







一,任务
本次做的是一个小麦水稻病虫害识别问题,使用tensorflow,利用CNN提取图片像素特征进行分类,并达到了一定的效果。
二,数据准备
为了防止过拟合,数据预处理阶段分别经过亮度增强,对比度增强,色度增强,以及图像翻转,图片一共3000张,通过变换得到12000张,resize得到224X224的图像,我们也尝试过只将有病的那块图像切割出来只将这些图片放到神经网络中训练但是得到的效果并不是特别好,当把图像直接resize放到网络中训练得到了非常好的效果。下面是图像经过变换后的状态。

```
image=Image.open(i)
enh_bri = ImageEnhance.Brightness(image)
brightness = 1.5
image_brightened = enh_bri.enhance(brightness)
enh_col = ImageEnhance.Color(image) # 色度
color = 1.5
image_colored = enh_col.enhance(color)
# 对比度增强
enh_con = ImageEnhance.Contrast(image)
contrast = 1.5
image_contrasted = enh_con.enhance(contrast)
```
三、这次使用的神经网络
本次使用的网络是香港中文大学设计的神经网络Fishnet下面看网络结构
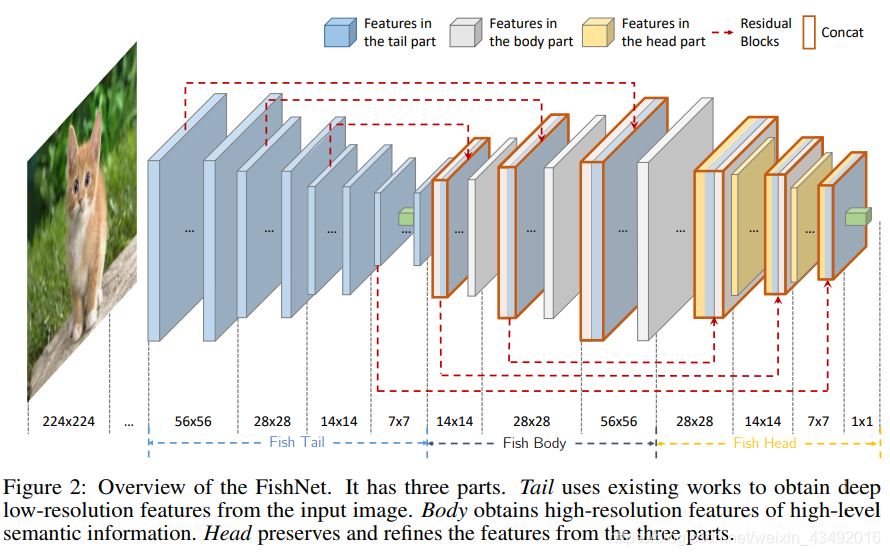
此网络有99层的150层的,和201层的,主要是将图片进行下采样后在上采样,最终再下采样,然后得到分类结果,网络中为了避免因为网络层数过深而丢失图像的语义信息,也结合了resnet的残差模块,图像中的红色就是将两个卷积层进行了特征融合。
这里有相关Fishnet解释比较好的博客链接: link.
四、代码部分
build_data.py
这部分代码主要将图片读取到tfrecord中,为了避免传统的tensorflow的tfrecord存储方法占用了原始图片将近7~8倍的内存,这里直接将图像打开后使用read方法读取图像后存储到tfrecord中,这样tfrecord的方法就和数据集的大小相同了。因为图像分为六类,所以总共用了六个子文件夹,如果你有更多的可以直接添加或者使用os.listdir()的方法遍历出来。
import tensorflow as tf
import random
import os
from collections import namedtuple
from os import scandir
tf.flags.DEFINE_string("data_1","./?????/1",
"target为1的数据集")
tf.flags.DEFINE_string("data_2","./??????",
"target为2的数据集")
tf.flags.DEFINE_string("data_3",".??????/3",
"target为3的数据集")
tf.flags.DEFINE_string("data_4",".??????/4",
"target为4的数据集")
tf.flags.DEFINE_string("data_5","???????/5",
"target为5的数据集")
tf.flags.DEFINE_string("data_6","???????/6",
"target为6的数据集")
tf.flags.DEFINE_string("output_dir",'./Classify.tfrecords',
"tfrecord保存数据集的地址")
tf.flags.DEFINE_string("pic_bise_dir", "path", "图片的基本地址")
FLAGS = tf.flags.FLAGS
ImageMetadata = namedtuple("ImageMetadata", ["pic_dir", "target"])
dataset = []
def data_process(path_dir, target):
"""
:param data_dir:图片路径
:param num: 图片对应的target
:return:
"""
# csandir 读取特定的目录文件
for path_di in scandir(path_dir):
# 判断图片是否以.JPG格式结尾,是否是常规文件
if path_di.name.endswith('.JPG') and path_di.is_file():
# 构建图片地址和目标值的对应关系
a = ImageMetadata(path_di.path, target)
dataset.append(a)
def convert_to_example(encoded_image, target):
"""
:param encoded_image:read后的图片
:param target: 目标值
:return: 返回example协议
"""
example = tf.train.Example(
features=tf.train.Features(
feature={
"image": tf.train.Feature(
bytes_list=tf.train.BytesList(
value=[encoded_image])), "label": tf.train.Feature(
int64_list=tf.train.Int64List(
value=[target]))}))
return example
def write_in_tfrecord(dataset):
"""
:param image:
:return: 将图片写入文件
"""
# 定义tfrecord的writer
writer = tf.python_io.TFRecordWriter(FLAGS.output_dir)
for image in dataset:
# 读取图片
with tf.gfile.FastGFile(image.pic_dir, "rb") as f:
# 将图片变成原始编码形式
encoded_image = f.read()
# 将图片和target写入tfrecord
example = convert_to_example(encoded_image, image.target)
writer.write(example.SerializeToString())
print("done")
writer.close()
dir = [FLAGS.data_1,FLAGS.data_2,FLAGS.data_3,FLAGS.data_4,FLAGS.data_5,FLAGS.data_6]
