




 本文介绍了一个基于FER2013数据集的人脸表情识别深度神经网络模型实现,详细展示了数据预处理、模型搭建、训练及评估过程。
本文介绍了一个基于FER2013数据集的人脸表情识别深度神经网络模型实现,详细展示了数据预处理、模型搭建、训练及评估过程。
目录
写在前面:
- 此代码主要来源于:人脸表情识别 深度神经网络 python实现 简单模型fer2013数据集
- 因为是新手,所以直接拿别人的代码来测试一下这个数据集。 此外,由于本人电脑没有独显,只能CPU跑。
- 原始链接中batch_size 设置为8,由于种种原因我没有测试,只测试了128和512的情况
- 在下面的结果中也可以看到20代大约训练了40分钟靠上。
- 原数据集在kaggle中可以下载:fer2013数据集下载页面,或者在我分享的百度网盘中下载链接:百度网盘分享
提取码:u6so
一:查看fer2013数据集(cvs格式)
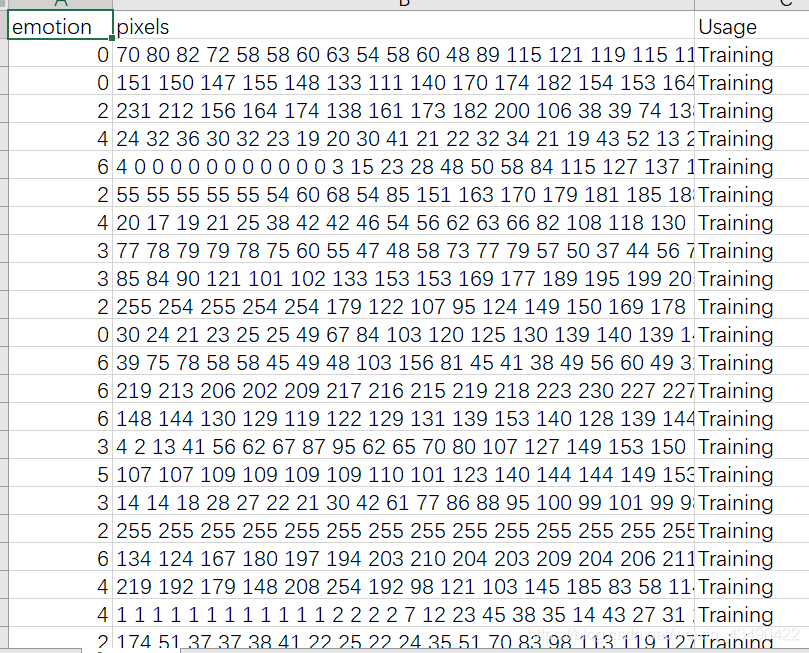
- 每行pixels下有48*48个数据,以空格进行分隔。
- emotion有0-6,分别代表以下意思:
‘anger’,‘disgust’,‘fear’,‘happy’,‘neutral’,‘sad’,‘surprised’ - 整个数据集被分为Training、PrivateTest、PublicTest三个集合,分别对应训练集,验证集,测试集;验证集和测试集的区分可以查看我的另一篇文章:为何需要验证集?
