










transformer
Google 在 2017 年提出了基于注意力机制的网络结构 Transformer,进一步在机器翻译效果上取得显著提升。Transformer 结构的核心创新点在于提出了多头自注意力机制(multi-head self-attention),一方面通过自注意力将句中相隔任意长度的词距离缩减为常量,另一方面通过多头结构捕捉到不同子空间的语义信息,因此可以更好地完成对长难句的编码和解码。由于 Transformer 完全基于前馈神经网络,缺少了像卷积神经网络和循环神经网络中对位置信息的捕捉能力,因此它还显式地对词的不同位置信息进行了编码,与词嵌入一起作为模型的输入。另外,相对于循环神经网络,Transformer 大大提升了模型的并行能力,在训练和预测时效率都远高于基于循环神经网络的机器翻译模型。
神经机器翻译模型适于Google在2014年提出的基于LSTM的encoder-decoder
Q: 如何使用卷积神经网络和循环神经网络解决问答系统中的长距离语境依赖问题? Transformer相比以上方法有何改进?
A: 由于卷积神经网络难以处理较长语境,因此使用循环神经网络,如 LSTM ,可以在一定程度上解决这个问题。LSTM 通过在经典循环神经网络的隐藏层单元中加入记忆单元,并控制是否保存上一时刻的长短期记忆单元信息,来改善在学习循环神经网络时遇到的梯度消失或爆炸问题。相比于卷积神经网络,LSTM可以学习较长跨度的依赖信息,更适合用来学习较长文本的特征表示。
