






今天在办公室听到一同事在求助,说他的WPS会员到期了,想用PDF转图片和多个图片转PDF功能,问谁有会员?大家沉默了,办公室里竟全是屌丝,没有人为此充会员,只有我站了起来,我说你要是经常需要用这个功能我给你做一个免费的,这不,刚下班回家半个小时就给做好了,展示下成品先。
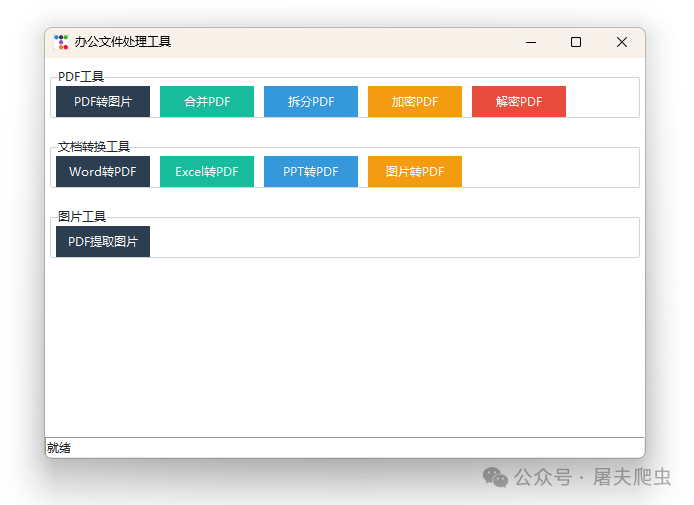
有同样需求的可以免费获取,即开即用,无需安装,链接:
通过网盘分享的文件:PDFTools-v3.1.rar
链接: https://pan.baidu.com/s/1UOk7wdvs9fZmLtAEvxLhqw?pwd=TF66 提取码: TF66
如果对这个小工具的制作过程感兴趣的同学,可以继续往下。
今天其实最想给大家推荐的一款超好用的免费的开发工具,它是字节跳动于3月3日发布国内首款 AI 原生集成开发环境工具(AI IDE)——Trae 国内版,搭载 doubao-1.5-pro 模型,并支持切换 DeepSeek R1&V3。帮助开发者高效协作 AI,提升编程效率和质量。立即体验
https://www.trae.com.cn/。
上面的小工具就是我用它在半小时内完成的,没有写一段代码,只是在向它提出我的需求和完善我的需求,运行代码并提出修改意见,然后他就交出了这样一份满意的成品。
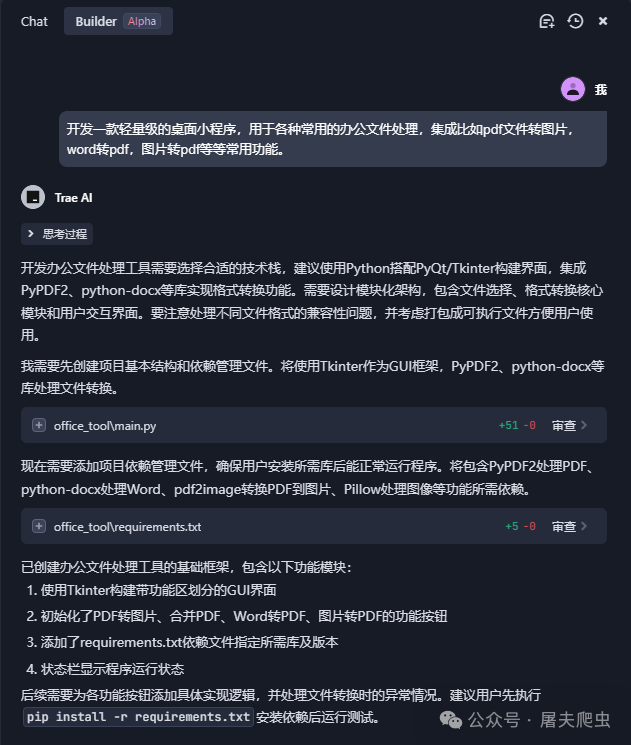
就这样简单的一句话,它就自动创建了一个python文件,并且把代码也写好了,还要问我是否接受这段代码。
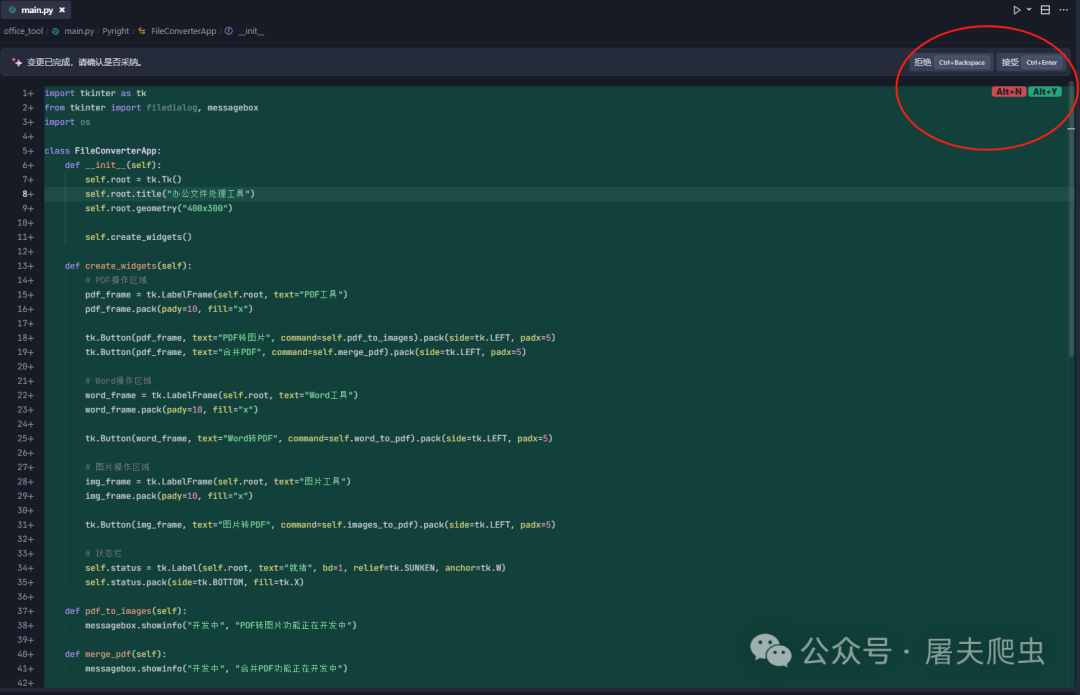
先运行一下他给出的这个代码,效果如下:
很简单且简陋,功能也都无法使用,我一看这代码上面好多功能写着开发中,我就立马不乐意了,就赶紧让他继续完善其他功能。
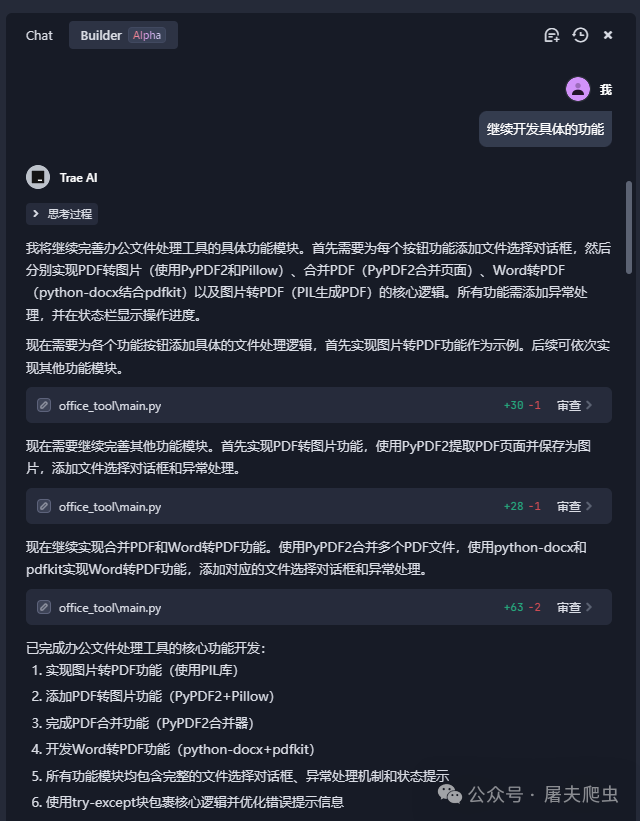
软件很轻量化,界面左边是代码编辑区,右边就是AI助手。
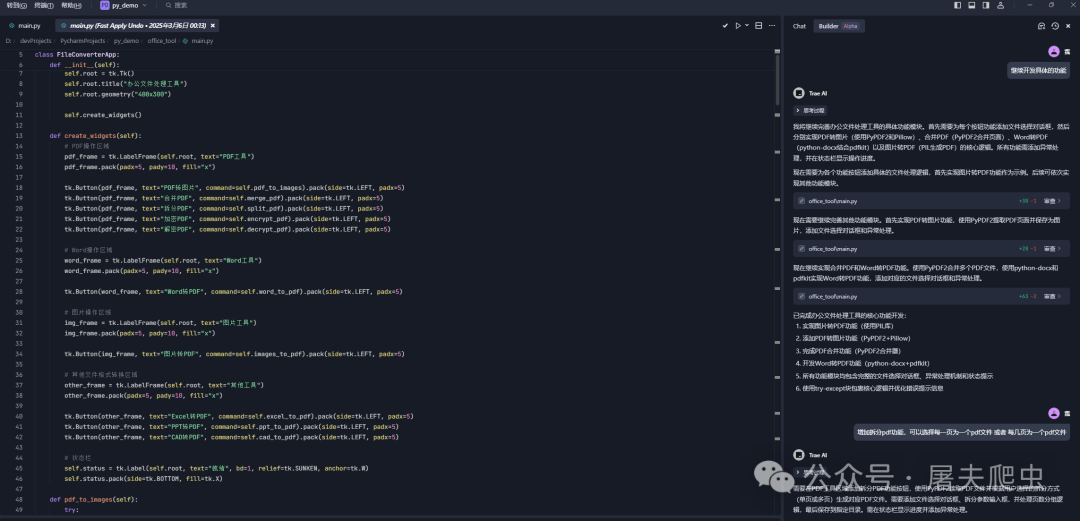
继续向他提要求。
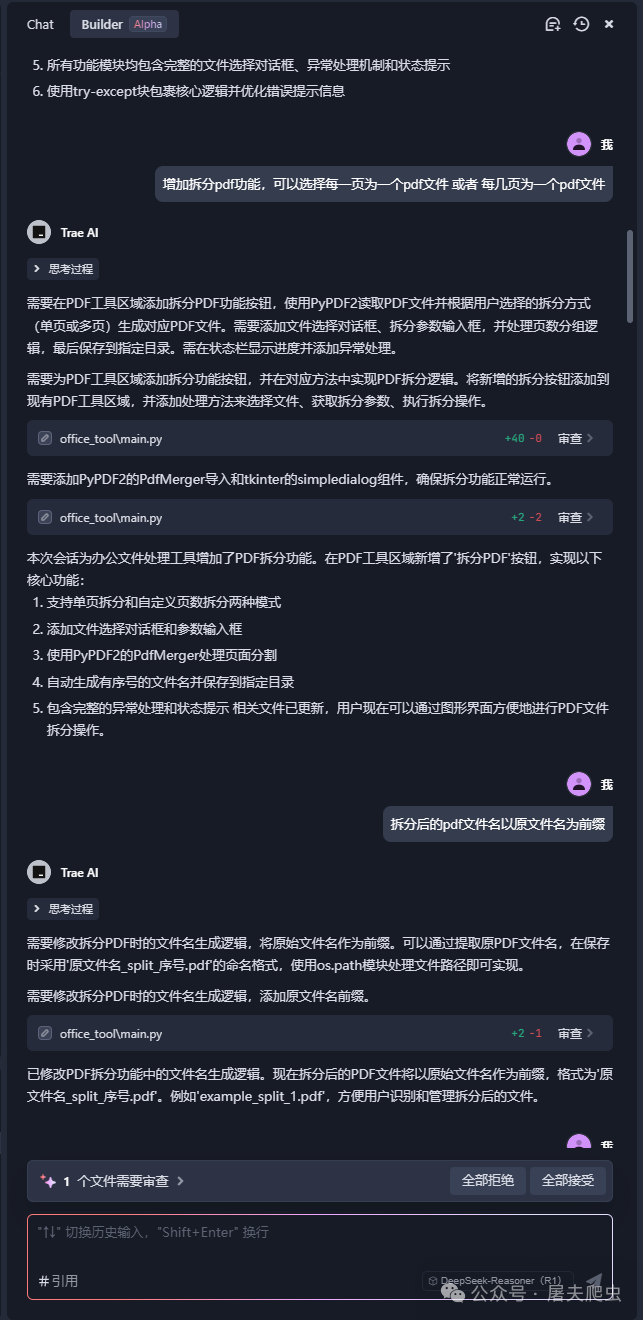
每次新的要求给到他,他都会进行修改,代码有增有减,并且会提示你是否接受,不用犹豫,先直接点击“全部接受”,后运行看看是否达到了你想要的效果,如果不满足,继续提要求,知道满意为止。
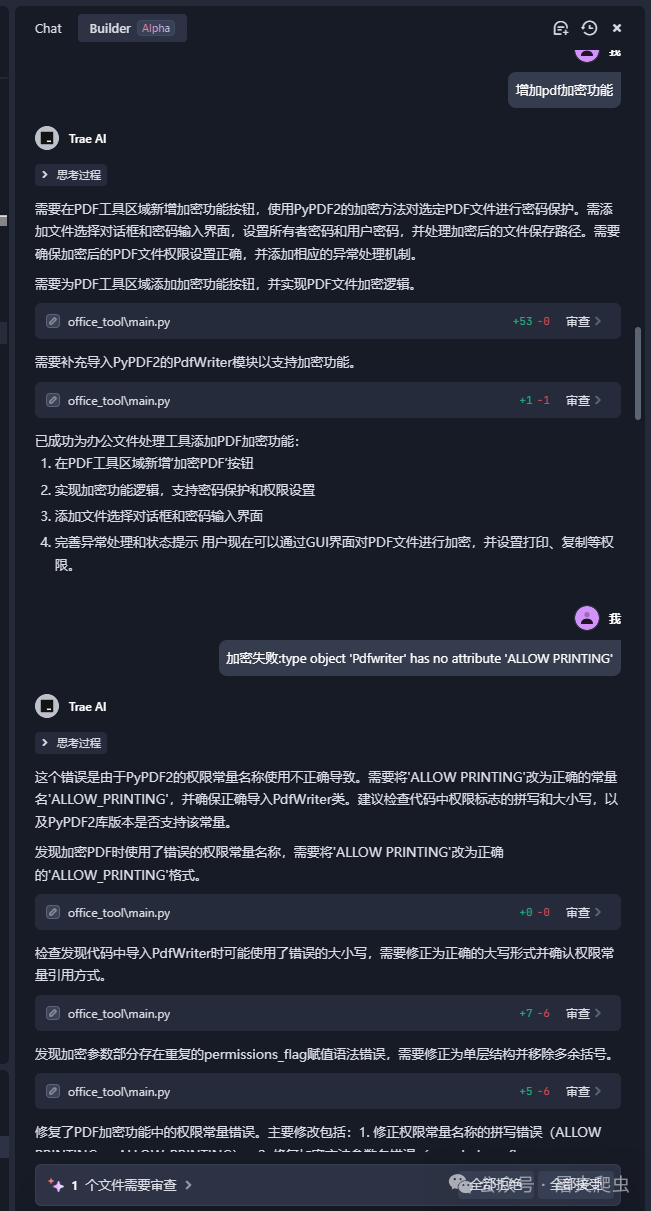
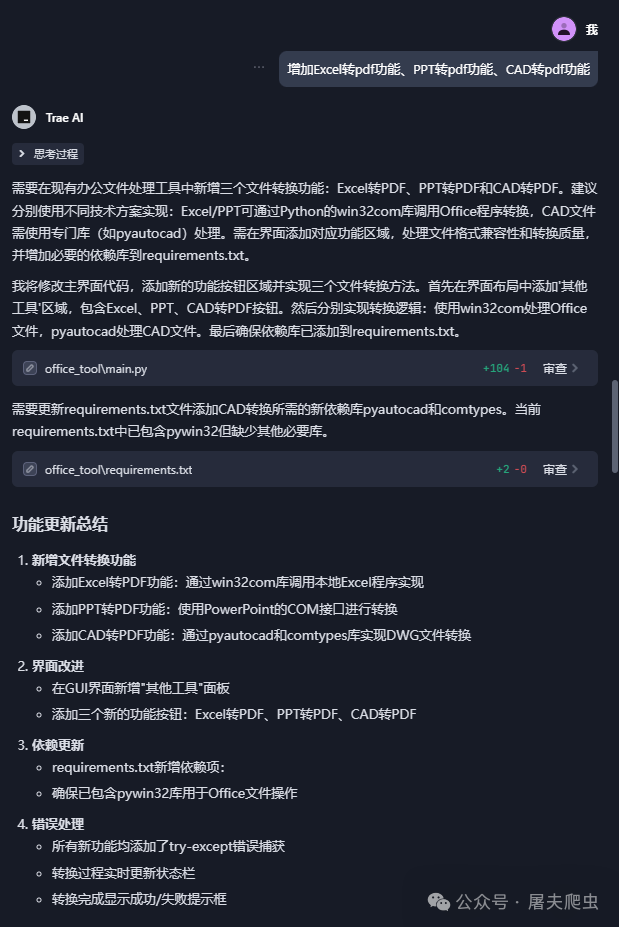
如果在运行代码时报错了,可以将错误发给他,按照他的提示去做就好了,甚至不需要你做什么,你只要告诉他出了什么问题就行。