二:使用Pandas读取csv
import numpy as np
import pandas as pd
data = pd.read_csv('C:/Users/24651/Desktop/fer2013.csv')
num_of_instances = len(data) #获取数据集的数量
print("数据集的数量为:",num_of_instances)
pixels = data['pixels']
emotions = data['emotion']
usages = data['Usage']
数据集的数量为: 35887
截止到目前的数据集总量为35887。
三:使用cv2查看其中一张图片
import cv2
img0 = list(map(eval,pixels[0].split(' ')))
np_img0 = np.asarray(img0)
img0 = np_img0.reshape(48,48)
import matplotlib.pyplot as plt
plt.imshow(img0, cmap="gray")

这张图片被分类为生气(anger)
四:将数据集划分
emotions_Str=['anger','disgust','fear','happy','neutral','sad','surprised']
在其中,为了更直观地查看图片,将其转换为png格式,其实在本代码中是没有必要的。
from keras.utils import to_categorical
from PIL import Image
import os
num_classes = 7 #表情的类别数目
x_train,y_train,x_val,y_val,x_test,y_test = [],[],[],[],[],[]
from tqdm import tqdm
for i in tqdm(range(num_of_instances)):
usages_name = usages[i]
emotions_Str_Nmae = emotions_Str[emotions[i]]
one_hot_label = to_categorical(emotions[i],num_classes) #标签转换为one-hot编码,以满足keras对于数据的要求
img = list(map(eval,pixels[i].split(' ')))
np_img = np.asarray(img)
img = np_img.reshape(48,48)
if usages[i] == 'Training':
x_train.append(img)
y_train.append(one_hot_label)
elif usages[i] == 'PrivateTest':
x_val.append(img)
y_val.append(one_hot_label)
else:
x_test.append(img)
y_test.append(one_hot_label)
subfolder = os.path.join('C:\\Users\\24651\\Desktop\\',usages_name,emotions_Str_Nmae)
if not os.path.exists(subfolder):
os.makedirs(subfolder)
im = Image.fromarray(img).convert('L')
im.save(os.path.join(subfolder , (str(i)+'.jpg') ))
100%|████████████████████████████████████████████████████████████████████████████| 35887/35887 [06:10<00:00, 96.91it/s]
len(x_train)
28709
五:将数据转换为数组(array)格式,否则keras会报错
x_train = np.array(x_train)
y_train = np.array(y_train)
x_train = x_train.reshape(-1,48,48,1)
x_test = np.array(x_test)
y_test = np.array(y_test)
x_test = x_test.reshape(-1,48,48,1)
x_val = np.array(x_val).reshape(-1,48,48,1)
y_val = np.array(y_val)
len(x_train),len(x_test),len(x_val)
(28709, 3589, 3589)
六:使用matplotlib显示照片
显示训练集前四张照片(当然也可以直接跳过这一步):
import matplotlib.pyplot as plt
%matplotlib inline
for i in range(4):
plt.subplot(221+i)
plt.gray()
plt.imshow(x_train[i].reshape([48,48]))

x_train.shape[1:]
x_val.shape
(3589, 48, 48, 1)
七:搭建模型
- 本模型:三个block(两层卷积一层最大池化) + Flatten + 全连接层(Dense) + 失活(Dropout) + 全连接层
- Flatten层用来将输入“压平”,即把多维的输入一维化,常用在从卷积层到全连接层的过渡。Flatten不影响batch的大小。
- 做分类的时候,Dropout 层一般加在全连接层 防止过拟合 提升模型泛化能力。
from keras.models import Sequential
from keras.layers import Conv2D, MaxPool2D, Activation, Dropout, Flatten, Dense
from keras.optimizers import Adam
from keras.preprocessing.image import ImageDataGenerator
batch_size = 512
epochs = 20
model = Sequential()
# 第一层
model.add(Conv2D(input_shape=(48, 48, 1), filters=32, kernel_size=3, padding='same', activation='relu'))
model.add(Conv2D(filters=32, kernel_size=3, padding='same', activation='relu'))
model.add(MaxPool2D(pool_size=2, strides=2))
# 第二层
model.add(Conv2D(filters=64, kernel_size=3, padding='same', activation='relu'))
