







Transformer 与 Attention的一些Trick
位置编码
由于Transformer没有用到CNN和RNN,因此,句子单词之间的位置信息就没有利用到。显然,这些信息对于翻译来说是非常有用的,同样一句话,每个单词的意思能够准确的翻译出来,但如果顺序不对,表达出来的意思就截然不同了。举个栗子感受一下,原句:”A man went through the Big Buddhist Temple“, 翻译成:”人过大佛寺“和”寺佛大过人“,意思就完全不同了。
他的位置信息主要有两个方面:一是绝对位置,二是相对位置。绝对位置决定了单词在一个序列中的第几个位置,相对位置决定了序列的流向。作者利用了正弦函数和余弦函数来进行位置编码:
P
E
(
p
o
s
,
2
i
)
=
s
i
n
(
p
o
s
/
1000
0
2
i
/
d
model
)
PE_{(pos,2i)} = sin(pos / 10000^{2i/d_{\text{model}}})
PE(pos,2i)=sin(pos/100002i/dmodel)
P
E
(
p
o
s
,
2
i
+
1
)
=
c
o
s
(
p
o
s
/
1000
0
2
i
/
d
model
)
PE_{(pos,2i+1)} = cos(pos / 10000^{2i/d_{\text{model}}})
PE(pos,2i+1)=cos(pos/100002i/dmodel)
pos表示词的词序,2i和2i+1分别表示词特征向量的偶数位置和奇数位置,
d
m
o
d
e
l
d_{model}
dmodel表示特征向量的维数。简单计算一下,特征向量维数为4时,一个句子的第一个词的位置编码如下:
P
E
(
0
,
0
)
=
s
i
n
(
0
)
=
0
PE_{(0,0)} = sin(0)=0
PE(0,0)=sin(0)=0
P
E
(
0
,
1
)
=
c
o
s
(
0
)
=
1
PE_{(0,1)} = cos(0)=1
PE(0,1)=cos(0)=1
P
E
(
0
,
2
)
=
s
i
n
(
0
)
=
0
PE_{(0,2)} = sin(0)=0
PE(0,2)=sin(0)=0
P
E
(
0
,
3
)
=
c
o
s
(
0
)
=
1
PE_{(0,3)} = cos(0)=1
PE(0,3)=cos(0)=1
P
E
0
=
[
0
,
1
,
0
,
1
]
PE_{0}=[0,1,0,1]
PE0=[0,1,0,1]
简而言之,特征向量的偶数位置元素使用的时正弦函数,奇数位置使用余弦函数计算,如下图所示,特征向量维数为64的情况下,前10个词位置编码示意图。
 这个位置编码是与绝对位置相关的,如果改变语序,但是不改变语义,如下面两句话:
这个位置编码是与绝对位置相关的,如果改变语序,但是不改变语义,如下面两句话:
开饭了,妈妈在楼下喊道
妈妈在楼下喊道,开饭了
同样的语义,如果调换了两个子句的语序,则每个词的位置编码截然不。下面证明使用三角函数的绝对编码是可以学习到相对位置信息的。下面是《预训练语言模型》上的推理公式:

推导公式使用了最核心的变换公式就是三角变换公式:
c
o
s
(
x
−
y
)
=
s
i
n
(
x
)
s
i
n
(
y
)
+
c
o
s
(
x
)
c
o
s
(
y
)
cos(x-y)=sin(x)sin(y)+cos(x)cos(y)
cos(x−y)=sin(x)sin(y)+cos(x)cos(y)
因此,利用三角函数构造的绝对位置编码,其实引入了相对位置关系,故前面例子中调换了两个子句的语序并不会对位置编码造成干扰。cos函数是轴对称函数,无论k是正数还是负数,都不会影响
P
T
t
T
P
E
t
+
k
PT_t^TPE_{t+k}
PTtTPEt+k的结果。
需要注意的是:由三角函数构造的绝对位置编码引入的位置关系只考虑词间的距离,不考虑词的前后顺序。后续学术界对这一位置编码做了改进,使用了相对位置编码。
残差连接
sublayer有两个,一个是多头self-attention层,另一个是前馈网络(feed_forward)。输入x先进入多头self-attention,用一个残差网络加成,接着通过前馈网络, 再用一个残差网络加成。