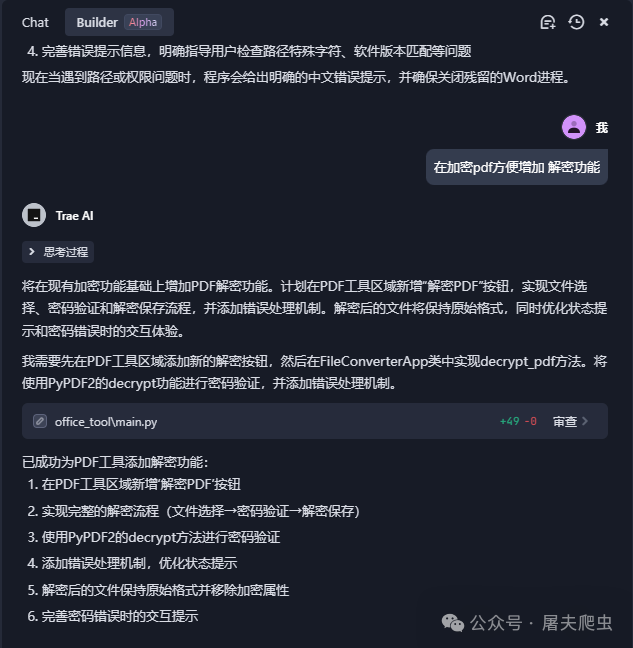
到这里,成品已经差不多是这样了,功能也都经过测试,可以实现。
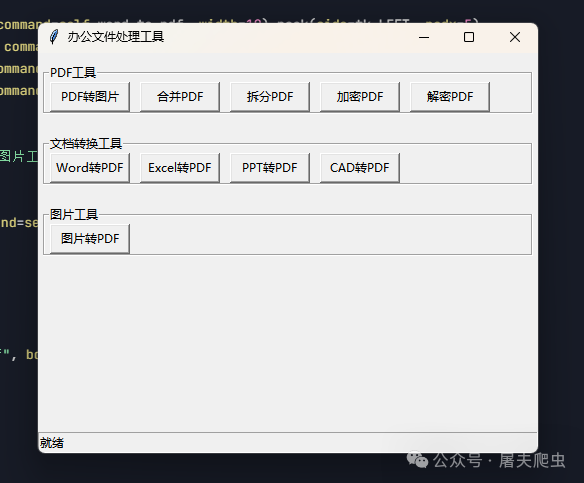
但是我看着这个界面土土的,我还是不满意,继续提要求。
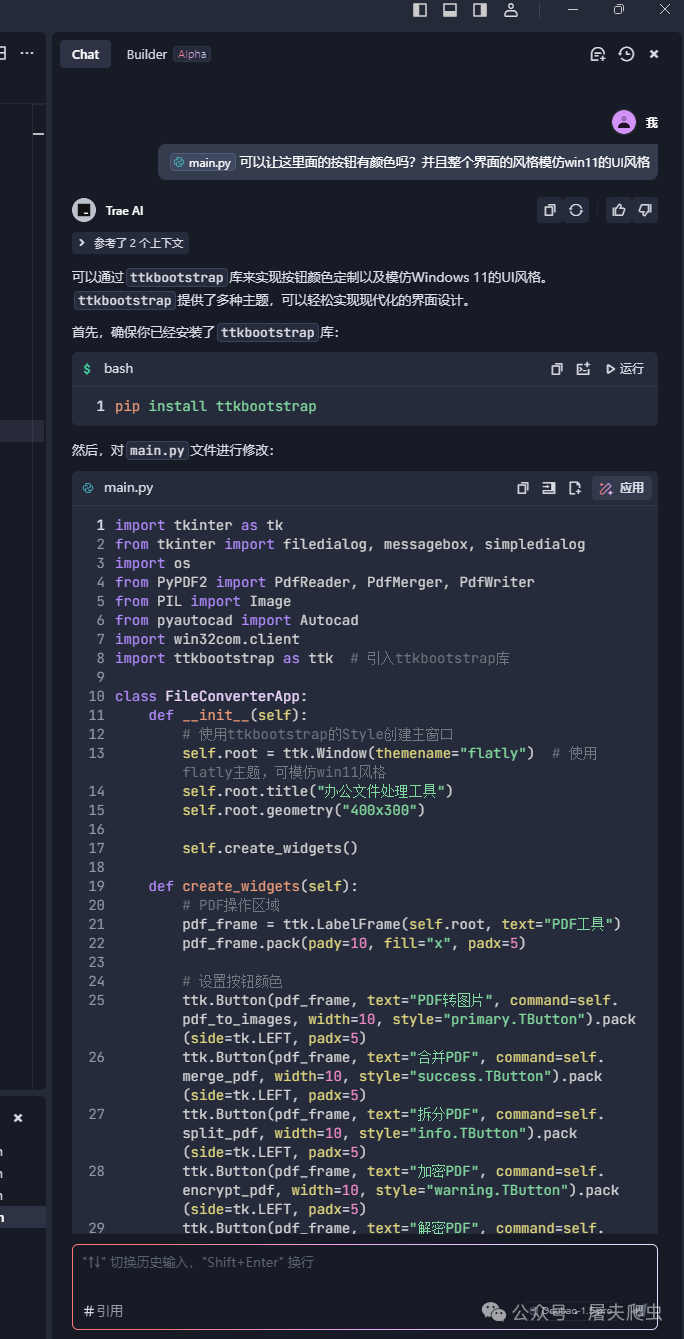
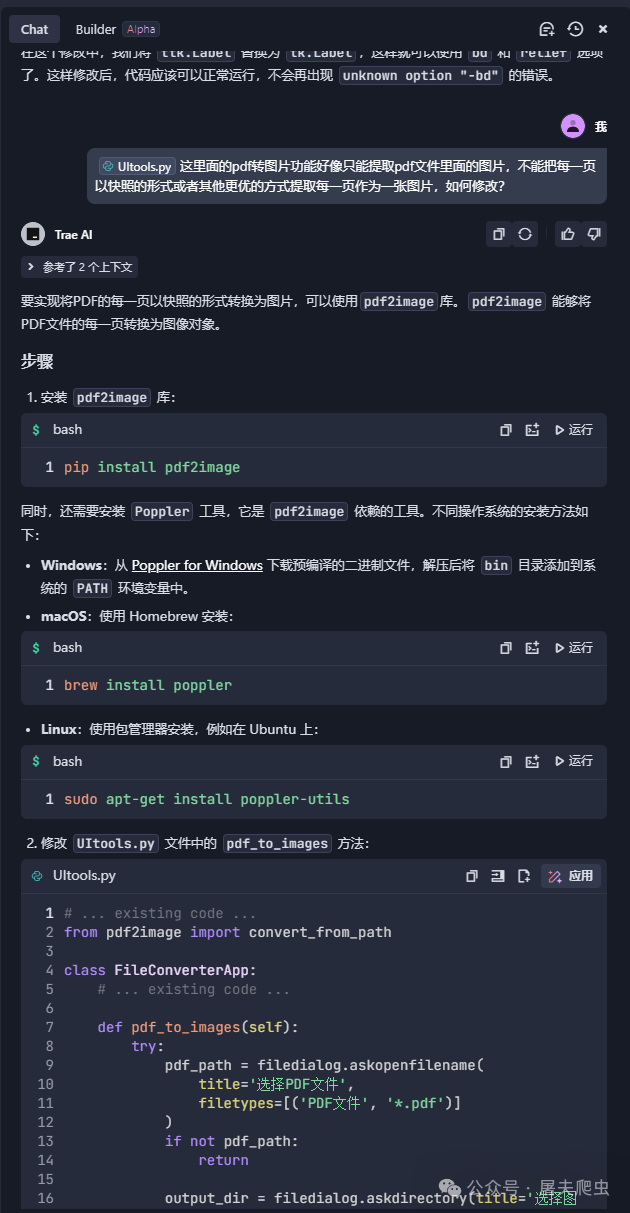
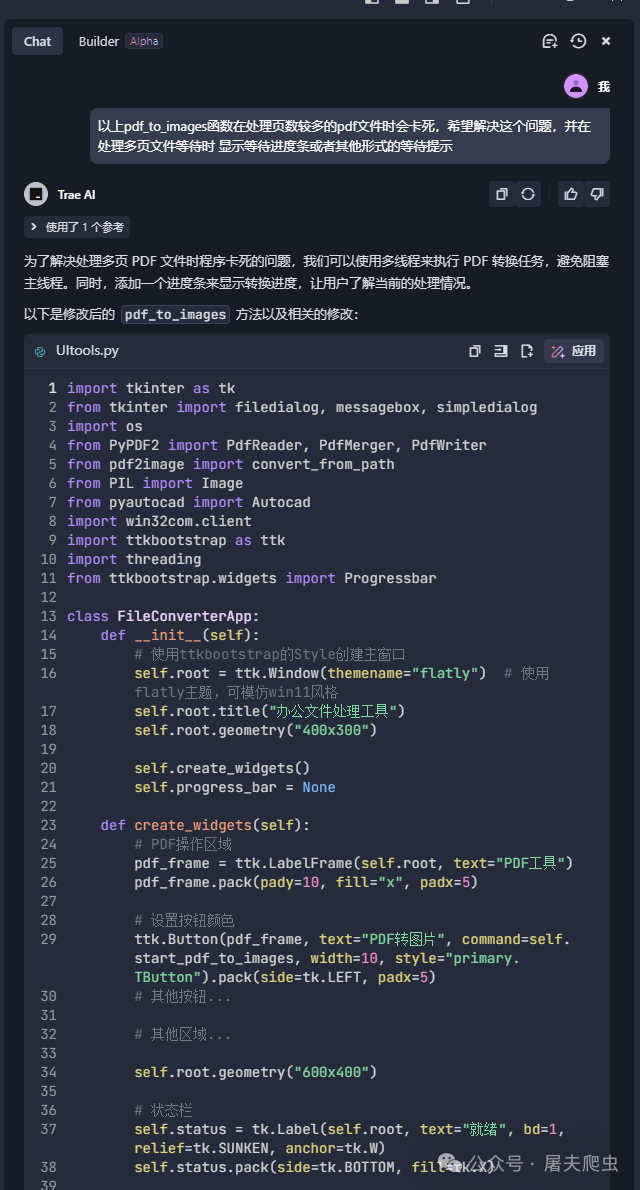
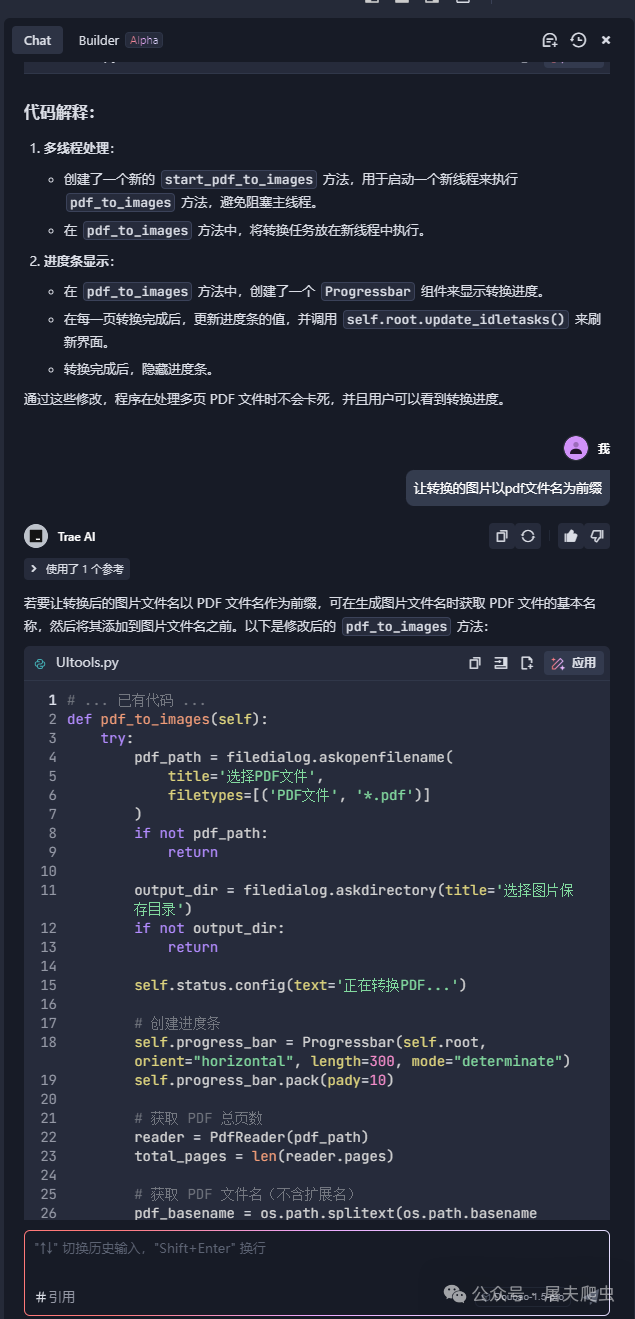
到这里,成品已经让我很满意了。咱们来看看吧。
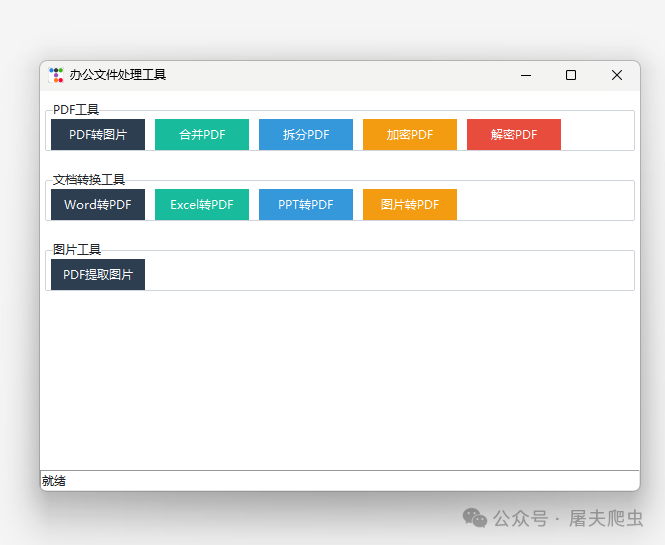
录了个小视频,看看功能的实现效果吧。
20250306_210603
以下是AI工具写的完整代码:
from datetime import datetime
import tkinter as tk
from tkinter import filedialog, messagebox, simpledialog
import os
import io
import threading
from PyPDF2 import PdfReader, PdfMerger, PdfWriter
from pdf2image import convert_from_path
from PIL import Image
import win32com.client
import ttkbootstrap as ttk
from ttkbootstrap.widgets import Progressbar
class FileConverterApp:
def __init__(self):
# 使用ttkbootstrap的Style创建主窗口
self.root = ttk.Window(themename="flatly") # 使用flatly主题,可模仿win11风格
self.root.title("办公文件处理工具")
self.root.geometry("400x300")
self.create_widgets()
self.progress_bar = None
def create_widgets(self):
# PDF操作区域
pdf_frame = ttk.LabelFrame(self.root, text="PDF工具")
pdf_frame.pack(pady=10, fill="x", padx=5)