model.add(Conv2D(filters=64, kernel_size=3, padding='same', activation='relu'))
model.add(MaxPool2D(pool_size=2, strides=2))
# 第三层
model.add(Conv2D(filters=128, kernel_size=3, padding='same', activation='relu'))
model.add(Conv2D(filters=128, kernel_size=3, padding='same', activation='relu'))
model.add(MaxPool2D(pool_size=2, strides=2))
model.add(Flatten())
# 全连接层
model.add(Dense(64, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(7, activation='softmax'))
八:查看模型结构图(使用pydot)
注意:以下代码可能会报错,如果出现’pydot’ failed to call GraphViz 的错误,请查看我另一篇文章:‘pydot’ failed to call GraphViz的解决方法
%matplotlib inline
from IPython.display import SVG
from keras.utils.vis_utils import model_to_dot
SVG(model_to_dot(model,show_shapes=True,dpi=60).create(prog='dot',format='svg'))
上述是用svg格式查看,下面我们转换为png格式并保存到本地方便用到其它地方。
from keras.utils import plot_model
plot_model(model,show_shapes= True, to_file='model.png')
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pz9Ugh7m-1587991466732)(output_11_0.png)]](https://i-blog.csdnimg.cn/blog_migrate/c9a317f1d4be655540d0933b7fe833dc.png)
九:开始训练
#进行训练
model.compile(loss = 'categorical_crossentropy',optimizer = Adam(),metrics=['accuracy'])
history = model.fit(x_train,y_train,batch_size=batch_size,epochs=epochs,validation_data=(x_val,y_val))
test_score = model.evaluate(x_test, y_test)
Train on 28709 samples, validate on 3589 samples
Epoch 1/20
28709/28709 [==============================] - 179s 6ms/step - loss: 2.5097 - accuracy: 0.1582 - val_loss: 1.8669 - val_accuracy: 0.2020
Epoch 2/20
28709/28709 [==============================] - 182s 6ms/step - loss: 1.8569 - accuracy: 0.2387 - val_loss: 1.8659 - val_accuracy: 0.1725
Epoch 3/20
28709/28709 [==============================] - 180s 6ms/step - loss: 1.8243 - accuracy: 0.2551 - val_loss: 1.7495 - val_accuracy: 0.3101
Epoch 4/20
28709/28709 [==============================] - 180s 6ms/step - loss: 1.7931 - accuracy: 0.2635 - val_loss: 1.7434 - val_accuracy: 0.2953
Epoch 5/20
28709/28709 [==============================] - 183s 6ms/step - loss: 1.7677 - accuracy: 0.2667 - val_loss: 1.7208 - val_accuracy: 0.3135
Epoch 6/20
28709/28709 [==============================] - 180s 6ms/step - loss: 1.7508 - accuracy: 0.2728 - val_loss: 1.6813 - val_accuracy: 0.3193
Epoch 7/20
28709/28709 [==============================] - 182s 6ms/step - loss: 1.7259 - accuracy: 0.2832 - val_loss: 1.6868 - val_accuracy: 0.3349
Epoch 8/20
28709/28709 [==============================] - 182s 6ms/step - loss: 1.7051 - accuracy: 0.2857 - val_loss: 1.6008 - val_accuracy: 0.3374
Epoch 9/20
28709/28709 [==============================] - 181s 6ms/step - loss: 1.6808 - accuracy: 0.2989 - val_loss: 1.6082 - val_accuracy: 0.3550
Epoch 10/20
28709/28709 [==============================] - 182s 6ms/step - loss: 1.6572 - accuracy: 0.3118 - val_loss: 1.5494 - val_accuracy: 0.3959
Epoch 11/20
28709/28709 [==============================] - 180s 6ms/step - loss: 1.6298 - accuracy: 0.3247 - val_loss: 1.5133 - val_accuracy: 0.4110
