







**
图计算:社区发现算法
**
社区划分问题大多基于这样一个假设:同一社区内部的节点连接较为紧密,社区之间的节点连接较为稀疏。因此,社区发现本质上就是网络中结构紧密的节点的聚类。
从这个角度来说,这跟聚类算法一样,社区划分问题主要有两种思路:
(1)凝聚方法(agglomerative method):添加边
(2)分裂方法(divisive method):移除边
另一方面,我们也可以认为同一个社区内的节点,之所以能够聚集在一起,是因为它们有相似性。因此只要我们能够将一个节点很好地表示,成为一个向量,那么同样可以用相似性大法来寻找社区聚集,不过这点上需要向量对节点的描述足够好和足够完备。
GN算法据说是社区发现领域的第一个算法,或者说它开启了这个领域的研究。下面我们来分别介绍这个领域及其算法是如何演化的。
1、GN算法
基本思想:
在一个网络之中,通过社区内部的边的最短路径相对较少,而通过社区之间的边的最短路径的数目则相对较多。
边介数(betweenness):
网络中任意两个节点通过此边的最短路径的数目。
算法过程:
(1)计算每一条边的边介数;
(2)删除边界数最大的边;
(3)重新计算网络中剩下的边的边阶数;
(4)重复(3)和(4)步骤,直到网络中的任一顶点作为一个社区为止。
GN算法是一个基于删除边的算法。这种算法类似于分裂一样,把一个大的网络,以边介数为衡量,去不断删除边,以实现网络分裂。这种方法的缺点:(1)计算复杂度高,在每次删除边了之后都会重复计算剩余节点的边介数;(2)算法的终止条件缺乏一个衡量的目标,不能控制最后可以分裂成多少个社区;
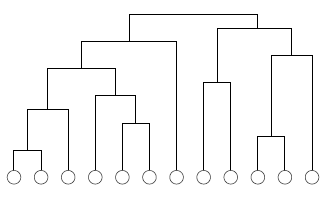
如上图所示,GN算法相当于是一棵自顶向下的层次树,划分社区就是层次分裂的过程。
解决的办法:
引入模块度Q,模块度是用来衡量社区划分好坏的程度的概念。除此之外,我觉得基本上整个算法的思想都反过来了,不再是从顶层分裂,而是从底层合并聚类,直到最终形成一个大的网络。每次是根据计算合并后使得模块度Q的增量最大的社区进行合并,直到收敛。也就是说,是基于增加边而不是删除边了。这种引入模块度Q来度量社区划分质量的思想,有点像梯度下降算法,是通过迭代计算来获得定义的目标函数的最优解的。
2、Label Propagation
标签传播算法也是一种自底向上的迭代算法。
初始的时候对每一个节点给一个类别,以后每次迭代,对于每个节点,将与它相连的邻居里面数量最多的类别作为这个节点的新类别。直到整个网络的节点类别都不再变化为止。
标签传播算法(label propagation)的思想基于:相似的数据应该具有相同的label。其具体实现包括两大步骤:1)构造相似矩阵;2)勇敢的传播吧。
有向图的Label Propagation算法:
将有向图转换成无向图,使得节点之间的关系带权重。
具体是构造一个转移概率矩阵P,以及一个节点的分类标签矩阵F。然后计算 F=PF。
3、随机游走算法
随机游走算法的“随机”是指:以相同的概率来从一个顶点移动到另一个顶点。或者说,以某一个定义好的概率作为转移概率,以“移动”的概念,比喻节点的状态的改变。网络图中的每一个节点代表一种状态,不同状态之间转移的概率为: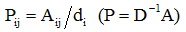 ,其中A是邻接/相似度矩阵,D是度矩阵,di是节点i的度。t 步随机游走从 i 到 j 的概率是 Pij 的t次幂,表示为Ptij。
,其中A是邻接/相似度矩阵,D是度矩阵,di是节点i的度。t 步随机游走从 i 到 j 的概率是 Pij 的t次幂,表示为Ptij。
随机游走中的一个经典算法,叫做WalkTrap算法。
定义一些距离:
(1)定点i和j的距离: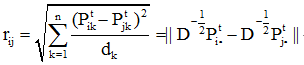 (由转移概率的定义得到)
(由转移概率的定义得到)
(2)社团C到点j的距离: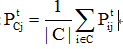
(3)社团C1到C2的距离: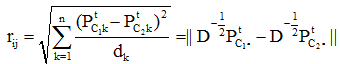 (由(1)(2)式得到)
(由(1)(2)式得到)
算法步骤:
Step1 每一个点当做一个社区,计算相邻的点(社团)之间的距离
Step2 选取使得下式最小的两个社团C1和C2 合并为一个社团,
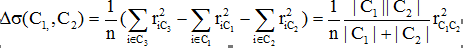
重复这一步骤直到所有点合并为一个社团。
随机游走算法尽管速度快,但是效果并不太理想(为什么?)。
4、FastUnfolding
不管是GN算法、LPA还是随机游走,它们都有一个缺点,就是没有一个明确的量化指标用来衡量算法对社区划分的好坏。也就是说,不知道运算到什么程度了就是最好的结果。比如GN算法,是自顶向下的分裂,那么分裂到什么程度了就可以停止了呢?再比如LPA,迭代多少次停止才最好呢,当图中有一些异常的节点或者特殊的节点时,会不会导致标签一直震荡,以至最后难以得到最优解?为了使得社区划分算法有一个可衡量的标准,提出了“模块度”的概念。
FastUnfolding就是一种基于模块度的,自底向上聚集的社区划分算法。
FastUnfolding的算法步骤:
初始化,将每个点划分在不同的社区中;
对每个节点,将每个点尝试划分到与其邻接的点所在的社区中,计算此时的模块度,判断划分前后的模块度的差值ΔQ是否为正数,若为正数,则接受本次的划分,若不为正数,则放弃本次的划分;
重复以上的过程,直到不能再增大模块度为止;
构造新图,新图中的每个点代表的是步骤3中划出来的每个社区,继续执行步骤2和步骤3,直到社区的结构不再改变为止。
5、BGLL算法
是基于模块度Q的两次启发式迭代算法。外层是凝聚法,内层是凝聚+节点置换,克服了简单凝聚法中两个节点一旦合并就无法分开的问题。
6、谱聚类
7、其他的各种聚类算法
参考:http://blog.csdn.net/aspirinvagrant/article/details/45599071 (GN算法)
http://blog.csdn.net/google19890102/article/details/48660239 (FastUnfolding算法)
http://blog.csdn.net/google19890102/article/details/51558148 (Label Propagation 算法)
http://www.cnblogs.com/tychyg/p/5277137.html (介绍了各种社区聚类的算法)















 4436
4436











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