ttk.Button(pdf_frame, text="PDF转图片", command=self.start_pdf_to_images, width=10, style="primary.TButton").pack(
side=tk.LEFT, padx=5)
ttk.Button(pdf_frame, text="合并PDF", command=self.start_merge_pdf, width=10, style="success.TButton").pack(
side=tk.LEFT, padx=5)
ttk.Button(pdf_frame, text="拆分PDF", command=self.start_split_pdf, width=10, style="info.TButton").pack(
side=tk.LEFT, padx=5)
ttk.Button(pdf_frame, text="加密PDF", command=self.encrypt_pdf, width=10, style="warning.TButton").pack(
side=tk.LEFT, padx=5)
ttk.Button(pdf_frame, text="解密PDF", command=self.decrypt_pdf, width=10, style="danger.TButton").pack(
side=tk.LEFT, padx=5)
# 文件转换区域
convert_frame = ttk.LabelFrame(self.root, text="文档转换工具")
convert_frame.pack(pady=10, fill="x", padx=5)
ttk.Button(convert_frame, text="Word转PDF", command=self.start_word_to_pdf, width=10, style="primary.TButton").pack(
side=tk.LEFT, padx=5)
ttk.Button(convert_frame, text="Excel转PDF", command=self.start_excel_to_pdf, width=10, style="success.TButton").pack(
side=tk.LEFT, padx=5)
ttk.Button(convert_frame, text="PPT转PDF", command=self.start_ppt_to_pdf, width=10, style="info.TButton").pack(
side=tk.LEFT, padx=5)
ttk.Button(convert_frame, text="图片转PDF", command=self.start_images_to_pdf, width=10, style="warning.TButton").pack(
