






属于MTGNN,GCN网络用于多元时间序列的模型
Accepted by KDD 2020
主要创新
时序模型如LSTNet 和 TPA-LSTM 没有显式地对变量之间的成对依赖关系进行建模,这削弱了模型的可解释性。时空图神经网络以多元时间序列和外部图结构作为输入,旨在预测多元时间序列的未来值或标签。
然而,在大多数情况下,多元时间序列不具有显式的图结构。变量之间的关系必须从数据中发现,而不是作为基本真理性知识提供。尽管图结构是可用的,但大多数GNN方法只关注消息传递( GNN学习),而忽略了图结构不是最优的,应该在训练期间更新。
对此,论文提出GNN的方法挖掘多元时间序列的依赖关系,但面临多元时间应用GNN需要构建图结构与学习图和图结构。进而,论文提出的模型框架中主要有图学习层,将计算出稀疏的图邻接矩阵;图卷积模型,计算变量间的空间依赖;时序卷积层,计算时序关系且可以处理长序列。
模型结构拆解
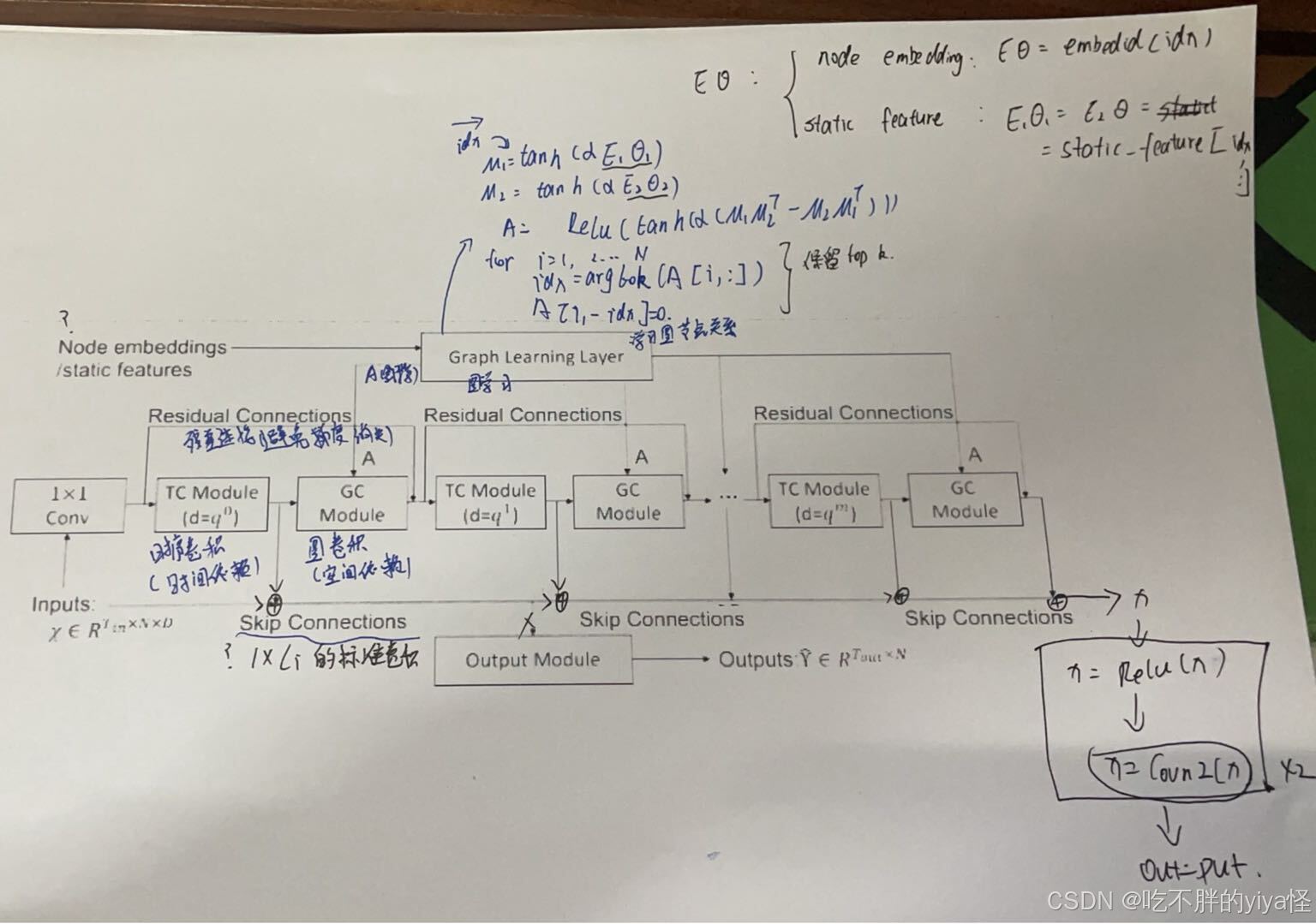
图学习层
图学习层是专门为提取单向关系而设计的,自适应地学习图邻接矩阵,以捕获时间序列数据之间的隐藏关系。
公式表示如上,代码实现:
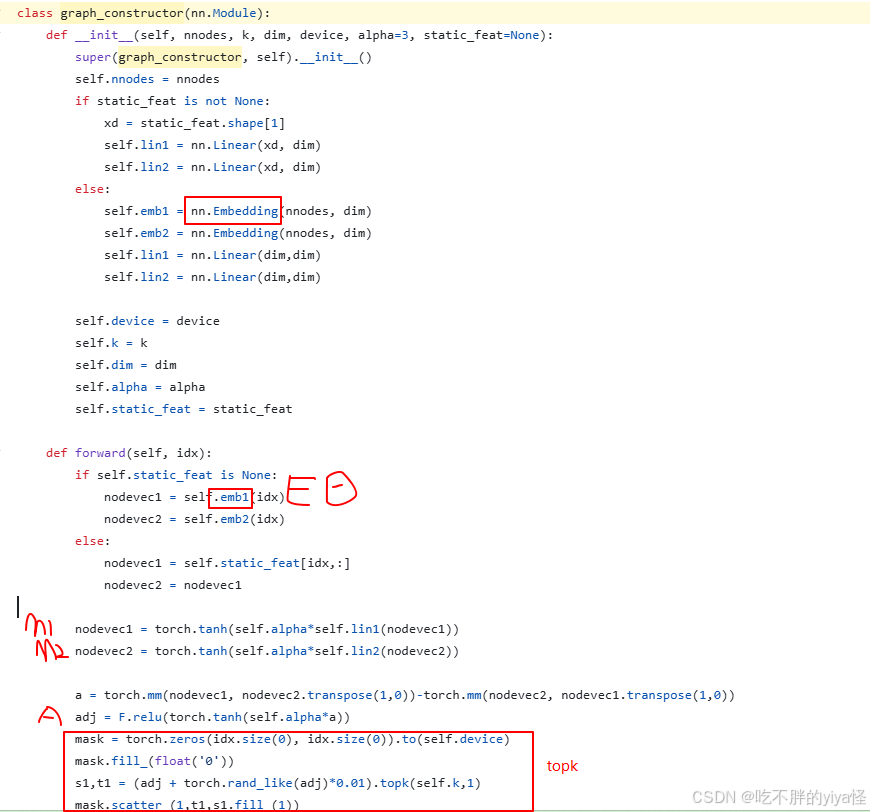
对于输入不局限于节点嵌入,也可以时静态节点矩阵(提前定义)。
这个部分会输出一个邻接矩阵用于后续的图卷积层
时序卷积层
作用:捕获时间序列模式,处理长序列能力

