







k近邻分类算法
k近邻分类算法,即k-NN算法,可以说是最简单的机器学习算法。
核心思想就是,通过测量预测的数据点与已训练数据点之间距离,寻找距离最近的已训练数据点(最近的训练数据点个数由算法使用者自己指定,适中即可)的标签结果,即为测试数据点的预测结果。
K = 1时的预测情况
可见下图:
import mglearn
# n_neighbors = 1,这里指定 k-NN 算法的最近近邻数据点的个数 n = 1,绘图
mglearn.plots.plot_knn_classification(n_neighbors=1)
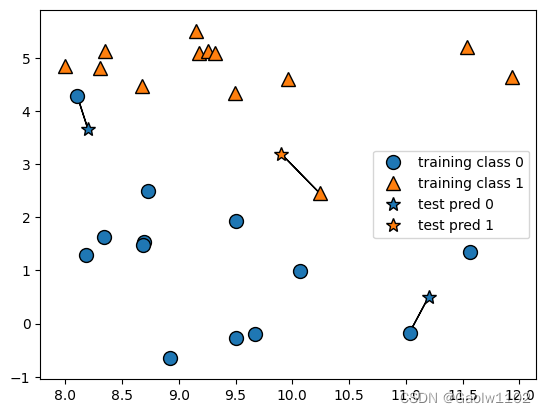
其中三个预测点(五角星标识test pred),分别找到了与它们最近的一个已训练数据点,并根据近邻训练点的结果,得到预测结果。
k = 3 时的预测情况
在考虑多余一个邻居的情况下,使用投票法(voting)来指定标签,即出现次数更多的类别作为预测结果。
可见下图:
import mglearn
# n_neighbors = 3,这里指定 k-NN 算法的最近近邻数据点的个数 n = 3,绘图
mglearn.plots.plot_knn_classification(n_neighbors=3)
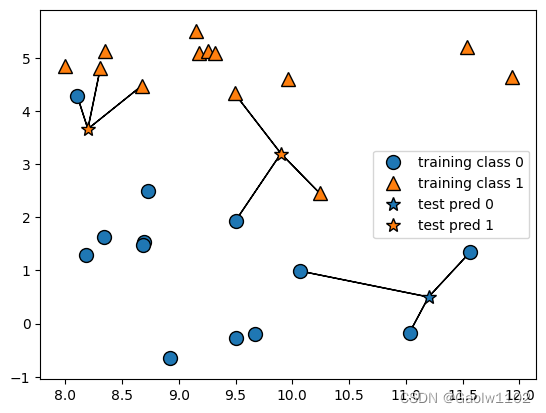
同上图,预测结果也可以从五角星的颜色中得出,可得,当邻居个数不同时,预测结果也会不同。
k = 5 时的预测情况
可见下图:
import mglearn
# n_neighbors = 5,这里指定 k-NN 算法的最近近邻数据点的个数 n = 5,绘图
mglearn.plots.plot_knn_classification(n_neighbors=5)
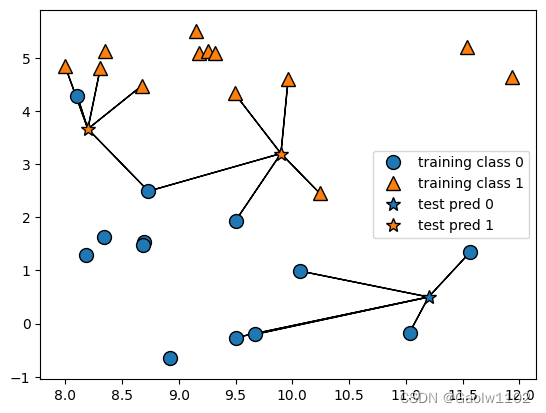
可见,预测需要考虑的情况越来越复杂。
那么是否是选定邻居越多时预测越准确呢?
答案是否定的,我们可以使用鸢尾花分类这个案例对 k-NN 算法进行分析。
实战----鸢尾花分类(不同k值对预测值的影响)
from IPython.display import display
from sklearn.datasets import load_iris # 加载sklearn默认的数据集
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
import matplotlib.pyplot as plt
import numpy as np
# 获取 iris 数据集内容
iris_dataset = load_iris()
# 其中X_train, y_train表示训练集的数据与标签, X_test,y_test表示测试集的数据与标签,返回值均为 numpy 数组
X_train, X_test, y_train, y_test = train_test_split(iris_dataset['data'], iris_dataset['target'], random_state=0)
print('X_train shape: {}'.format(X_train.shape))
print('y_train shape: {}'.format(y_train.shape))
print('X_test shape: {}'.format(X_test.shape))
print('y_test shape: {}'.format(y_test.shape))
print('--------------------------------------')
train_pres = []
test_pres = []
# 通过循环 来判断随着邻居个数的增加,预测准确率的变化
for i in range(1, 39):
knn = KNeighborsClassifier(n_neighbors=i)
knn.fit(X_train, y_train)
train_pre = knn.score(X_train, y_train)
test_pre = knn.score(X_test, y_test)
train_pres.append(train_pre) #将训练集的预测结果追加到训练集预测结果列表中
test_pres.append(test_pre) #将测试集的预测结果追加到测试集预测结果列表中
train_pre_points = np.array(train_pres)
test_pre_points = np.array(test_pres)
# 通过绘图展示随着 k 的变大,训练集与测试集精确度的变化
plt.plot(train_pre_points, '.-r') #红色的线条代表训练集的精确度变化
plt.plot(test_pre_points, '.-g') #绿色的线条代表测试集的精确度变化
X_train shape: (112, 4)
y_train shape: (112,)
X_test shape: (38, 4)
y_test shape: (38,)
--------------------------------------
[<matplotlib.lines.Line2D at 0x2a2702c60b8>]
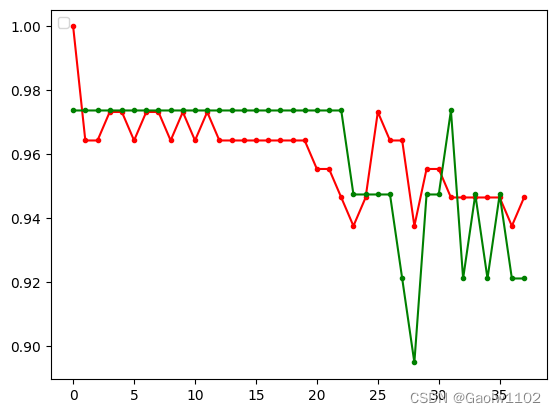
由此可知,当k的值变大时,预测的精确度不一定会更加精准,甚至会精度降低。
所以在 k-NN算法中,对于k的取值,要根据情况实时调整,才能保证模型预测的准确率。
总结
k-NN算法的最显著的有点就是容易理解、模型构建快,不需要过多调节就能得到不错的效果。
但缺点是不能处理过多特征的数据集,另外对于稀疏矩阵的处理尤其不好,所以在实践中用到的往往很少。
















 4184
4184











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