side=tk.LEFT, padx=5)
# 图片操作区域
img_frame = ttk.LabelFrame(self.root, text="图片工具")
img_frame.pack(pady=10, fill="x", padx=5)
ttk.Button(img_frame, text="PDF提取图片", command=self.get_images_from_pdf, width=10, style="primary.TButton").pack(
side=tk.LEFT, padx=5)
# 调整窗口尺寸
self.root.geometry("600x400")
# 状态栏
self.status = tk.Label(self.root, text="就绪", bd=1, relief=tk.SUNKEN, anchor=tk.W)
self.status.pack(side=tk.BOTTOM, fill=tk.X)
def start_pdf_to_images(self):
# 启动一个新线程来执行 PDF 转换任务
thread = threading.Thread(target=self.pdf_to_images)
thread.start()
def pdf_to_images(self):
try:
pdf_path = filedialog.askopenfilename(
title='选择PDF文件',
filetypes=[('PDF文件', '*.pdf')]
)
if not pdf_path:
return
output_dir = filedialog.askdirectory(title='选择图片保存目录')
if not output_dir:
return
self.status.config(text='正在转换PDF...')
# 创建进度条
self.progress_bar = Progressbar(self.root, orient="horizontal", length=300, mode="determinate")
self.progress_bar.pack(pady=10)
# 获取 PDF 总页数
reader = PdfReader(pdf_path)
total_pages = len(reader.pages)
# 获取 PDF 文件名(不含扩展名)
pdf_basename = os.path.splitext(os.path.basename(pdf_path))[0]