由于 LSTM序列化的模型结构,无法利用并行来加速计算,这使得模型在训练和预测过程中的计算时间都比较长,可用于学习的训练样本量也因此受到了限制。此外,LSTM在学习文本段落中较长距离的信息依赖时仍然存在一定的困难(网络中的前向/反向信号的传播长度与依赖距离成正比)。
相比上述这些方法,注意力机制降低了信号传播的长度,它通过有限个计算单元来处理文本序列各个位置之间的依赖,使得长距离语境依赖更容易被学习;另外,由于序列化执行的单元个数减少,模型可以利用并行化来提升计算速度。在 Transformer架构中 ,就使用了自注意力机制结构,完全取代了卷积神经网络和循环神经网络结构,能够使用较短的信息传递路径学习文本中的长距离语境依赖。自注意力机制采用了尺度缩放点积注意力(scaled dot-product attention)来计算注意力权重:
在Transformer的实现过程中一共用到3个tricks:
1)Queries, keys and values
这种命名的方式来源于搜索领域,假设我们有一个key-value形式的数据集,就比如说是我们知乎的文章,key就是文章的标题,value就是我们文章的内容,那这个搜索系统就是希望,能够在我们输入一个query的时候,能够唯一返回一篇最我们最想要的文章。那在self-attention中其实是对这个task做了一些退化的处理,我们优化并不是返回一篇文章,而是返回所有的文章value,并且使用key和query计算出来的相关权重,来找到一篇得分最高的文章。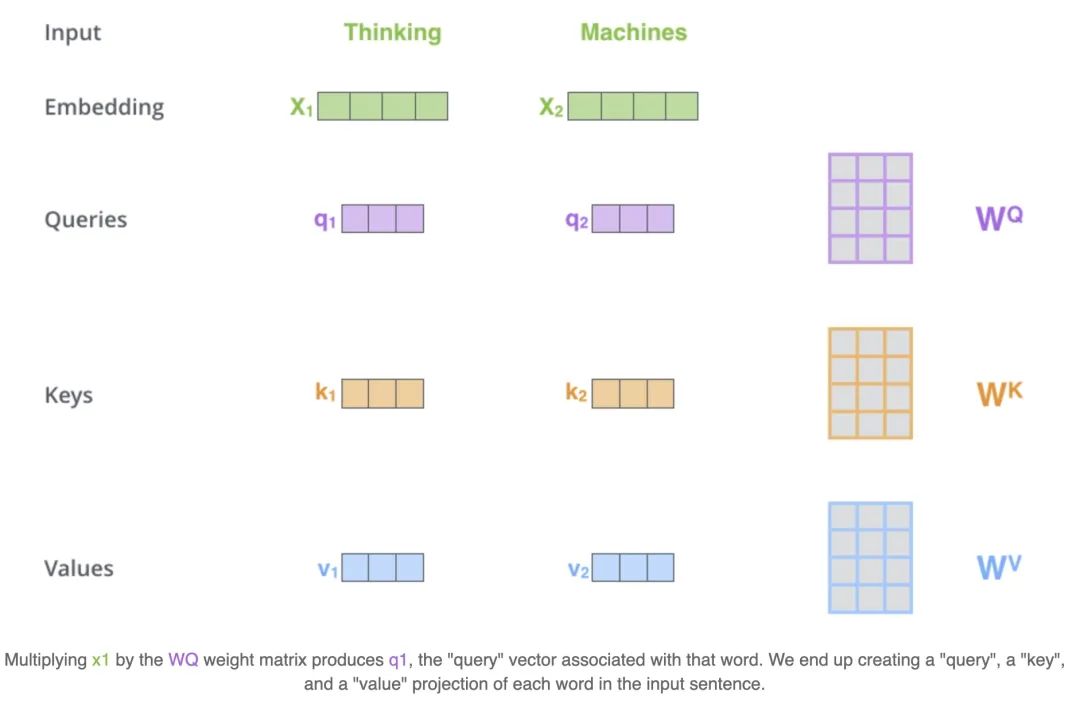
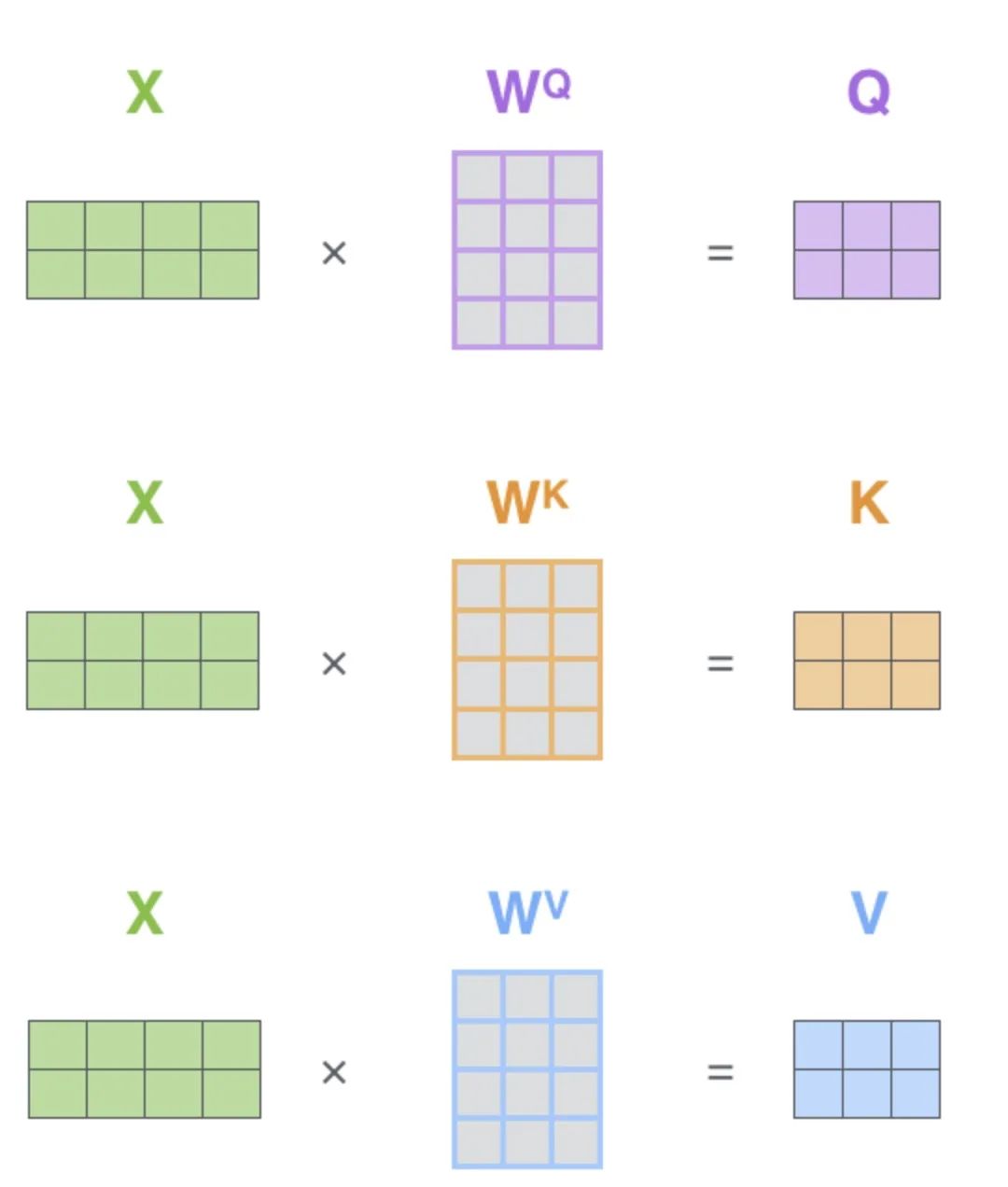