- 输入 x x x
- x x x做一个层归一化: x 1 = n o r m ( x ) x_1 = norm(x) x1=norm(x)
- 进入多头self-attention: x 2 = s e l f _ a t t n ( x 1 ) x_2 = self\_attn(x_1) x2=self_attn(x1)
- 残差加成: x 3 = x + x 2 x_3 = x + x_2 x3=x+x2
- 再做个层归一化: x 4 = n o r m ( x 3 ) x_4 = norm(x_3) x4=norm(x3)
- 经过前馈网络: x 5 = f e e d f o r w a r d ( x 4 ) x_5 = feed_forward(x_4) x5=feedforward(x4)
- 残差加成: x 6 = x 3 + x 5 x_6 = x_3 + x_5 x6=x3+x5
- 输出 x 6 x_6 x6
单向掩码:另一种掩码机制
Mask机制,其本意是消除由于句子长度不一致而衍生的Padding字符对特征提取过程的噪声干扰。其中有另一种Mask机制,其与self-attention实现一致,不仅是Batch训练的衍生算法,更是Decoder在训练时必不可少的模块。
回顾在执行机器翻译任务时Tansformer Decoder模块的输入/输出数据格式。Decoders在预测第
n
+
1
n+1
n+1个词的输入时由两部分组成,第一部分时Encoder的输出,第二部分是已经完成预测的前
n
n
n个词。假设源端语句的长度为
L
s
L_s
Ls,目标端译文的长度是
L
t
L_t
Lt,设Encoder的输出为
z
i
(
i
=
1
,
2
,
.
.
.
.
L
s
)
z_i(i=1,2,....L_s)
zi(i=1,2,....Ls),设目标端译文为
y
j
(
j
=
1
,
2...
L
t
)
y_j(j=1,2...L_t)
yj(j=1,2...Lt),在训练时,以参考译文的前
n
n
n个词作为Decoders的输入训练,把Decoders抽象为一个F函数,可以得知,Decoders预测第
n
+
1
n+1
n+1个词的Loss为
L
o
s
s
n
+
1
=
F
(
z
i
(
i
=
1
,
2
,
3....
L
s
)
,
y
j
(
j
=
1
,
2...
n
)
)
Loss_{n+1}=F(z_i(i=1,2,3....L_s),y_j(j=1,2...n))
Lossn+1=F(zi(i=1,2,3....Ls),yj(j=1,2...n))
则一个训练语句对整体Loss为:
L
o
s
s
=
∑
n
=
0
L
t
L
o
s
s
n
=
∑
n
=
0
L
t
F
(
z
i
(
i
=
1
,
2
,
.
.
.
,
L
s
)
,
y
j
(
j
=
1
,
2
,
.
.
,
n
−
1
)
)
Loss=\sum_{n=0}^{L_t}{Loss_n}=\sum_{n=0}^{L_t}{F(z_i(i=1,2,...,L_s),y_j(j=1,2,..,n-1))}
Loss=n=0∑LtLossn=n=0∑LtF(zi(i=1,2,...,Ls),yj(j=1,2,..,n−1))
实际上,在训练过程中,一般以Batch为单位进行训练,Decoder接受的是由多个完整句子组成,带有Padding字符的固定长度的矩阵,即输入的目标端译文为
y
j
(
j
=
1
,
2
,
.
.
.
,
L
t
)
y_j(j=1,2,...,L_t)
yj(j=1,2,...,Lt)。添加Mask矩阵的目的是:在输入全量的目标端译文时,利用Mask矩阵实现译文目标端部分可见的效果。保证了逻辑推导的因果性,即:
L
o
s
s
=
∑
n
=
0
L
t
L
o
s
s
n
=
∑
n
=
0
L
t
F
(
z
i
(
i
=
1
,
2
,
.
.
.
,
L
s
)
,
y
j
(
j
=
1
,
2
,
.
.
,
n
−
1
)
)
=
∑
n
=
0
L
t
F
(
z
i
(
i
=
1
,
2
,
.
.
.
,
L
s
)
,
y
j
(
j
=
1
,
2
,
.
.
,
n
−
1
)
,
M
a
s
k
)
Loss = \sum_{n=0}^{L_t}{Loss_n} = \sum_{n=0}^{L_t}{F(z_i(i=1,2,...,L_s),y_j(j=1,2,..,n-1))}=\sum_{n=0}^{L_t}{F(z_i(i=1,2,...,L_s),y_j(j=1,2,..,n-1),Mask)}
Loss=n=0∑LtLossn=n=0∑LtF(zi(i=1,2,...,Ls),yj(j=1,2,..,n−1))=n=0∑LtF(zi(i=1,2,...,Ls),yj(j=1,2,..,n−1),Mask)
层归一化前置和梯度累计
层归一化前置和梯度累计是两个提升模型训练速度和收敛稳定性的训练技巧.
层归一化前置
BatchNormalization的出现无疑是广大AI调参侠的福音,将大家从繁琐的权重初始化、学习率调节中释放出来。它不仅能够大大加快收敛速度,还自带正则化功能,是Google 2015年提出的。
归一化层在计算机视觉领域常以BN层形式出现,在自然语言处理领域常以LN层的形式出现,两者的目的是一样的,都是使用Batch Size的样本的均值和方差近似整体样本的均值和方差,独立地规范每一个维度的输入数据。