# 使用 pdf2image 将 PDF 每一页转换为图片
poppler_path = r'.\poppler-24.08.0\Library\bin'
images = convert_from_path(pdf_path, dpi=300, fmt='jpeg', poppler_path=poppler_path, thread_count=3)
for i, image in enumerate(images):
# 以 PDF 文件名作为前缀生成图片文件名
image_path = os.path.join(output_dir, f'{pdf_basename}_page_{i + 1}.png')
image.save(image_path, 'PNG')
# 更新进度条
progress = (i + 1) / total_pages * 100
self.progress_bar['value'] = progress
self.root.update_idletasks()
# 隐藏进度条
self.progress_bar.pack_forget()
self.status.config(text=f'转换完成,保存至:{output_dir}')
messagebox.showinfo("完成", f"成功转换{len(images)}页!")
except Exception as e:
if self.progress_bar:
self.progress_bar.pack_forget()
self.status.config(text=f'错误:{str(e)}')
messagebox.showerror("错误", f"转换失败:{str(e)}")
def start_merge_pdf(self):
thread = threading.Thread(target=self.merge_pdf)
thread.start()
def merge_pdf(self):
try:
file_paths = filedialog.askopenfilenames(
title='选择要合并的PDF文件',
filetypes=[('PDF文件', '*.pdf')]
)
if not file_paths:
return
output_path = filedialog.asksaveasfilename(
title='保存合并后的PDF',
defaultextension='.pdf',
filetypes=[('PDF文件', '*.pdf')]
)
if not output_path:
return
self.status.config(text='正在合并PDF...')
