done, _ = env.step(action)
rpm.append((obs, action, reward, next_obs, done))
# obs_list.append(obs)
# action_list.append(action)
# reward_list.append(reward)
# next_obs_list.append(next_obs)
# done_list.append(done)
if (len(rpm) >MEMORY_WARMUP_SIZE) and (step % LEARN_FREQ == 0):
(batch_obs, batch_action, batch_reward, batch_next_obs,
batch_done) = rpm.sample(32)
train_loss = agent.learn(batch_obs, batch_action, batch_reward,
batch_next_obs,
batch_done)
total_reward += reward
obs = next_obs
if done:
break
return total_reward
# evaluate 5 episodes
def evaluate(env, agent, render=False):
eval_reward = []
for i in range(5):
obs = env.reset()
episode_reward = 0
while True:
action = agent.predict(obs) # 预测动作,只选最优动作
obs, reward, done, _ = env.step(action)
episode_reward += reward
if render:
env.render()
if done:
break
eval_reward.append(episode_reward)
return np.mean(eval_reward)
def main():
env = gym.make('CartPole-v0')
# env = env.unwrapped # Cancel the minimum score limit
obs_dim = env.observation_space.shape[0]
act_dim = env.action_space.n
logger.info('obs_dim {}, act_dim {}'.format(obs_dim, act_dim))
rpm = ReplayMemory(MEMORY_SIZE)
# build an agent
model = CartpoleModel(obs_dim=obs_dim, act_dim=act_dim)
alg = parl.algorithms.DQN(model, gamma=0.99, lr=1e-3)
agent = CartpoleAgent(alg)
##加载
save_path = './dqn_model.ckpt'
agent.restore(save_path)
while len(rpm) < MEMORY_WARMUP_SIZE:
run_episode(agent, env, rpm)
max_episode = 2000
# start train
episode = 0
while episode < max_episode: # 训练max_episode个回合,test部分不计算入episode数量
# train part
for i in range(0, 50):
total_reward = run_episode(agent, env, rpm)
episode += 1
# test part
eval_reward = evaluate(env, agent, render=True) # render=True 查看显示效果
logger.info('episode:{} Test reward:{}'.format(
episode, eval_reward))
# 训练结束,保存模型
save_path = './dqn_model.ckpt'
agent.save(save_path)
if __name__ == '__main__':
main()
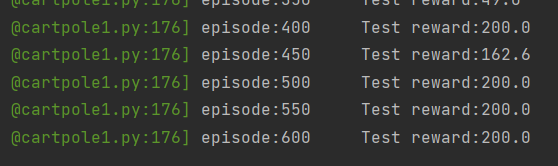
6.结果
4000次
















 789
789











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