- 对Batch Size非常敏感。BatchNormalization的一个重要出发点是保持每层输入的数据同分布。回想下开始那个独立同分布的假设。假如取的batch_size很小,那显然有些Mini-Batch的数据分布就很可能与整个数据集的分布不一致了,又出现了那个问题,数据分布不一致,这就等于说没起到同分布的作用了,或者说同分布得不充分。实验也证明,Batch Size取得大一点, 数据shuffle的好一点,BatchNormalization的效果就越好。
- 不能很方便地用于RNN。这其实是第一个问题的引申。我们再来看一下上图中的均值和方差的计算公式。对所有样本求均值。对于图片这类等长的输入来说,这很容易操作,在每个维度加加除除就可以了,因为维度总是一致的。而对于不等长的文本来说,RNN中的每个time step共享了同一组权重。在应用BatchNormalization时,这就要求对每个time step的Batch Size个输入计算一个均值和方差。那么问题就来了,假如有一个句子S非常长,那就意味着对S而言,总会有个time_step的Batch Size为1,均值方差没意义,这就导致了BatchNormalization在RNN上无用武之地了
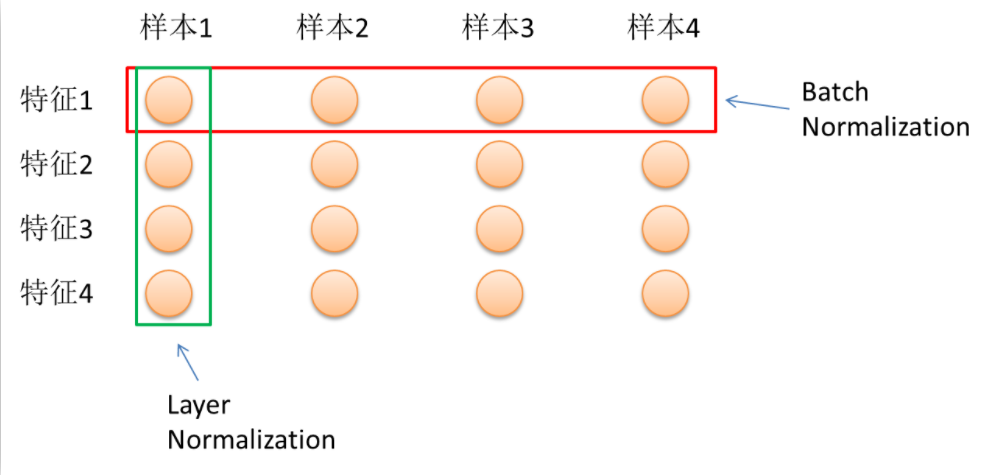 LayerNormalization的主要变化在于:
LayerNormalization的主要变化在于:
- 不再对Mini-Batch中的N的样本在各个维度做归一化,而是针对同一层的所有神经元做归一化。归一化公式为:
μ
1
=
1
H
∑
H
1
α
i
1
\mu ^1 = \frac {1}{H} \sum _{H} ^{1}{\alpha _i ^1}
μ1=H1∑H1αi1
σ 1 = 1 H ∑ H 1 ( α i 1 − μ i 1 ) \sigma ^1 = \sqrt{\frac {1} {H} { \sum _{H} ^{1} (\alpha _i ^1 - \mu _i ^1)}} σ1=H1∑H1(αi1−μi1)
其中,H指的是一层神经网络的神经元个数。我们再回想下BatchNormalization,其实它是在每个神经元上对batch_size个数据做归一化,每个神经元的均值和方差均不相同。而LayerNormalization则是对所有神经元做一个归一化,这就跟batch_size无关了。哪怕batch_size为1,这里的均值和方差只和神经元的个数有关系 - 测试的时候可以直接利用LN,所以训练时不用保存均值和方差,这节省了内存空间
其次,介绍学习率预热算法。该算法核心思想是在训练前期,使用小学习率,等模型收敛到一定程度后在使用正常设定的学习率进行训练。该算法的核心逻辑依然是保证在训练前期,模型的梯度能在一个可控的范围内变化,不至于在训练前期就 让模型陷入局部收敛点,从而影响后期训练。
归一化层与学习率预热算法的目的是一样的,即保证模型的梯度在训练过程中保持在合理的范围内。只不过归一化让深层网络的权重收敛稳定,学习率预热算法让权重在训练前期收敛。
梯度累积
近年,随着深度学习的发展,模型的参数量越来越多,收敛难度越来越大,而硬件能力的提升远不如参数量的提升快。在一定范围内,Batch Size越大,根据局部数据求得的梯度方向越接近全局的梯度优化方向,因此,为了让模型在训练过程中的梯度方向更稳定,采用一个较大的Batch Size 是非常有必要的。令人尴尬的是,现有的GPU加载一个深度模型后,剩余的显存无法容纳很多的训练数据,即硬件不支持较大的Batch Size。最直接的改善方法是使用分布式训练,通过增加硬件资源来变相增大Batch Size。而通过一个时间换空间的措施——将多个Batch训练数据的梯度进行累积,也能达到一个较大Batch Size的效果。
欢迎关注公众号:















 399
399











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