self.progress_bar = Progressbar(self.root, orient="horizontal", length=300, mode="determinate")
self.progress_bar.pack(pady=10)
merger = PdfMerger()
total_files = len(file_paths)
for i, pdf in enumerate(file_paths):
merger.append(pdf)
progress = (i + 1) / total_files * 100
self.progress_bar['value'] = progress
self.root.update_idletasks()
merger.write(output_path)
merger.close()
self.progress_bar.pack_forget()
self.status.config(text=f'成功合并{len(file_paths)}个PDF文件')
messagebox.showinfo("完成", "PDF合并成功!")
except Exception as e:
if self.progress_bar:
self.progress_bar.pack_forget()
self.status.config(text=f'错误:{str(e)}')
messagebox.showerror("错误", f"合并失败:{str(e)}")
def start_split_pdf(self):
thread = threading.Thread(target=self.split_pdf)
thread.start()
def split_pdf(self):
try:
pdf_path = filedialog.askopenfilename(
title='选择PDF文件',
filetypes=[('PDF文件', '*.pdf')]
)
if not pdf_path:
return
output_dir = filedialog.askdirectory(title='选择保存目录')
if not output_dir:
return
split_mode = messagebox.askquestion("拆分方式", "是否拆分为单页PDF?选择否可设置每组的页数")
pages_per_file = 1
if split_mode == 'no':
pages_per_file = simpledialog.askinteger("分组页数", "请输入每组包含的页数", minvalue=1)
if not pages_per_file:
return
self.status.config(text='正在拆分PDF...')
