







《Deformable image registration using convolutional neural networks》---2018
摘要:可变形图像配准可能很耗时,并且通常需要大量的参数化才能在特定的应用中表现良好。我们向基于三维卷积神经网络的配准框架迈出了一步。该网络直接学习成对三维图像之间的变换。网络的输出是薄板样条变换网格的x、y和z分量的三个映射。该网络是在合成随机变换的基础上训练的,该变换被应用于一小组用于期望应用的代表性图像。因此,训练不需要人工标注地面真实变形信息。该方法在吸气-呼气肺部CT图像对的公共数据集上进行了演示,该数据集带有用于评价配准质量的注释的相应标志。这种方法的优点包括注册时间快,参数化程度低。
注:三维卷积神经网络
直接学习成对的三维图像之间的变换
网络输出是薄板样条网格的x y z 的三个分量映射
训练不需要地面真实变形信息
优点:配准时间快,参数化程度低
1 介绍
最先进的可变形图像配准算法的一个常见问题是优化损失函数所需的时间。另一个问题是,配准算法的每一个新应用都需要特定的参数设置来实现最佳性能,即,被设计为在健康患者的高质量图像上工作良好的配准算法,不能保证在较低质量的图像或使用相同参数设置的包含病理的图像上工作。这些参数设置通常是手动调整或根本不调整。为了解决这些问题,我们提出了一种新的基于全卷积神经网络的配准方法。通过将图像配准转化为有监督的问题,可以训练配准算法,使得配准算法对于特定类别的图像特别优化,例如特定类型的病理或特定解剖,消除了对手动参数化的需要。所提出的方法直接从图像中估计两个输入图像的变换模型,导致非常快速的配准算法。
问题:(1)运算时间长 (2)鲁棒性
有监督 直接从图像中估计两个输入图像的变换模型
1.1医学图像配准中机器学习的相关工作
机器学习技术在图像配准中的应用已经在最近的论文中进行了研究。应用领域包括刚性2D-3D配准、对配准精度评分以及学习多模态相似性度量。最近的论文包括深度学习技术,如卷积神经网络,已应用于大量其他医学图像分析任务,如分割、形状建模和检测任务。1以前的工作使用机器学习技术直接执行刚性配准和弹性配准,以帮助优化相似性度量,学习相似性度量,并验证图像配准。Gouveia等人比较了应用于模拟x光配准问题的刚性2D-3D配准方法的多元回归方法。2Miao等人使用卷积神经网络来学习2D-3D配准中刚性配准参数的回归。3Guti errez-Becker等人开发了一种使用回归森林来学习多模态运动预测器的方法。这些运动预测器随后被用于估计刚性可变形多模态配准问题的更新步骤。Muenzing etal .索科蒂等人开发了能够分别基于配准误差的分类和回归来学习估计非线性配准的配准质量度量的方法。5、6埃本霍夫和普鲁伊姆开发了用于配准误差回归的卷积神经网络方法。7该方法是基于应用于一小组训练图像的人工变换来训练的。Simonovsky等人和吴等人使用卷积神经网络来学习用于多模态图像配准的相似性度量。
最近的工作还试图使用卷积神经网络来估计全位移矢量场。Sokooti等人使用卷积神经网络来估计来自相似配准的肺部CT图像的弹性变形。10De Vos等人使用卷积神经网络来配准来自4D CT的2D MNIST数据和2D切片,该卷积神经网络通过反向传播由归一化相关系数测量的固定和变换的运动图像之间的相似性度量来训练。11
1.2本文的目的
本文旨在说明使用卷积神经网络可以以非常高的速度估计3D医学图像的可变形变换。该网络学习配准两个3D肺部图像的薄板样条网格上的位移。训练不需要手动标注的一组地面真实图像,而是依赖于学习合成变换,该合成变换被应用于配准问题的一小组代表性图像。因此,不需要明确选择相似性度量,因为相关的特征和度量是从数据中隐含地学习到的。在本文中,我们在一个公共可用的肺部数据集上评估网络,该数据集不同于训练集,并带有用于计算目标配准误差的相应地标注释。
2 方法
2.1 变换模型
2.2网络架构