2) 缩放点积的值(Scaling the dot product)
Softmax 函数对非常大的输入很敏感。这会使得梯度的传播出现为问题(kill the gradient),并且会导致学习的速度下降(slow down learning),甚至会导致学习的停止那如果我们使用来对输入的向量做缩放,就能够防止进入到softmax的函数增长过大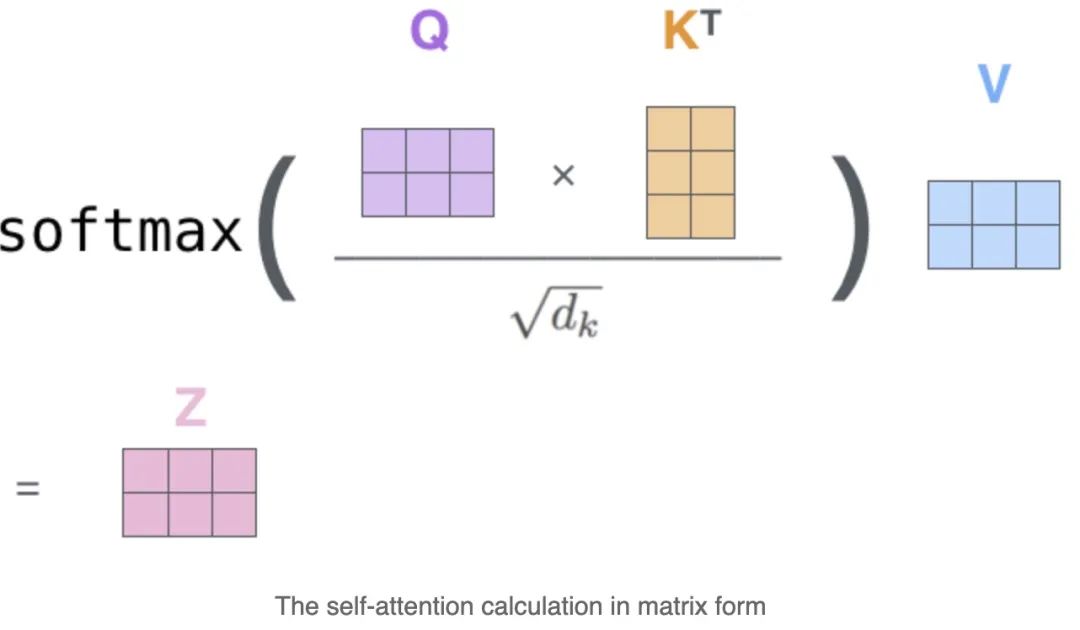
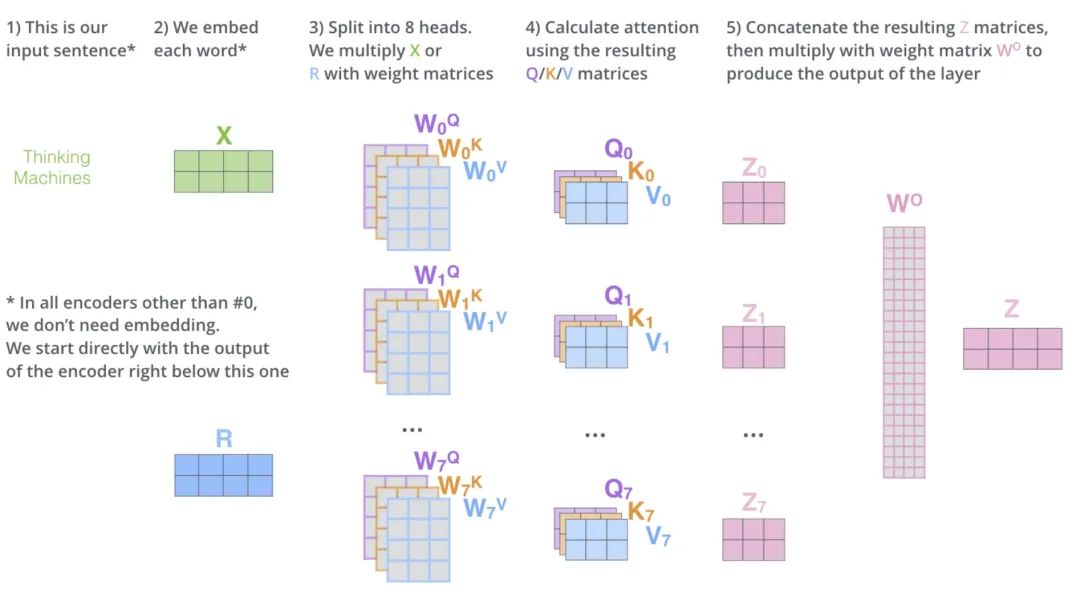
3)multi-head attention
在真实的语言环境中,每一个词和不同的词,都有不同的关系。我们考虑下面这个例子, I attended my friend Summer's birthday party。我们可以看到attended和不同的部分有不同的关系。 首先, I 表示谁在进行 attend 的动作, party 表达被 attend 的是什么, Summer 表示所属。我们就可以用不同的self-attention mechanism来捕获这些不同的关系。如果我们只进行single self-attention,所有的信息都会被加和到一起。如果是 Summer 参加 I party ,那么我们得到的 就是一样的了,但是其实意思应发生了改变。 所以,我们可以通过增加多个self-attention这样的结构,来给self attention更强的辨别能力,我们就有了更多个 q,k,v的矩阵
在给文本段落编码时如何结合问题信息?这么做有什么好处?
