







导读:使用分类模型预测类标签。
作者:阿迪蒂亚·夏尔马(Aditya Sharma)、维什韦什·拉维·什里马利(Vishwesh Ravi Shrimali)、迈克尔·贝耶勒(Michael Beyeler)
来源:大数据DT(ID:hzdashuju)

以兰普威尔小镇为例,那里的人们为他们的两支球队——兰普威尔红队和兰普威尔蓝队——而疯狂。红队已经存在很长时间了,人们很喜欢这支队伍。
但是后来,一些外地来的富翁买下了红队的最佳射手,成立了一支新的球队——蓝队。令多数红队球迷不满的是,这位最佳射手将继续带领蓝队夺得冠军。多年后,尽管一些球迷对他早期的职业选择强烈不满,但他还是回到了红队。可是不管怎么说,你会明白为什么红队的球迷和蓝队的球迷一直不能和睦相处。
事实上,这两队的球迷是如此分裂,以至于他们从未在同一处居住过。我们甚至听说过这样的故事:当蓝队球迷搬到隔壁时,红队球迷就会故意离开。故事是真实的!
不管怎样,我们是新到镇上的,我们正挨家挨户向人们推销蓝队产品。然而,我们偶尔会遇到心在滴血的红队球迷因为我们推销蓝队的东西而对我们大吼大叫,还把我们赶出他们的草坪。太不友好了!完全避开这些红队球迷,而只拜访蓝队球迷,这样压力会小很多,我们的时间也能更好地被利用。
我们相信可以预测红队球迷的生活区,开始记录我们的活动轨迹。如果我们路过红队球迷的家,则会在手边的城镇地图上画一个三角形;否则会画一个正方形。一段时间后,我们对每个人的居住地有了一个很好的了解,如图3-3所示。
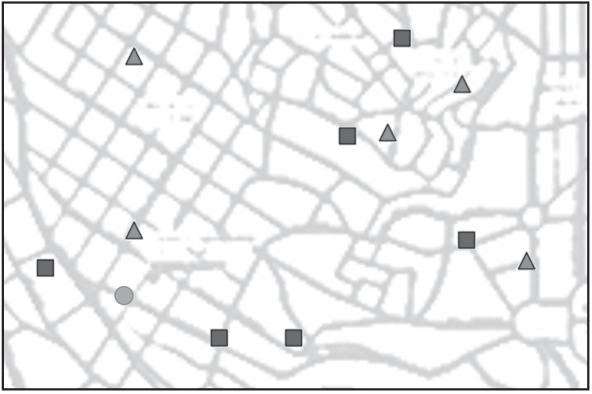
▲图3-3 在地图中标记红队和蓝队球迷居住地
可是,在图3-3中,我们正在靠近一间标记为绿色圆圈的房子。我们应该敲他们的门吗?我们试图找到一些线索,以确定他们可能是哪个队的球迷(也许在后门廊上挂着队旗,可我们没看到)。我们怎样才能知道敲他们的门是安全的呢?
这个例子恰恰描述了监督学习算法可以解决的问题。我们有一堆观测数据(房子、位置以及颜色),这些数据构成了我们的训练数据。我们可以利用这些数据从经验中学习,当我们要对一个新房子进行颜色预测的任务时,我们就可以做出明智的估计。
正如前面说过的那样,红队球迷对他们的球队充满感情,所以他们永远不会和蓝队球迷住在一起。我们能不能利用这些信息,观察一下周围的房子,再看看新房子里住的是哪个队的球迷?
这正是k-NN算法能够实现的。
01 理解k-NN算法
k-NN算法可以说是机器学习算法中最简单的一个。原因是我们基本上只需要存储训练数据集。然后,要预测一个新的数据点,我们只需要找到训练数据集中最近的数据点:它的最近邻居。
简而言之,k-NN算法认为一个数据点可能与其邻居属于同一类。想想看,如果我们的邻居是红队球迷,我们可能也是红队球迷;否则,我们早就搬走了。对于蓝队球迷来说也是如此。
当然,有些邻居可能稍微有点复杂。在这种情况下,我们可能不只要考虑我们的最近邻居(k=1),而且还要考虑离我们最近的k个最近邻居。让我们继续前面介绍过的例子,如果我们是红队球迷,我们不可能搬到大多数人都认为可能是蓝队球迷的社区。
这就是它的全部。
02 用OpenCV实现k-NN
使用OpenCV,通过cv2.ml.KNearest_Create()函数我们可以很容易创建一个k-NN模型。构建模型包括下列步骤:
生成一些训练数据。
对于一个给定的数k,创建一个k-NN对象。
为我们要分类的一个新数据点找到k个最近邻。
根据多数票分配新数据点的类标签。
绘制结果。
首先,我们导入所有必要的模块:OpenCV的k-NN算法模块、NumPy的数据处理模块、Matplotlib的绘图模块。如果你正在使用Jupyter Notebook,请不要忘记调用%matplotlib inline魔术命令:
import numpy as np
import cv2
import matplotlib.pyplot as plt
%matplotlib inlineplt.style.use('ggplot') 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 4809
4809











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









