






1 Introduction
这个部分要完成一个网络的模块化,然后实现一个新的网络结构。
2 使用torch的模块化功能
2.1 模块化
将输入的字符长度变成8,并将之前的代码模块化
# Near copy paste of the layers we have developed in Part 3
# -----------------------------------------------------------------------------------------------
class Linear:
def __init__(self, fan_in, fan_out, bias=True):
self.weight = torch.randn((fan_in, fan_out)) / fan_in**0.5 # note: kaiming init
self.bias = torch.zeros(fan_out) if bias else None
def __call__(self, x):
self.out = x @ self.weight
if self.bias is not None:
self.out += self.bias
return self.out
def parameters(self):
return [self.weight] + ([] if self.bias is None else [self.bias])
# -----------------------------------------------------------------------------------------------
class BatchNorm1d:
def __init__(self, dim, eps=1e-5, momentum=0.1):
self.eps = eps
self.momentum = momentum
self.training = True
# parameters (trained with backprop)
self.gamma = torch.ones(dim)
self.beta = torch.zeros(dim)
# buffers (trained with a running 'momentum update')
self.running_mean = torch.zeros(dim)
self.running_var = torch.ones(dim)
def __call__(self, x):
# calculate the forward pass
if self.training:
if x.ndim == 2:
dim = 0
elif x.ndim == 3:
dim = (0,1)
xmean = x.mean(dim, keepdim=True) # batch mean
xvar = x.var(dim, keepdim=True) # batch variance
else:
xmean = self.running_mean
xvar = self.running_var
xhat = (x - xmean) / torch.sqrt(xvar + self.eps) # normalize to unit variance
self.out = self.gamma * xhat + self.beta
# update the buffers
if self.training:
with torch.no_grad():
self.running_mean = (1 - self.momentum) * self.running_mean + self.momentum * xmean
self.running_var = (1 - self.momentum) * self.running_var + self.momentum * xvar
return self.out
def parameters(self):
return [self.gamma, self.beta]
# -----------------------------------------------------------------------------------------------
class Tanh:
def __call__(self, x):
self.out = torch.tanh(x)
return self.out
def parameters(self):
return []
# -----------------------------------------------------------------------------------------------
class Embedding:
def __init__(self, num_embeddings, embedding_dim):
self.weight = torch.randn((num_embeddings, embedding_dim))
def __call__(self, IX):
self.out = self.weight[IX]
return self.out
def parameters(self):
return [self.weight]
class Flatten:
def __call__(self, x):
self.out = x.view(x.shape[0], -1)
return self.out
def parameters(self):
return []
# -----------------------------------------------------------------------------------------------
class FlattenConsecutive:
def __init__(self, n):
self.n = n
def __call__(self, x):
B, T, C = x.shape
x = x.view(B, T//self.n, C*self.n)
if x.shape[1] == 1:
x = x.squeeze(1)
self.out = x
return self.out
def parameters(self):
return []
# -----------------------------------------------------------------------------------------------
class Sequential:
def __init__(self, layers):
self.layers = layers
def __call__(self, x):
for layer in self.layers:
x = layer(x)
self.out = x
return self.out
def parameters(self):
# get parameters of all layers and stretch them out into one list
return [p for layer in self.layers for p in layer.parameters()]
定义网络结构
block_size = 8
n_emb = 10
n_batch = 32
n_hidden = 200
g = torch.Generator().manual_seed(2147483647)
model = Sequential([
Embedding(vocab_size, n_emb),
Flatten(),
Linear(n_emb * block_size, n_hidden, bias=False),
BatchNorm1d(n_hidden),
Tanh(),
Linear(n_hidden, vocab_size),
])
with torch.no_grad():
model.layers[-1].weight *= 0.1
print(sum(p.nelement() for p in model.parameters()))
for p in model.parameters():
p.requires_grad = True
for layer in model.layers:
if isinstance(layer, BatchNorm1d):
layer.training = True
进行训练
import torch.nn.functional as F
max_iter = 200000
lossi = []
ud = []
for i in range(max_iter):
ix = torch.randint(0, Xtr.shape[0], (n_batch,), generator=g)
Xb, Yb = Xtr[ix], Ytr[ix]
logits = model(Xb)
loss = F.cross_entropy(logits, Yb)
for p in model.parameters():
p.grad = None
loss.backward()
lr = 0.1 if i < 100000 else 0.01
for p in model.parameters():