对于同一个文本段落,不同问题的答案往往来自于段落中不同的位置。如果在对段落编码时结合问题信息,可以获得更有效的编码表示。基于这种思路,BiDAF(Bi-Directional attenton flow)、DCN(Dynamic Coattention Network)等方法就使用注意力机制来实现问题和段落的协同编码。 以DCN为例,它通过协同编码方式分别获取问题和段落的注意力编码。段落的编码矩阵![]()
![]()
其中l是编码特征的维度,m和n分别是段落和问题的文本长度,编码矩阵中多出来的一行是额外加入的哨兵向量(以允许注意力机制不关注段落或问题中的任一个词)。首先计算仿射矩阵L![]()
对L中的每一个列向量做Softmax归一化可以获得问题相对于段落的注意力矩阵,而对L中每一个行向量做Softmax归一化可以获得段落相对于问题的注意力矩阵,即![]()
这样,我们可以算得问题中每个词相对于段落的注意力编码,即![]()
类似地,也可以算得段落中每个词相对于问题的注意力编码![]()
如何对文本中此对位置信息进行编码
卷积神经网络可以在一定程度上利用文本中各个词的位置信息,但对于较长文本的处理能力比较有限。循环神经网络可以利用隐状态编码来获取位置信息,但普通的循环神经网络处理长文本的能力也有限,需要结合注意力机制等方法进行改进。注意力机制可以获取全局中每个词对之间的关系,但并没有显示保留位置信息。如果对文本中单词的位置进行显示编码并作为输入,则可以方便模型学习和利用单词的位置信息,以提升模型效果。 在Transformer中,研究者采用不同频率的正弦/余弦函数对位置信息进行编码。记![]()
表示位置pos的编码向量中第i维的取值,则有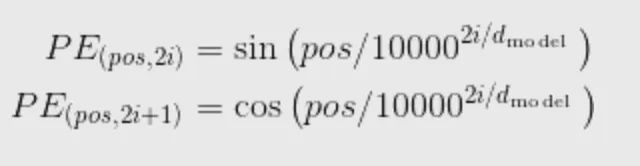
其中,是单词的文本编码向量的维度。位置编码向量的维度一般与文本编码向量的维度相同,都是,这样二者可以直接相加作为单词最终的编码向量(既带有文本信息又含有位置信息) 上述位置编码方式可以方便模型学习相对位置特征,这是因为对于相隔为k的两个位置p1和p2=p1+k。则![]()
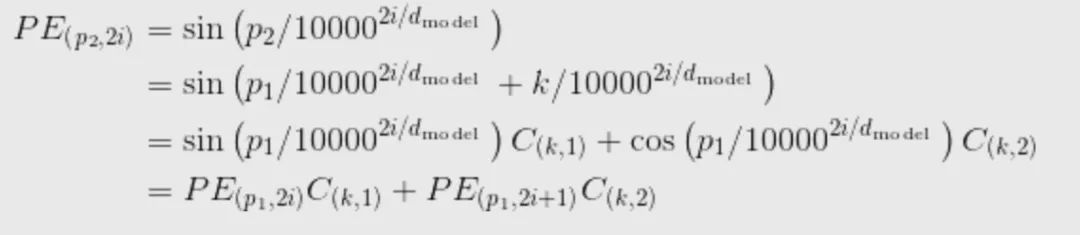
类似地,![]()
这样一来,上述位置编码不仅表示了词的位置信息,还使位置特征具有了一定的周期性。位置编码的另一个优点是,即使测试集中出现了超过训练集文本长度的样本,这种编码方式仍然可以获得有效的相对位置表示。此外,使用这种位置编码时,在模型中加入位置信息只需要简单的相加操作即可,不会给模型增加过大的负担。 以下是使用 Pytorch 实现的 PositionEncoder 的代码:
class PositionalEncoder(nn.Module):
def __init__(self, d_model, max_seq_len = 80):
super().__init__()
self.d_model = d_model
# 根据pos和i创建一个常量pe矩阵
pe = torch.zeros(max_seq_len, d_model)
for pos in range(max_seq_len):
for i in range(0, d_model, 2):
pe[pos, i] = \
math.sin(pos / (10000 ** ((2 * i)/d_model)))
pe[pos, i + 1] = \
math.cos(pos / (10000 ** ((2 * (i + 1))/d_model)))
pe = pe.unsqueeze(0)
self.register_buffer('pe', pe)
def forward(self, x):
# 让 embeddings vector 相对大一些
x = x * math.sqrt(self.d_model)
# 增加位置常量到 embedding 中
seq_len = x.size(1)
x = x + Variable(self.pe[:,:seq_len], \
requires_grad=False).cuda()
return x
```
上面的这个模块中,我们在数据的 embedding vector 增加了 position encoding 的信息。
让 embeddings vector 在增加 postion encoing 之前相对大一些的操作,主要是为了让position encoding 相对的小,这样会让原来的 embedding vector 中的信息在和 position encoding 的信息相加时不至于丢失掉。
#怎么用 Pytorch/Tensorflow2.0 实现在 Transfomer 中的self-attention