path = dict([x, y] for x, y in enumerate(dir))
for i in range(6):
path_dir = path[i]
data_process(path_dir, i)
random.shuffle(dataset)
write_in_tfrecord(dataset)
reader.py
reader部分主要将存储到tfreocrd中的数据读取出来,每张图片对应的image和label
import tensorflow as tf
import numpy as np
class Reader():
def __init__(self,tfrecord_file,image_size=224,min_queue_examples=100,
batch_size=1, num_threads=1,name=''):
"""
:param tfrecord_file: tfrecord文件路径
:param image_size: 将图片resize为同样大小
:param min_queue_examples:
:param batch_size: 批处理图片的大小
:param num_threads: 开启线程个数
:param name:
"""
self.tfrecord=tfrecord_file
self.image_size=image_size,
self.min_queue_example=min_queue_examples,
self.batch_size=batch_size
self.reader=tf.TFRecordReader()
self.num_threads=num_threads
self.name=name
def feed(self):
"""
:return:4Dtensor[batch_size,image_width, image_height,channels]
"""
with tf.name_scope(self.name):
# 读取文件名队列
file_queue=tf.train.string_input_producer([self.tfrecord],num_epochs=10)
# 将数据用TFRecordReader的方式读入value中
_,value=self.reader.read(file_queue)
# 将数据解码还原,放到张量里
sample=[]
features = tf.parse_single_example(value,features={
"image":tf.FixedLenFeature([],tf.string),
"label":tf.FixedLenFeature([],tf.int64)
})
# 获取图片和目标值
image=features["image"]
label=features["label"]
# 将图片解码
image=tf.image.decode_jpeg(image,channels=3)
# 图片处理过程
image=self.process(image)
# 批处理
image_batch,lable_batch=tf.train.shuffle_batch([image,label],
batch_size=self.batch_size,
num_threads=self.num_threads,
capacity=1024,
min_after_dequeue=900
)
# image_batch, lable_batch = tf.train.batch([image,label],batch_size=32,num_threads=8,
# capacity=200)
label_batch=tf.reshape(lable_batch,shape=[self.batch_size])
return image_batch,label_batch
def process(self,image):
# 将图片处理到统一大小
image=tf.image.resize_images(image,size=[224,224])
# image=tf.image.random_flip_left_right(image)# 随机左右翻转
# image=tf.image.random_flip_up_down(image)# 随机上下翻转
# image=tf.image.rot90(image,np.random.randint(1,4))# 随机旋转90*n次
# 将图片转化为float32类型
image=tf.cast(image,tf.float32)
# 将图片转化为三维的
image=tf.reshape(image,shape=[224,224,3])
# 将图片进行random剪切反转操作
# 将图片归一化
image=tf.image.per_image_standardization(image)
return image
train.py
train中的代码将GPU那行代码打开便能够使用GPU了,因为Fishnet占用内存比较大所以尽量使用GPU
import reader
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
from Fishnet import FishNets
from alexnet_1 import alexnet
# import matplotlib.pyplot as plt
num_epoch = 10
num_classify = 6
learning_rate = 0.001
save_model="./tmp/train_model.ckpt"
def average_gradients(tower_grads):
"""Calculate the average gradient for each shared variable across all towers.
Note that this function provides a synchronization point across all towers.
Args:
tower_grads: List of lists of (gradient, variable) tuples. The outer list
is over individual gradients. The inner list is over the gradient
calculation for each tower.
Returns:
List of pairs of (gradient, variable) where the gradient has been averaged
across all towers.
