




 本文介绍了一个Python脚本,用于抓取汽车之家网站的汽车配置信息。脚本根据输入的品牌名称,自动下载所有车系的配置清单,每个车系的配置保存为Excel表格。文章详细阐述了解析过程中的难点,包括从JavaScript中提取加密数据,并使用正则表达式和自动化工具(如selenium)解密和整理数据,最终导出完整配置信息。
本文介绍了一个Python脚本,用于抓取汽车之家网站的汽车配置信息。脚本根据输入的品牌名称,自动下载所有车系的配置清单,每个车系的配置保存为Excel表格。文章详细阐述了解析过程中的难点,包括从JavaScript中提取加密数据,并使用正则表达式和自动化工具(如selenium)解密和整理数据,最终导出完整配置信息。
【任务目标】
-
用python写一个脚本,输入一个汽车品牌名称,比如“沃尔沃”;
-
程序自动下载沃尔沃品牌下所有车系的配置清单;
-
每一个车系保存为一个Excel表格,表格命名为“品牌名+车系+年份”,如“沃尔沃_沃尔沃XC90_2024款.xlsx”;
-
同品牌的配置表保存到以品牌命名的文件夹中。
【实现效果】
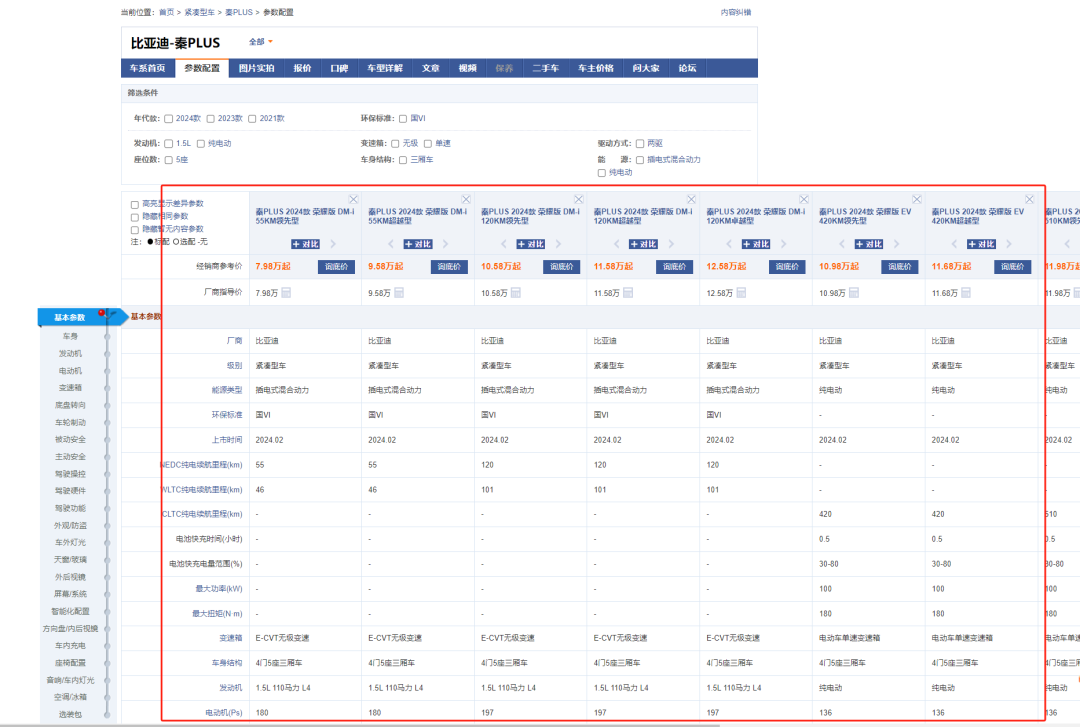
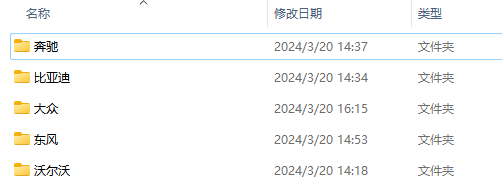
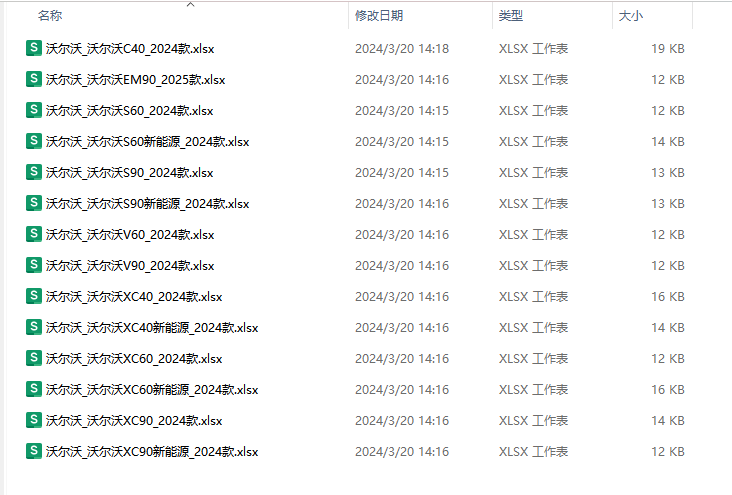

【难点痛点】
-
汽车配置在网页的script脚本中,需要通过正则匹配出来;
-
通过第一步得到的配置信息是不完整的,有些是配置的名称,比如浏览器显示的“厂商指导价(元)”,我们匹配的结果是“厂()”;还有些是配置参数隐藏的,浏览器显示是有参数的,但是我们得到的结果是空值,经过研究发现,其实这些隐藏的信息都是通过CSS的样式加密了,执行解密的JS脚本其实都在第1步服务器返回的响应数据里,我们同样可以通过正则匹配出来;
-
有些配置的参数值是没有的,如果我们在匹配数据的时候没有注意specid这个参数,得到的配置表最后会跟浏览器端显示的数据对不上,这样错误的数据也是没有价值的。
【逻辑整理】
-
找到数据接口;
-
向服务器发起请求;
-
得到的数据是加密的,所以需要寻找解密方法;
-
通过多次请求数据、解析数据、对比网页端数据,找到解密逻辑;
-
还原出完整的数据,即对加密数据进行解密;
-
解析数据,得到我们需要的数据;
-
导出文件。
【代码实现】
码代码之前,首先需要安装必要的第三方库,安装也很简单,执行以下命令即可:
pip install requests bs4 fake_useragent playwright pandas-- 步骤1
- 输入品牌名称,得到该品牌下的所有车系。
def get_band_response(brand_id="0"):
num = 1 # 用于统计请求次数
while True:
headers = {
"user-agent": UserAgent().random # 随机获取ua
}
url = "https://car.autohome.com.cn/AsLeftMenu/As_LeftListNew.ashx"
params = {
"typeId": "1 ",
"brandId": brand_id,
"fctId": "0 ",
"seriesId": "0"
}
response = requests.get(url, headers=headers, params=params)
if response.status_code == 200:
return response
els 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 2643
2643

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