实现Transformer中的self-attention过程,我们一共有8个步骤:
##### 1.准备输入
为了简单起见,我们使用3个输入,每个输入都是一个4维的向量。
Input 1: [1, 0, 1, 0]
Input 2: [0, 2, 0, 2]
Input 3: [1, 1, 1, 1]
##### 2. 初始化参数
每一个输入都有三个表示,分别为key(橙黄色)query(红色)value(紫色)。比如说,每一个表示我们希望是一个3维的向量。由于输入是4维,所以我们的参数矩阵为 4X3 维。
*后面我们会看到,value的维度,同样也是我们输出的维度。*
为了能够获取这些表示,每一个输入(绿色)要和key,query和value相乘,在我们例子中,我们使用如下的方式初始化这些参数。
key的参数:
[[0, 0, 1],
[1, 1, 0],
[0, 1, 0],
[1, 1, 0]]
query的参数:
[[1, 0, 1],
[1, 0, 0],
[0, 0, 1],
[0, 1, 1]]
value的参数:
[[0, 2, 0],
[0, 3, 0],
[1, 0, 3],
[1, 1, 0]]
通常在神经网络的初始化过程中,这些参数都是比较小的,一般会在Gaussian, Xavier and Kaiming distributions随机采样完成。
##### 3. 获取key,query和value
现在我们有了三个参数,现在就让我们来获取实际上的key,query和value。
对于input1的key的表示为:
[0, 0, 1]
[1, 0, 1, 0] x [1, 1, 0] = [0, 1, 1]
[0, 1, 0]
[1, 1, 0]
使用相同的参数获取input2的key的表示:
[0, 0, 1]
[0, 2, 0, 2] x [1, 1, 0] = [4, 4, 0]
[0, 1, 0]
[1, 1, 0]
使用参数获取input3的key的表示:
[0, 0, 1]
[1, 1, 1, 1] x [1, 1, 0] = [2, 3, 1]
[0, 1, 0]
[1, 1, 0]
那使用向量化的表示为:
[0, 0, 1]
[1, 0, 1, 0] [1, 1, 0] [0, 1, 1]
[0, 2, 0, 2] x [0, 1, 0] = [4, 4, 0]
[1, 1, 1, 1] [1, 1, 0] [2, 3, 1]
让我们对value做相同的事情。
[0, 2, 0]
[1, 0, 1, 0] [0, 3, 0] [1, 2, 3]
[0, 2, 0, 2] x [1, 0, 3] = [2, 8, 0]
[1, 1, 1, 1] [1, 1, 0] [2, 6, 3]
query也是一样的。
[1, 0, 1]
[1, 0, 1, 0] [1, 0, 0] [1, 0, 2]
[0, 2, 0, 2] x [0, 0, 1] = [2, 2, 2]
[1, 1, 1, 1] [0, 1, 1] [2, 1, 3]
在我们实际的应用中,有可能会在点乘后,加上一个bias的向量。
##### 4. 给input1计算attention score
为了获取input1的attention score,我们使用点乘来处理所有的key和query,包括它自己的key和value。这样我们就能够得到3个key的表示(因为我们有3个输入),我们就获得了3个attention score(蓝色)。
[0, 4, 2]
[1, 0, 2] x [1, 4, 3] = [2, 4, 4]
[1, 0, 1]
这里我们需要注意一下,这里我们只有input1的例子。后面,我们会对其他的输入的query做相同的操作。
##### 5. 计算softmax
给attention score应用softmax。
softmax([2, 4, 4]) = [0.0, 0.5, 0.5]
#####6. 给value乘上score
使用经过softmax后的attention score乘以它对应的value值(紫色),这样我们就得到了3个weighted values(黄色)。
1: 0.0 * [1, 2, 3] = [0.0, 0.0, 0.0]
2: 0.5 * [2, 8, 0] = [1.0, 4.0, 0.0]
3: 0.5 * [2, 6, 3] = [1.0, 3.0, 1.5]
#####7. 给value加权求和获取output1
把所有的weighted values(黄色)进行element-wise的相加。
[0.0, 0.0, 0.0]
+ [1.0, 4.0, 0.0]
+ [1.0, 3.0, 1.5]