Epoch 12/20
28709/28709 [==============================] - 182s 6ms/step - loss: 1.5977 - accuracy: 0.3341 - val_loss: 1.4907 - val_accuracy: 0.4015
Epoch 13/20
28709/28709 [==============================] - 183s 6ms/step - loss: 1.5746 - accuracy: 0.3391 - val_loss: 1.4495 - val_accuracy: 0.4313
Epoch 14/20
28709/28709 [==============================] - 181s 6ms/step - loss: 1.5459 - accuracy: 0.3586 - val_loss: 1.4401 - val_accuracy: 0.4458
Epoch 15/20
28709/28709 [==============================] - 182s 6ms/step - loss: 1.5228 - accuracy: 0.3747 - val_loss: 1.4137 - val_accuracy: 0.4603
Epoch 16/20
28709/28709 [==============================] - 183s 6ms/step - loss: 1.5151 - accuracy: 0.3764 - val_loss: 1.4116 - val_accuracy: 0.4675
Epoch 17/20
28709/28709 [==============================] - 181s 6ms/step - loss: 1.4876 - accuracy: 0.3929 - val_loss: 1.4096 - val_accuracy: 0.4622
Epoch 18/20
28709/28709 [==============================] - 180s 6ms/step - loss: 1.4772 - accuracy: 0.3970 - val_loss: 1.3951 - val_accuracy: 0.4751
Epoch 19/20
28709/28709 [==============================] - 180s 6ms/step - loss: 1.4524 - accuracy: 0.4067 - val_loss: 1.3720 - val_accuracy: 0.4773
Epoch 20/20
28709/28709 [==============================] - 180s 6ms/step - loss: 1.4300 - accuracy: 0.4193 - val_loss: 1.3538 - val_accuracy: 0.4792
3589/3589 [==============================] - 6s 2ms/step
十:使用matplotlib绘图查看结果
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs2 = range(1,epochs+1)
fig = plt.figure(figsize=(20,10))
ax = fig.add_subplot(121)
ax.plot(epochs2,loss,'bo',label = 'Training Loss')
ax.plot(epochs2,val_loss,'b',label='Validation Loss')
plt.title('Training and Validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
ax2 = fig.add_subplot(122)
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
ax2.plot(epochs2,acc,'bo',label = 'Training Acc')
ax2.plot(epochs2,val_acc,'b',label='Validation Acc')
plt.title('Training and Validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Acc')
plt.legend()
plt.savefig('C:/Users/24651/Desktop/result.png')
plt.show()
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-sr7ipMzG-1587991466735)(output_13_0.png)]](https://i-blog.csdnimg.cn/blog_migrate/1237938bf391762c75b843849163da09.png)
大图如下:
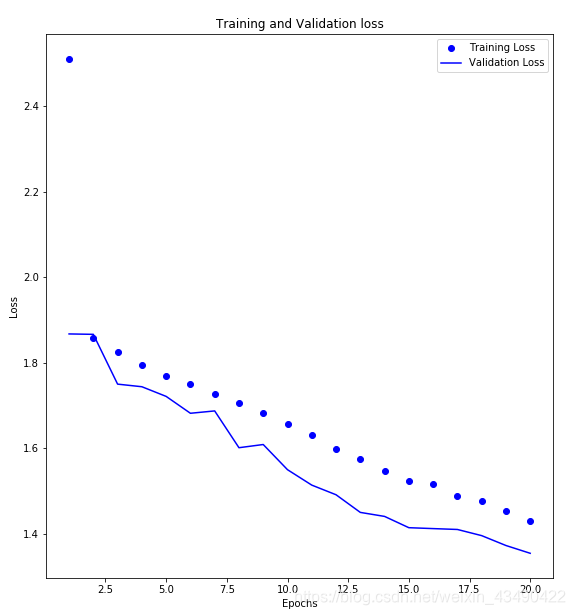
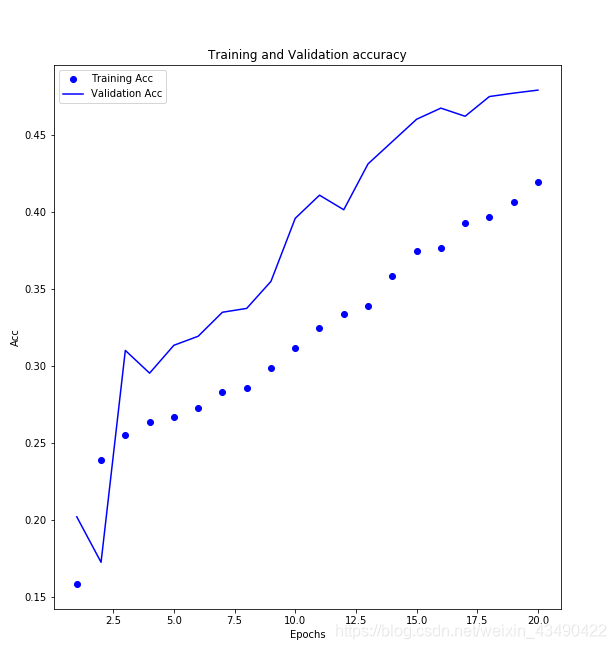
我们可以看到其实在20代的时候仍有上升的趋势,可以考虑训练更多代试试。
10.1:batch_size对于训练的影响
值得一说的是,在最初训练的时候,batch_size设置为128时(评估结果没记住,好像是acc为55%),在第10代左右就发生了过拟合(训练集的acc和loss一直在往好的方向,验证集则没有变化甚至负方向)。
由于是新手加上电脑配置有限,一次训练就花掉我大量时间,所以我没有做进一步的分析。
这里引用其他帖子的话:
Batch_Size 太小,算法在 很多epoches 内不收敛。
随着 Batch_Size 增大,处理相同数据量的速度越快。
随着 Batch_Size 增大,达到相同精度所需要的 epoch 数量越来越多。
10.2:评估结果
test_score
[1.3474807781773246, 0.4789634943008423]
总结
本模型表现的不是很好。
希望我能多学,改进下这个模型以提高其表现。
有生之年再续…
补充
鉴于很多人要代码,那么就放出链接
链接: https://pan.baidu.com/s/1EI35xehCdNn1MGHL-tDIHQ
提取码: hx4z



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