p.data -= lr * p.grad.data
lossi.append(loss.item())
with torch.no_grad():
ud.append([((-lr * p.grad).std() / p.data.std()).log10().item() for p in model.parameters()])
if i % 1000 == 0:
print(f"Iteration: {i}/{max_iter}, Loss: {loss.item()}")
# break
显示曲线
import matplotlib.pyplot as plt
plt.plot(torch.tensor(lossi).view(-1, 1000).mean(dim=1, keepdim=False))
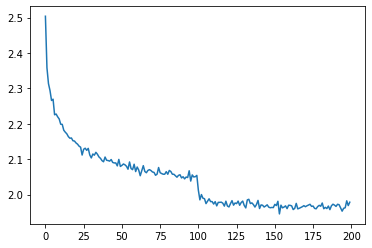
比较训练和测试的误差
@torch.no_grad()
def batch_infer(datasets):
X, Y = {
'train' : (Xtr, Ytr),
'val' : (Xdev, Ydev),
'test' : (Xte, Yte),
}[datasets]
logits = model(X)
loss = F.cross_entropy(logits, Y)
print(f'{datasets}, loss is: {loss}')
for layer in model.layers:
if isinstance(layer, BatchNorm1d):
layer.training = False
batch_infer('train')
batch_infer('val')
train, loss is: 1.926148533821106
val, loss is: 2.028862237930298
网络现在有一点过拟合了。
看一下输出的结果
for _ in range(20):
context = [0] * block_size
ch = []
while(True):
X = torch.tensor([context])
logits = model(X)
probs = torch.softmax(logits, dim=-1).squeeze(0)
ix = torch.multinomial(probs, num_samples=1).item()
context = context[1:] + [ix]
ch.append(itos[ix])
if ix == 0:
break
print(''.join(ch))
quab.
nomawa.
brenne.
sevanille.
razlyn.
zile.
audaina.
zaralynn.
dawsyn.
wyle.
yalikbi.
zuria.
endrame.
mesty.
nooap.
dangele.
ellania.
bako.
memaisee.
zailan.
2.2 加上wavenet
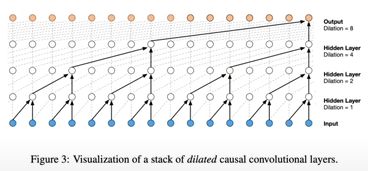
这个图表示,两个点使用相同的参数矩阵C,进行映射。
首先来看矩阵乘法的表示
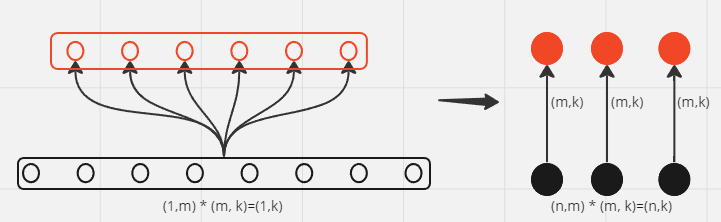
然后再来看我们这个问题,
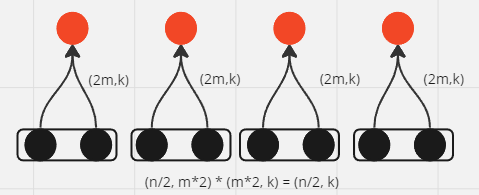
代码表示为:
class FlattenConsecutive:
def __init__(self, n):
self.n = n
def __call__(self, x):
B, T, C = x.shape
x = x.view(B, T//self.n, C*self.n)
if x.shape[1] == 1:
x = x.squeeze(1)
self.out = x
return self.out
def parameters(self):
return []
定义新的完整网络
block_size = 8
n_emb = 24
n_batch = 32
n_hidden = 128
g = torch.Generator().manual_seed(2147483647)
model = Sequential([
Embedding(vocab_size, n_emb),
FlattenConsecutive(2), Linear(n_emb * 2, n_hidden, bias=False), BatchNorm1d(n_hidden), Tanh(),
FlattenConsecutive(2), Linear(n_hidden * 2, n_hidden, bias=False), BatchNorm1d(n_hidden), Tanh(),
FlattenConsecutive(2), Linear(n_hidden * 2, n_hidden, bias=False), BatchNorm1d(n_hidden), Tanh(),
Linear(n_hidden, vocab_size)
])
with torch.no_grad():
model.layers[-1].weight *= 0.1
print(sum(p.nelement() for p in model.parameters()))
for p in model.parameters():
p.requires_grad = True
for layer in model.layers:
if isinstance(layer, BatchNorm1d):
layer.training = True
这里注意一个问题,因为我们采用是batchnormal, 也就是说除了最后一维的数据,其他的数据需要normalize
class BatchNorm1d:
def __init__(self, dim, eps=1e-5, momentum=0.1):
self.eps = eps
self.momentum = momentum
self.training = True
# parameters (trained with backprop)
self.gamma = torch.ones(dim)
self.beta = torch.zeros(dim)
# buffers (trained with a running 'momentum update')
self.running_mean = torch.zeros(dim)
self.running_var = torch.ones(dim)
def __call__(self, x):
# calculate the forward pass
if self.training:
if x.ndim == 2:
dim = 0
elif x.ndim == 3:
dim = (0,1)
xmean = x.mean(dim, keepdim=True) # batch mean
xvar = x.var(dim, keepdim=True) # batch variance
else:
xmean = self.running_mean
xvar = self.running_var
xhat = (x - xmean) / torch.sqrt(xvar + self.eps) # normalize to unit variance
self.out = self.gamma * xhat + self.beta
# update the buffers
if self.training:
with torch.no_grad():
self.running_mean = (1 - self.momentum) * self.running_mean + self.momentum * xmean
self.running_var = (1 - self.momentum) * self.running_var + self.momentum * xvar
return self.out
def parameters(self):
return [self.gamma, self.beta]
其他的内容和之前的网络相同,最后看一下训练的结果
train, loss is: 1.7904815673828125
val, loss is: 1.9868937730789185
sabris.
lilly.
pryce.
antwling.
lakelyn.
dayre.
theora.
hunna.
michael.
amillia.
zivy.
zuri.
florby.
jairael.
aiyank.
anahit.
madelynn.
briani.
payzleigh.
sola.
2.3 convolution
我们只执行了这里的黑色部分的代码,如果完整执行就是一个convolutional neural network。
References
[1] WaveNet 2016 from DeepMind https://arxiv.org/abs/1609.03499















 620
620











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