-----------------
= [2.0, 7.0, 1.5]
得到结果向量[2.0, 7.0, 1.5](深绿色)就是ouput1的和其他key交互的query representation。
##### 8. 重复步骤4-7,获取output2,output3
#####现在,我们已经完成output1的全部计算,我们要对input2和input3也重复的完成步骤4~7的计算。这相信大家自己是可以实现的。
实现的代码,我给大家准备了jupyter notebook,大家可以clone下面的repo,自己一步步的完成代码的调试,加深对于self-attention的理解。
# 完整的 Transformer Block 是什么样的?
Transformer 模型来源于Google发表的一篇论文 “Attention Is All You Need”,这篇文章非常有名。
图中有个 Nx 的符号,这表示了右侧的结构可以被 N 次堆叠,这就像是我们在使用神经网络的时候,可以 N 次堆叠 layer 一样,通常我们把这样的一种**由多个 layer 组成的模块叫做 block**,这种 block 就是一种比 layer **更大规模的可复用单元**。那么,接下来我们把重点放到 Transformer Block 上。
在这样一个block中,是由几个重要的组件构成的:
self-attention layer
normalization layer
feed forward layer
another normalization layer
在这样四个组件中的两个 normalization layer 之前,使用了残差网络(Residula connections)进行了连接。实际上,这几个组件之间的顺序并没有被完全的定死,这里面最重要的事情是,要联合使用 self-attention 和 feed forward layer,并且要在它们之间增加normalization 和 residual connections。
**Normaliztion 和 residual connections 是我们经常使用的,帮助加快深度神经网络训练速度和准确率的 tricks**。
```py
class TransformerBlock(nn.Module):
def __init__(self, k, heads):
super().__init__()
self.attention = SelfAttention(k, heads=heads)
self.norm1 = nn.LayerNorm(k)
self.norm2 = nn.LayerNorm(k)
self.ff = nn.Sequential(
nn.Linear(k, 4 * k),
nn.ReLU(),
nn.Linear(4 * k, k))
def forward(self, x):
attended = self.attention(x)
x = self.norm1(attended + x)
fedforward = self.ff(x)
return self.norm2(fedforward + x)
我们这里主观的选择4倍输入大小作为我们 feedforward 层的维度,这个值使用的越小就越节省内存,但是相应的表示性也会变弱;但是,最小也应该大于我们输入的维度。
怎么用 Pytorch 实现一个完整的 Transformer 模型?
1. Tokenize
首先,我们要对输入的语句做分词,这里我使用 spacy 来完成这件事,你也可以选择你喜欢的工具来做。
class Tokenize(object):
def __init__(self, lang):
self.nlp = importlib.import_module(lang).load()
def tokenizer(self, sentence):
sentence = re.sub(
r"[\*\"“”\n\\…\+\-\/\=\(\)‘•:\[\]\|’\!;]", " ", str(sentence))
sentence = re.sub(r"[ ]+", " ", sentence)
sentence = re.sub(r"\!+", "!", sentence)
sentence = re.sub(r"\,+", ",", sentence)
sentence = re.sub(r"\?+", "?", sentence)
sentence = sentence.lower()
return [tok.text for tok in self.nlp.tokenizer(sentence) if tok.text != " "]