"""
average_grads = []
for grad_and_vars in zip(*tower_grads):
# Note that each grad_and_vars looks like the following:
# ((grad0_gpu0, var0_gpu0), ... , (grad0_gpuN, var0_gpuN))
grads = []
for g, _ in grad_and_vars:
# Add 0 dimension to the gradients to represent the tower.
expanded_g = tf.expand_dims(g, 0)
# Append on a 'tower' dimension which we will average over below.
grads.append(expanded_g)
# Average over the 'tower' dimension.
grad = tf.concat(axis=0, values=grads)
grad = tf.reduce_mean(grad, 0)
# Keep in mind that the Variables are redundant because they are shared
# across towers. So .. we will just return the first tower's pointer to
# the Variable.
v = grad_and_vars[0][1]
grad_and_var = (grad, v)
average_grads.append(grad_and_var)
return average_grads
def onehot(label):
n_sample=len(label)
# n_class=max(label)+1
onehot_labels=np.zeros((n_sample,num_classify))
onehot_labels[np.arange(n_sample),label]=1
return onehot_labels
# with tf.name_scope("accuracy"):
with tf.Graph().as_default(),tf.device("/cpu:0"):
x = tf.placeholder(tf.float32, shape=[None, 224, 224, 3])
y = tf.placeholder(tf.float32, shape=[None, 6])
global_step = tf.get_variable('global_variable', initializer=tf.constant(0),trainable=False)
tower_grads = []
losses=[]
network_planes = [64, 128, 256, 512, 512, 512, 384, 256, 320, 832, 1600]
num_res_blks = [2, 2, 6, 2, 1, 1, 1, 1, 2, 2]
num_trans_blks = [1, 1, 1, 1, 1, 4]
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate)
with tf.variable_scope(tf.get_variable_scope()):
# with tf.device("/gpu:0"):
# fc3 = alexnet(x, num_classify)
with tf.name_scope("name",) as scope:
# value=alexnet(x,6)
mode=FishNets(num_classify,network_planes,num_res_blks,num_trans_blks)
value=mode(x,training=True)
a=tf.arg_max(value,1)
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=value, labels=y))
# train_op = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(loss)
tf.get_variable_scope().reuse_variables()
summaries = tf.get_collection(tf.GraphKeys.SUMMARIES, scope)
gradient = optimizer.compute_gradients(loss)
tower_grads.append(gradient)
grads = average_gradients(tower_grads)
losses.append(loss)
train_op = optimizer.apply_gradients(grads,global_step=global_step)
accuracy = tf.equal((tf.argmax(value, 1),),
tf.argmax(y, 1))
accuracy = tf.reduce_mean(tf.cast(accuracy, tf.float32))
saver = tf.train.Saver()
init = tf.global_variables_initializer()
sess = tf.Session(config=tf.ConfigProto(
allow_soft_placement=True,
log_device_placement=False))
saver.save(sess,"./tmp/train_model.ckpt")
print("begin")
TRAIN_FILE = "./Classify.tfrecords"
read=reader.Reader(TRAIN_FILE,batch_size=24)
image_dataset,label_dataset=read.feed()
sess.run(tf.global_variables_initializer())
sess.run(tf.local_variables_initializer())
# saver.restore(sess,)
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess,coord=coord)
for step in range(12000):# 83个epoch
batch_label,batch_image=sess.run([label_dataset,image_dataset])
if step % 1==0:
print(batch_label)
batch_label = onehot(batch_label)
values,optimize, accu, los = sess.run([a,train_op, accuracy, loss], feed_dict={
x: batch_image, y: batch_label})
if step %1==0:
#summary_str=sess.run(summary_op,feed_dict={
# x: batch_image, y: batch_label})
# summary_writer.add_summary(summary_str, step)
print(" %d 准确率为%f 损失为%f " % (step,accu,los))
print(values)
if step % 100==0:
saver.save(sess,save_model)
coord.request_stop()
coord.join(threads)
plt.plot(losses)
plt.xlabel('iter')
plt.ylabel('loss')
plt.tight_layout()
plt.savefig('./cnn-tf-AlexNet.png',dpi=200)
五、结果分析

这是训练过程中第二层卷积梯度变化,可以看到仅仅训练没几步的时候梯度已经接近于零了,训练了100个批次后准确率几乎100%,但可惜的是测试的结果并不是太理想,应该是产生了过拟合,我们正在找原因
六,遇到的困难
在实践过程中因为使用tf.train.shuffle_batch的过程中因为它只是在每次读取一定的数量来打乱数据,如果你每次取1000个数据,而每一类数据是2000的那么你前面两千取到的数据集只是一类,再打乱也并不能起到好的效果,于是我在build_data.py中使用了shuffle在存储数据的时候就将数据打乱,这样就好了,感觉这也是使用tf.train.shuffle_batch的一个不足之处吧,造成的结果就是在每一个epoch中准确率一高一低的。在我的另一篇博客中也有提到链接: link.

















 672
672

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