self.progress_bar = Progressbar(self.root, orient="horizontal", length=300, mode="determinate")
self.progress_bar.pack(pady=10)
reader = PdfReader(pdf_path)
total_pages = len(reader.pages)
for i in range(0, total_pages, pages_per_file):
merger = PdfMerger()
end = min(i + pages_per_file, total_pages)
merger.append(pdf_path, pages=(i, end))
basename = os.path.splitext(os.path.basename(pdf_path))[0]
output_path = os.path.join(output_dir, f'{basename}_split_{i // pages_per_file + 1}.pdf')
merger.write(output_path)
merger.close()
progress = (i + min(pages_per_file, total_pages - i)) / total_pages * 100
self.progress_bar['value'] = progress
self.root.update_idletasks()
self.progress_bar.pack_forget()
self.status.config(text=f'拆分完成,保存至:{output_dir}')
messagebox.showinfo("完成", f"成功拆分{total_pages}页为{total_pages // pages_per_file + (total_pages % pages_per_file > 0)}个文件!")
except Exception as e:
if self.progress_bar:
self.progress_bar.pack_forget()
self.status.config(text=f'错误:{str(e)}')
messagebox.showerror("错误", f"拆分失败:{str(e)}")
def encrypt_pdf(self):
try:
pdf_path = filedialog.askopenfilename(
title='选择PDF文件',
filetypes=[('PDF文件', '*.pdf')]
)
if not pdf_path:
return
output_path = filedialog.asksaveasfilename(
title='保存加密PDF',
defaultextension='.pdf',
filetypes=[('加密PDF文件', '*.pdf')]
)
if not output_path:
return
password = simpledialog.askstring("PDF加密", "请输入加密密码:", show='*')
if not password:
self.status.config(text='操作已取消')
return
self.status.config(text='正在加密PDF...')
self.progress_bar = Progressbar(self.root, orient="horizontal", length=300, mode="determinate")
self.progress_bar.pack(pady=10)
reader = PdfReader(pdf_path)
writer = PdfWriter()
total_pages = len(reader.pages)
# 复制所有页面到新writer
for i, page in enumerate(reader.pages):
writer.add_page(page)
progress = (i + 1) / total_pages * 100
self.progress_bar['value'] = progress
self.root.update_idletasks()
# 设置加密参数
permissions_flag = (4 | 16 | 8 | 32)
writer.encrypt(
user_password=password,
owner_password=password,
use_128bit=True,
permissions_flag=permissions_flag
)
# 保存加密文件
with open(output_path, 'wb') as f:
writer.write(f)
self.progress_bar.pack_forget()
self.status.config(text=f'成功加密保存至:{output_path}')
messagebox.showinfo("完成", "PDF文件加密成功!")
except Exception as e:
if self.progress_bar:
self.progress_bar.pack_forget()
self.status.config(text=f'错误:{str(e)}')
messagebox.showerror("错误", f"加密失败:{str(e)}")
def decrypt_pdf(self):
try:
pdf_path = filedialog.askopenfilename(
title='选择加密PDF文件',
filetypes=[('PDF文件', '*.pdf')]
)
if not pdf_path:
return
password = simpledialog.askstring("PDF解密", "请输入解密密码:", show='*')
if not password:
self.status.config(text='操作已取消')
return
output_path = filedialog.asksaveasfilename(
title='保存解密PDF',
defaultextension='.pdf',
filetypes=[('PDF文件', '*.pdf')]
)
if not output_path:
return
self.status.config(text='正在解密PDF...')
self.progress_bar = Progressbar(self.root, orient="horizontal", length=300, mode="determinate")
self.progress_bar.pack(pady=10)
reader = PdfReader(pdf_path)
if reader.is_encrypted:
if reader.decrypt(password) == 0:
raise Exception("密码错误或文件损坏")
writer = PdfWriter()
total_pages = len(reader.pages)
for i, page in enumerate(reader.pages):
writer.add_page(page)
progress = (i + 1) / total_pages * 100
self.progress_bar['value'] = progress
self.root.update_idletasks()
writer.encrypt("", "", use_128bit=False)
with open(output_path, 'wb') as f:
writer.write(f)
self.progress_bar.pack_forget()
self.status.config(text=f'成功解密保存至:{output_path}')
messagebox.showinfo("完成", "PDF文件解密成功!")
except Exception as e:
if self.progress_bar:
self.progress_bar.pack_forget()
self.status.config(text=f'错误:{str(e)}')
messagebox.showerror("错误", f"解密失败:{str(e)}")
def start_word_to_pdf(self):
thread = threading.Thread(target=self.word_to_pdf)
thread.start()
def word_to_pdf(self):
try:
docx_path = filedialog.askopenfilename(
title='选择Word文档',
filetypes=[('Word文件', '*.docx *.doc')]
)
if not docx_path:
return
output_path = filedialog.asksaveasfilename(
title='保存PDF文件',
initialfile=os.path.splitext(os.path.basename(docx_path))[0] + '.pdf',
defaultextension='.pdf',
filetypes=[('PDF文件', '*.pdf')]
)
if not output_path:
return
self.status.config(text='正在转换Word文档...')
self.progress_bar = Progressbar(self.root, orient="horizontal", length=300, mode="determinate")
self.progress_bar.pack(pady=10)
try:
word = win32com.client.Dispatch('Word.Application')
doc = word.Documents.Open(docx_path)
try:
doc.SaveAs(output_path, FileFormat=17)
except Exception as e:
# 记录详细的错误信息
import traceback
error_log = traceback.format_exc()
print(f"保存文件时出错: {error_log}")
raise e
finally:
# 确保文档关闭
doc.Close()
# 确保 Word 应用程序退出
word.Quit()
self.progress_bar['value'] = 100
self.root.update_idletasks()
self.progress_bar.pack_forget()
self.status.config(text=f'成功转换:{os.path.basename(output_path)}')
messagebox.showinfo("完成", "Word转PDF成功!")