```
##### 2. Input Embedding.
给语句分词后,我们就得到了一个个的 token,我们之前有说过,要对这些token做向量化的表示,这里我们使用 pytorch 中torch.nn.Embedding 让模型学习到这些向量。
```py
class Embedding(nn.Module):
def __init__(self, vocab_size, d_model):
super().__init__()
self.d_model = d_model
self.embed = nn.Embedding(vocab_size, d_model)
def forward(self, x):
return self.embed(x)
3. Positional Encoder
前文中,我们有说过,要把 token 在句子中的顺序也加入到模型中,让模型进行学习。这里我们使用的是 position encodings 的方法。
class PositionalEncoder(nn.Module):
def __init__(self, d_model, max_seq_len = 80):
super().__init__()
self.d_model = d_model
# 根据pos和i创建一个常量pe矩阵
pe = torch.zeros(max_seq_len, d_model)
for pos in range(max_seq_len):
for i in range(0, d_model, 2):
pe[pos, i] = \
math.sin(pos / (10000 ** ((2 * i)/d_model)))
pe[pos, i + 1] = \
math.cos(pos / (10000 ** ((2 * (i + 1))/d_model)))
pe = pe.unsqueeze(0)
self.register_buffer('pe', pe)
def forward(self, x):
# 让 embeddings vector 相对大一些
x = x * math.sqrt(self.d_model)
# 增加位置常量到 embedding 中
seq_len = x.size(1)
x = x + Variable(self.pe[:,:seq_len], \
requires_grad=False).cuda()
return x```
##### 4. Transformer Block
* self-attention layer
* normalization layer
* feed forward layer
* another normalization layer
* 它们之间使用残差网络进行连接
```py
def attention(q, k, v, d_k, mask=None, dropout=None):
scores = torch.matmul(q, k.transpose(-2, -1)) / math.sqrt(d_k)
# mask掉那些为了padding长度增加的token,让其通过softmax计算后为0
if mask is not None:
mask = mask.unsqueeze(1)
scores = scores.masked_fill(mask == 0, -1e9)
scores = F.softmax(scores, dim=-1)
if dropout is not None:
scores = dropout(scores)
output = torch.matmul(scores, v)
return output
```
这个 attention 的代码中,使用 mask 的机制,这里主要的意思是因为在去给文本做 batch化的过程中,需要序列都是等长的,不足的部分需要 padding。但是这些 padding 的部分,我们并不想在计算的过程中起作用,所以使用 mask 机制,将这些值设置成一个非常大的负值,这样才能让 softmax 后的结果为0。关于 mask 机制,在 Transformer 中有 attention、encoder 和 decoder 中,有不同的应用,我会在后面的文章中进行解释。
```py
class MultiHeadAttention(nn.Module):
def __init__(self, heads, d_model, dropout = 0.1):
super().__init__()
self.d_model = d_model
self.d_k = d_model // heads
self.h = heads
self.q_linear = nn.Linear(d_model, d_model)
self.v_linear = nn.Linear(d_model, d_model)
self.k_linear = nn.Linear(d_model, d_model)
self.dropout = nn.Dropout(dropout)
self.out = nn.Linear(d_model, d_model)
def forward(self, q, k, v, mask=None):
bs = q.size(0)
# perform linear operation and split into N heads
k = self.k_linear(k).view(bs, -1, self.h, self.d_k)
q = self.q_linear(q).view(bs, -1, self.h, self.d_k)
v = self.v_linear(v).view(bs, -1, self.h, self.d_k)
# transpose to get dimensions bs * N * sl * d_model
k = k.transpose(1,2)
q = q.transpose(1,2)
v = v.transpose(1,2)
# calculate attention using function we will define next
scores = attention(q, k, v, self.d_k, mask, self.dropout)
# concatenate heads and put through final linear layer
concat = scores.transpose(1,2).contiguous()\
.view(bs, -1, self.d_model)
output = self.out(concat)
return output
```
Layer Norm
这里使用 Layer Norm 来使得梯度更加的平稳,关于为什么选择 Layer Norm 而不是选择其他的方法,有篇论文对此做了一些研究,Rethinking Batch Normalization in Transformers,对这个有兴趣的可以看看这篇文章。
```py
class NormLayer(nn.Module):
def __init__(self, d_model, eps = 1e-6):
super().__init__()
self.size = d_model
# 使用两个可以学习的参数来进行 normalisation
self.alpha = nn.Parameter(torch.ones(self.size))
self.bias = nn.Parameter(torch.zeros(self.size))
self.eps = eps
def forward(self, x):
norm = self.alpha * (x - x.mean(dim=-1, keepdim=True)) \
/ (x.std(dim=-1, keepdim=True) + self.eps) + self.bias