时序卷积层分为两个部分,都是1D convolution filters。其后的激活函数不同,后跟tanh的激活函数用于做过滤,后跟sigmoid的用作门,控制传递的信息量
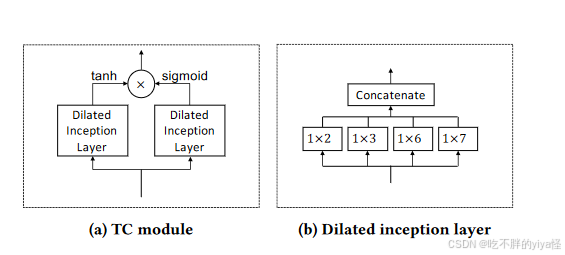
时间卷积模块通过 1D 卷积滤波器捕获时间序列数据的序列模式。
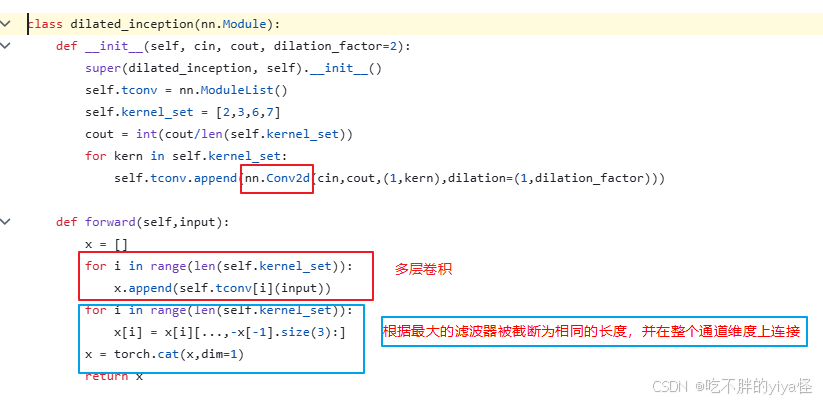
每个Dilated Inception层中有多个不同kernel size的卷积层,使用这种膨胀策略可以捕获比不使用它更长的序列。因为卷积网络的感受野大小随着网络的深度和滤波器的核大小呈线性进展增长,也就是说要处理非常长的序列,需要非常深的网络和非常大的过滤器,而感受野大小也随着隐藏层数量的增加而呈指数增长。故而通过堆叠网络深度和过滤器以达到处理长序列的目的。公式表示为:
![]()
代码实现为:
图卷积层
图卷积模块旨在将节点的信息与其邻居的信息融合,以处理图中的空间依赖关系。图卷积模块由两个 mixhop 传播层组成,分别处理通过每个节点传递的流入和流出信息。净流入信息是通过添加两个 mix-hop 传播层的输出来获得的。
Mix-hop Propagation Layer.:提出了混合跳跃传播层来处理空间相关节点上的信息流。它具有信息传播步骤和信息选择步骤:首先水平传播信息,然后垂直选择信息。信息传播步骤以递归方式将节点信息与给定的图形结构一起传播。
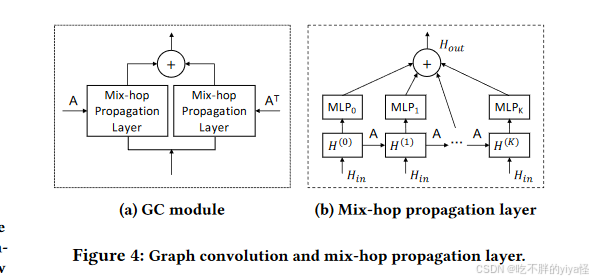
因为无论初始节点状态如何,具有许多层的图卷积网络都会达到随机游走的极限分布,从而导致了图卷积网络的一个严重限制:当图卷积层的数量趋于无穷大时,节点隐藏状态会收敛到一个点。所以论文中引入了信息选择步骤来过滤掉每个跃点产生的重要信息。根据公式 8,参数矩阵 W(k) 用作特征选择器。

GCN 面临过度平滑问题,因此来自较高跃点的信息可能不会对整体性能产生负面影响。对此论文中的方法在当前和邻居信息之间保持平衡,如这个公式使用求和来表示不同跃点
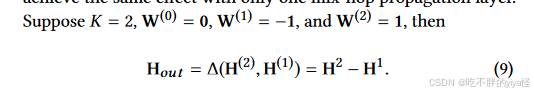

Skip Connection Layer
跳跃连接层本质上是1 × Li的标准卷积,其中Li是输入到第i个跳跃连接层的序列长度。
模型最后通过两层1×1卷积得到output

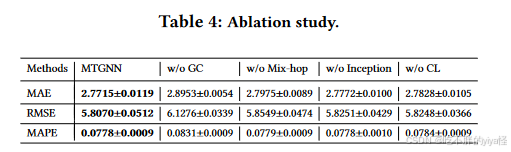
实验结果
大概看个消融实验,基本每个模块都是都是有点增益的

















 1374
1374

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









