






问题描述:
python计算机二级综合应用,提取《八十天环游地球》题目和词频统计。
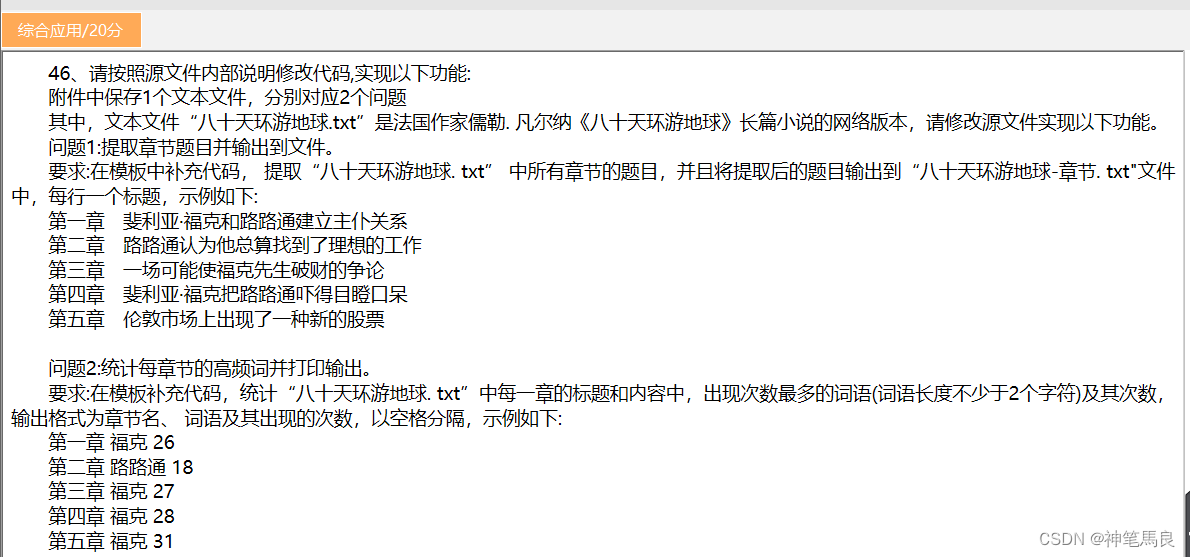
问题解答:
本人写的代码相比准确答案比较拙劣,仅提供一种思路,仅作参考。
第一问:
针对本问题,我以"章 "(两个英文空格)作为突破点,如果某一行中出现了这个关键点,说明他就是章节标题。
# 以下代码为提示框架
# 请在...处使用一行或多行代码替换
# 请在______处使用一行代码替换
#
# 注意:提示框架代码可以任意修改,以完成程序功能为准
fi = open("八十天环游地球.txt", encoding="utf-8")
fo = open("八十天环游地球-章节.txt", "w", encoding="utf-8")
lines=fi.readlines()
for line in lines:
if "章 " in line:
fo.write(line)
fi.close()
fo.close()
第二问:
针对本问题,我首先分析了一下文件内容,以"章 "(两个英文空格)作为突破点,将其作为分割得到每一章的大部分内容,缺失了几个字,不影响整体的词频统计。打印输出包含了标题的第几章,所以我将章节题目以空格作为分割得到第几章的列表。lt1和lt2两个列表包含打印输出的内容。
# 以下代码为提示框架
# 请在...处使用一行或多行代码替换
# 请在______处使用一行代码替换
#
# 注意:提示框架代码可以任意修改,以完成程序功能为准
import jieba
fi1 = open("八十天环游地球.txt", "r", encoding="utf-8")
fi2 = open("八十天环游地球-章节.txt", "r", encoding="utf-8")
ls=fi1.read().split("章 ")
lt1=[]
for i in ls[1:]:
d={}
i=jieba.lcut(i)
for j in i:
if len(j)>=2:
d[j]=d.get(j,0)+1
ls=list(d.items())
ls.sort(key= lambda x : x[1],reverse=True)
lt1.append(ls[0])
lines = fi2.readlines()
lt2=[]
for line in lines:
line=line.strip("\n")
line=line.split(" ")[0]
lt2.append(line)
for i in range(len(lt2)):
print(lt2[i]+" "+lt1[i][0]+" "+str(lt1[i][1]))
第一问的标准答案如下:
# 以下代码为提示框架
# 请在...处使用一行或多行代码替换
# 请在______处使用一行代码替换
#
# 注意:提示框架代码可以任意修改,以完成程序功能为准
f = open("八十天环游地球.txt", encoding="utf-8") # 读取源文件
fi = open("八十天环游地球-章节.txt", "w", encoding="utf-8") # 打开新文件
for i in f: # 遍历文本
text = i.split(" ")[0] # 章节中有空格进行分割 例如:第二章 路路通认为他总算找到了理想的工作
if text[0] == "第" and text[-1] == "章": # 取出第一段文本,如果首字符是第尾字符是章,代表是章节
fi.write("{}\n".format(i.replace("\n", ""))) # 格式化保存
fi.close()
f.close()
第二问的标准答案如下:
# 以下代码为提示框架
# 请在...处使用一行或多行代码替换
# 请在______处使用一行代码替换
#
# 注意:提示框架代码可以任意修改,以完成程序功能为准
import jieba
f1 = open("八十天环游地球.txt",'r',encoding="utf-8")
ls = f1.read().split('□ 作者:儒勒·凡尔纳')
f1.close()
Ls1 = []
for i in range(len(ls)-1):
d = {}
lt = jieba.lcut(ls[i])
for word in lt:
if 2 <= len(word):
d[word] = d.get(word,0)+1
items = list(d.items())
items.sort(key = lambda x:x[1],reverse = True)
Ls1.append(items[0])
f2 = open('八十天环游地球-章节.txt','r',encoding = 'utf-8')
Ls0 = []
for line in f2.readlines():
Ls0.append(line.strip('\n').split(' ')[0])
for j in range(len(Ls0)):
print('{} {} {}'.format(Ls0[j],Ls1[j][0],Ls1[j][1]))
f2.close()
总结下来,就是选择的分割点不一样,答案的第二问分割点选区的更好,而我的第一问的分割点选取的更好。

















 1094
1094











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