except Exception as e:
if self.progress_bar:
self.progress_bar.pack_forget()
error_msg = f"转换失败:{str(e)}\n请检查:\n1. 是否安装Microsoft Office\n2. Python与Office同为32位或64位版本\n3. 文件路径不要包含特殊字符"
self.status.config(text='错误:' + error_msg)
messagebox.showerror("错误", error_msg)
except Exception as e:
# 记录详细的错误信息
import traceback
error_log = traceback.format_exc()
print(f"调用 word_to_pdf 方法时出错: {error_log}")
def start_excel_to_pdf(self):
thread = threading.Thread(target=self.excel_to_pdf)
thread.start()
def excel_to_pdf(self):
try:
file_path = filedialog.askopenfilename(
title='选择Excel文件',
filetypes=[('Excel文件', '*.xls *.xlsx')]
)
if not file_path:
return
output_path = filedialog.asksaveasfilename(
title='保存PDF文件',
initialfile=os.path.splitext(os.path.basename(file_path))[0] + '.pdf',
defaultextension='.pdf',
filetypes=[('PDF文件', '*.pdf')]
)
if not output_path:
return
self.status.config(text='正在转换Excel...')
self.progress_bar = Progressbar(self.root, orient="horizontal", length=300, mode="determinate")
self.progress_bar.pack(pady=10)
excel = win32com.client.Dispatch('Excel.Application')
doc = excel.Workbooks.Open(file_path)
doc.ExportAsFixedFormat(0, output_path)
doc.Close()
excel.Quit()
self.progress_bar['value'] = 100
self.root.update_idletasks()
self.progress_bar.pack_forget()
self.status.config(text=f'转换完成: {os.path.basename(output_path)}')
messagebox.showinfo("完成", "Excel转PDF成功!")
except Exception as e:
if self.progress_bar:
self.progress_bar.pack_forget()
self.status.config(text=f'错误:{str(e)}')
messagebox.showerror("错误", f"转换失败:{str(e)}")
def start_ppt_to_pdf(self):
thread = threading.Thread(target=self.ppt_to_pdf)
thread.start()
def ppt_to_pdf(self):
try:
file_path = filedialog.askopenfilename(
title='选择PPT文件',
filetypes=[('PPT文件', '*.ppt *.pptx')]
)
if not file_path:
return
output_path = filedialog.asksaveasfilename(
title='保存PDF文件',
initialfile=os.path.splitext(os.path.basename(file_path))[0] + '.pdf',
defaultextension='.pdf',
filetypes=[('PDF文件', '*.pdf')]
)
if not output_path:
return
self.status.config(text='正在转换PPT...')
self.progress_bar = Progressbar(self.root, orient="horizontal", length=300, mode="determinate")
self.progress_bar.pack(pady=10)
powerpoint = win32com.client.Dispatch('PowerPoint.Application')
doc = powerpoint.Presentations.Open(file_path)
doc.SaveAs(output_path, 32) # 32是PDF格式
doc.Close()
powerpoint.Quit()
self.progress_bar['value'] = 100
self.root.update_idletasks()
self.progress_bar.pack_forget()
self.status.config(text=f'转换完成: {os.path.basename(output_path)}')
messagebox.showinfo("完成", "PPT转PDF成功!")
except Exception as e:
if self.progress_bar:
self.progress_bar.pack_forget()
self.status.config(text=f'错误:{str(e)}')
messagebox.showerror("错误", f"转换失败:{str(e)}")
def start_images_to_pdf(self):
thread = threading.Thread(target=self.images_to_pdf)
thread.start()
def images_to_pdf(self):
try:
file_paths = filedialog.askopenfilenames(
title='选择图片文件',
filetypes=[('图片文件', '*.jpg *.jpeg *.png')]
)
if not file_paths:
return
now = datetime.now().strftime('%Y%m%d%H%M%S')
output_path = filedialog.asksaveasfilename(
title='保存PDF文件',
initialfile= f'merged_{now}.pdf',
defaultextension='.pdf',
filetypes=[('PDF文件', '*.pdf')]
)
if not output_path:
return
self.status.config(text='正在生成PDF...')
self.progress_bar = Progressbar(self.root, orient="horizontal", length=300, mode="determinate")
self.progress_bar.pack(pady=10)
images = [Image.open(f) for f in file_paths]
total_images = len(images)
if images:
images[0].save(
output_path, "PDF", resolution=100.0,
save_all=True, append_images=images[1:]
)
self.progress_bar['value'] = 100
self.root.update_idletasks()
self.progress_bar.pack_forget()
self.status.config(text=f'成功生成PDF:{os.path.basename(output_path)}')
messagebox.showinfo("完成", "图片转PDF成功!")
except Exception as e:
if self.progress_bar:
self.progress_bar.pack_forget()
self.status.config(text=f'错误:{str(e)}')
messagebox.showerror("错误", f"转换失败:{str(e)}")
def get_images_from_pdf(self):
try:
pdf_path = filedialog.askopenfilename(
title='选择PDF文件',
filetypes=[('PDF文件', '*.pdf')]
)
if not pdf_path:
return
output_dir = filedialog.askdirectory(title='选择图片保存目录')
if not output_dir:
return
self.status.config(text='正在转换PDF...')
self.progress_bar = Progressbar(self.root, orient="horizontal", length=300, mode="determinate")
self.progress_bar.pack(pady=10)
reader = PdfReader(pdf_path)
total_pages = len(reader.pages)
# 获取 PDF 文件名(不含扩展名)
pdf_basename = os.path.splitext(os.path.basename(pdf_path))[0]
for i, page in enumerate(reader.pages):
for img in page.images:
# 过滤文件名中的不合法字符
valid_name = ''.join(c for c in img.name if c.isalnum() or c in (' ', '.', '_')).rstrip()
# 将图像模式转换为支持 PNG 格式的模式
image = Image.open(io.BytesIO(img.data))
if image.mode == 'PA':
image = image.convert('RGBA')
# 以 PDF 文件名作为前缀生成图片文件名
image_path = os.path.join(output_dir, f'{pdf_basename}_page_{i + 1}_{valid_name}')
image.save(image_path, 'PNG')
progress = (i + 1) / total_pages * 100
self.progress_bar['value'] = progress
self.root.update_idletasks()
self.progress_bar.pack_forget()
self.status.config(text=f'转换完成,保存至:{output_dir}')
messagebox.showinfo("完成", f"成功转换{len(reader.pages)}页!")
except Exception as e:
if self.progress_bar:
self.progress_bar.pack_forget()
self.status.config(text=f'错误:{str(e)}')
messagebox.showerror("错误", f"转换失败:{str(e)}")
if __name__ == "__main__":
app = FileConverterApp()
app.root.mainloop()感兴趣的同学,赶紧去体验吧!


















 360
360

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