这些位移被定义在覆盖整个图像域的网格上。网络的输入是If和IM两个图像。网络的输出由三个映射组成,对应于位移dk的x、y和z分量。该网络基于较小版本的VGG架构12(图1)。与最初的VGG实现相比,我们有一对三维图像作为输入,而不是单个图像,并且不是计算一个输出,输出由对应于6 × 6 × 6 TPS网格的x、y和z分量的三个映射组成。所有卷积层都使用3 × 3 × 3的零填充核来保持层输入的大小。卷积之后是ReLU激活函数,除了最后的1 × 1 × 1卷积层,它没有激活函数,允许它对网格分量进行回归。每个卷积层之后是一个2 × 2 × 2的最大汇集层,该层沿每个轴对输入进行2倍下采样。
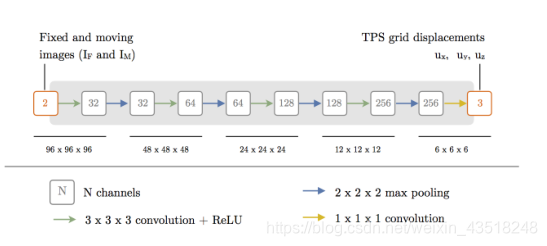
网络输入:IF 和 IM
网络输出:三个映射(x,y,z)
不同于VGG: 一对图像输入而非单个图像 输出是x y z三个方向的映射
2.3 训练
通过最小化估计位移的平方误差来训练网络,所述估计位移在估计向量的数量上是平均的
这种损失是用学习率衰减的随机梯度下降法优化的
我们使用单实例批处理(即批处理大小= 1),并在所有卷积层上使用过去迭代中归一化统计的指数移动平均值进行批处理归一化。在当前实现中,网络是在96 × 96 × 96体素图像上训练的。对于本摘要中的所有实验,在用于网络之前,使用四阶B样条插值将图像下采样到该大小。我们发现,当前的输入大小和架构是所需内存量和网络估计精度之间的一个很好的折衷。
优化函数:最小化位移均方误差
随机梯度下降算法
2.4 训练集
训练示例是通过应用合成变换从一小组图像构建的。对于训练期间的每次迭代,对来自训练集的图像I(x)应用小的随机仿射变换,这导致图像I(Toffset(x))。我们对同一幅图像应用了一个更大的变换,由偏移变换和第二个更大的变换组成,该变换实际上是由网络学习的(图2)。偏移变换作为一种数据增强形式,是一种纯仿射变换
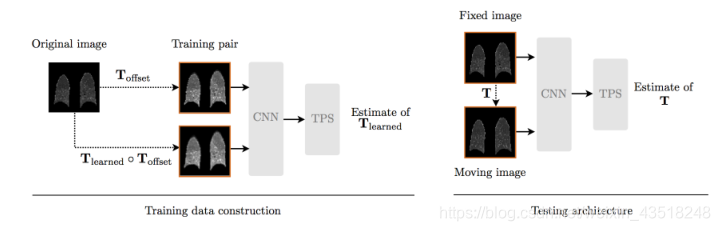
3D单位矩阵,以及从正态分布N(0,0.1)采样的B和B的元素(以体素为单位)。学习的转换被建模为TPS转换。等式(1)中的位移d被分配给均匀覆盖图像区域的6×6×6网格。位移的大小是从三维均匀分布中取样的。这种分布的范围需要根据预期的变形范围,根据应用进行设置。结合这两种变换,训练集中的每个数据由一对图像I(Toffset(x))和I((Tlearned♀Toffset(x))组成,以TPS变换网格Tlearned(x)为目标。这两种变换都是在小训练集中的图像上动态应用的,从而为每次迭代训练产生独特的输入。
2.5数据集
我们使用3D胸部CT图像来训练网络并验证我们的方法。这些数据来自两个数据集:用于验证的DIRLAB数据集14和用于训练的CREATIS数据集15。这些数据集分别包含10对和7对3D CT图像,显示吸气结束时和呼气结束时的肺。DIRLAB CT数据带有吸气和呼气帧的相应地标注释,每对图像有300个地标。由于呼吸运动导致肺部主要向上移动,训练期间TPS变换网格的位移范围设置为z方向的dz∑[1,5]体素(从下到上),而dx∑[1,1],dy∑[1,1]体素(对应于从右到左,从后到前)。我们将我们的方法的目标配准误差(TRE)与最先进的肺配准方法进行了比较,这些方法也在DIRLAB数据上进行了测试。
3 实验
为了测试网络估计肺部变形的能力,它在DIRLAB数据集的十对吸气-呼气对上运行。图4显示了我们的方法在TRE的改进。图表显示了大变形(配准前大于10毫米)的明显改善。矢量场的x、y和z分量的相关图显示了地面真实值和估计值之间的相关性,其中x、y和z位移的皮尔逊相关系数分别为0.54、0.65和0.80(图3)。为了解决肋骨相对于肺组织的滑动,配准限于使用肺掩模提取的肺场。表1显示了使用带注释的地标测量的目标配准误差以及与其他方法的比较。注意,比较的算法都明确地模拟了肋骨和肺的滑动界面;一些不包括在我们的算法中的东西,这可能导致更大的TRE值。在NVIDIA Titan X GPU上估计转换平均需要55±5毫秒,而吴等人的方法需要100分钟,Delmon等人的方法需要58分钟。Schmidt-Richtberg等人和Berendsen等人的方法的时序信息在文献中没有报道

















 2477
2477

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