return norm```
**Feed Forward Layer**
```py
class FeedForward(nn.Module):
def __init__(self, d_model, d_ff=2048, dropout = 0.1):
super().__init__()
# We set d_ff as a default to 2048
self.linear_1 = nn.Linear(d_model, d_ff)
self.dropout = nn.Dropout(dropout)
self.linear_2 = nn.Linear(d_ff, d_model)
def forward(self, x):
x = self.dropout(F.relu(self.linear_1(x)))
x = self.linear_2(x)```
##### 5. Encoder
Encoder 就是将上面讲解的内容,按照下图堆叠起来,完成将源编码到中间编码的转换。
```py
class EncoderLayer(nn.Module):
def __init__(self, d_model, heads, dropout=0.1):
super().__init__()
self.norm_1 = Norm(d_model)
self.norm_2 = Norm(d_model)
self.attn = MultiHeadAttention(heads, d_model, dropout=dropout)
self.ff = FeedForward(d_model, dropout=dropout)
self.dropout_1 = nn.Dropout(dropout)
self.dropout_2 = nn.Dropout(dropout)
def forward(self, x, mask):
x2 = self.norm_1(x)
x = x + self.dropout_1(self.attn(x2,x2,x2,mask))
x2 = self.norm_2(x)
x = x + self.dropout_2(self.ff(x2))
return x
class Encoder(nn.Module):
def __init__(self, vocab_size, d_model, N, heads, dropout):
super().__init__()
self.N = N
self.embed = Embedder(vocab_size, d_model)
self.pe = PositionalEncoder(d_model, dropout=dropout)
self.layers = get_clones(EncoderLayer(d_model, heads, dropout), N)
self.norm = Norm(d_model)
def forward(self, src, mask):
x = self.embed(src)
x = self.pe(x)
for i in range(self.N):
x = self.layers[i](x, mask)
return self.norm(x)```
##### 6. Decoder
Decoder部分和 Encoder 的部分非常的相似,它主要是把 Encoder 生成的中间编码,转换为目标编码。后面我会在具体的任务中,来分析它和 Encoder 的不同
```py
class DecoderLayer(nn.Module):
def __init__(self, d_model, heads, dropout=0.1):
super().__init__()
self.norm_1 = Norm(d_model)
self.norm_2 = Norm(d_model)
self.norm_3 = Norm(d_model)
self.dropout_1 = nn.Dropout(dropout)
self.dropout_2 = nn.Dropout(dropout)
self.dropout_3 = nn.Dropout(dropout)
self.attn_1 = MultiHeadAttention(heads, d_model, dropout=dropout)
self.attn_2 = MultiHeadAttention(heads, d_model, dropout=dropout)
self.ff = FeedForward(d_model, dropout=dropout)
def forward(self, x, e_outputs, src_mask, trg_mask):
x2 = self.norm_1(x)
x = x + self.dropout_1(self.attn_1(x2, x2, x2, trg_mask))
x2 = self.norm_2(x)
x = x + self.dropout_2(self.attn_2(x2, e_outputs, e_outputs, \
src_mask))
x2 = self.norm_3(x)
x = x + self.dropout_3(self.ff(x2))
return x
class Decoder(nn.Module):
def __init__(self, vocab_size, d_model, N, heads, dropout):
super().__init__()
self.N = N
self.embed = Embedder(vocab_size, d_model)
self.pe = PositionalEncoder(d_model, dropout=dropout)
self.layers = get_clones(DecoderLayer(d_model, heads, dropout), N)
self.norm = Norm(d_model)
def forward(self, trg, e_outputs, src_mask, trg_mask):
x = self.embed(trg)
x = self.pe(x)
for i in range(self.N):
x = self.layers[i](x, e_outputs, src_mask, trg_mask)
return self.norm(x)```
##### 7. Transformer
```py
class Transformer(nn.Module):
def __init__(self, src_vocab, trg_vocab, d_model, N, heads, dropout):
super().__init__()
self.encoder = Encoder(src_vocab, d_model, N, heads, dropout)
self.decoder = Decoder(trg_vocab, d_model, N, heads, dropout)
self.out = nn.Linear(d_model, trg_vocab)
def forward(self, src, trg, src_mask, trg_mask):
e_outputs = self.encoder(src, src_mask)
d_output = self.decoder(trg, e_outputs, src_mask, trg_mask)
output = self.out(d_output)
return output```
推荐阅读
2. 图与神经网络-图与学习
加入学习交流群

加入微信学习交流请扫描助手二维码:














 1987
1987











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









