









【Paper Reading】All-but-the-Top: Simple and Effective Postprocessing for Word Representations
Paper Url. Accepted by ICLR 2018.
搞清楚如何减的D维的PCA,figure out why do this?
Abstract
实值词表示已经转化为NLP应用;最常见的例子是word2vec和GloVe,这两种语言因其捕捉语言规律的能力而得到认可。在本文中,我们演示了一种非常简单,但反直觉的后处理技术,消除了单词向量中的公共平均向量和一些主要方向,从而使当前的文本表示更加强大。后处理是实证验证各种lexical-level内在任务(文字相似、概念分类、词类比)和字面意思任务(语义结构相似性和文本分类)在多个数据集和各种表示方法和hyperparameter选择多种语言;在每一种情况下,经过处理的表示始终比原始表示好。
1. Intuition& Explaination
- 单词表示具有非零均值——实际的单词向量共享一个大的公共向量(范数高达单词向量平均范数的一半)。
- 去除均值向量后,词表示就不再是各向同性了——事实上,大多数单词向量的大部分“energy”都包含在一个非常低维的子空间中(比如,300个维度中的8个)。
由于所有单词都有相同的公共向量,他们代表着相同的支配方向来影响单词的表示,为消除这部分common vector的做法:
- 从所有词向量中去除非零均值向量,有效降低能量
- 将表示投影到远离主导D方向,有效地降低维数。经验选取 D = d 100 D=\frac{d}{100} D=100d,即D选取PCA表示的后面99%的维度。
在此作者强调:
这种后处理确实是反直觉的。
我们通常是通过降维去噪是通过消除最弱的方向(在堆叠词向量的奇异值分解中)。
然而,该后处理产生了一个更“净化”和更“各向同性”的词表示,能够捕获更强的语言规律(capture stronger linguistic regularities. )
2. Postprocessing Method
2.1 Algo

作者特意提到了平均范数这个概念。是想强调,均值的平均范数占整体越大,代表他们的common vector对整体的影响越大(越是non-zero vector,越偏离欧式空间的单位球的球心。)

各种词向量的奇异值衰减,用来说明前D维的方差贡献率最大.
作者想证明:词向量在低维子空间上的点(其到原点的距离是词向量平均范数的一小部分)周围是各向同性的。

算法步骤:中心化后直接抽掉前面方差贡献率最大的几列(一般是抽掉 0.01 × d 0.01\times d 0.01×d)去做下游后续任务
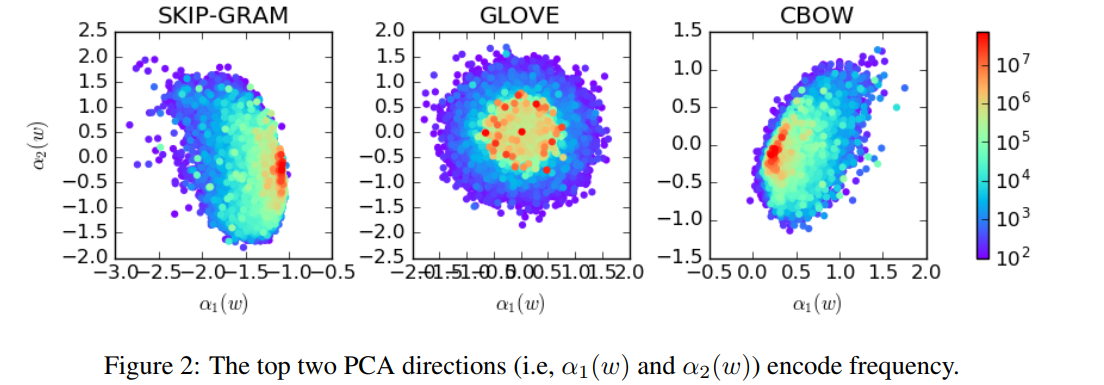
Fig2展示了Top2的PCA系数坐标和词频之间的关系,从图中可以看到两者也存在较强的相关性的。
2.2 数值解释
如何衡量各向同性程度?
基于
Z
(
c
)
=
∑
w
∈
V
exp
(
c
⊤
v
(
w
)
)
Z(c)=\sum_{w \in \mathcal{V}} \exp \left(c^{\top} v(w)\right)
Z(c)=∑w∈Vexp(c⊤v(w))在
c
c
c为一个单位向量时数值基本不变的假设,设立指标:
I
(
{
v
(
w
)
}
)
=
min
∥
c
∥
=
1
Z
(
c
)
max
∥
c
∥
=
1
Z
(
c
)
I(\{v(w)\})=\frac{\min _{\|c\|=1} Z(c)}{\max _{\|c\|=1} Z(c)}
I({v(w)})=max∥c∥=1Z(c)min∥c∥=1Z(c)
I
(
{
v
(
w
)
}
)
I(\{v(w)\})
I({v(w)})取值0-1,越趋向于0说明越各向异性,越趋向于1说明越各向同性。
下面举个栗子:
## For instance, a是由三个词组成的表示为dim=4的text embedding matrix
In [3]: a = np.array([[0.1,0.2,0.3,0.4],[0.4,1.3,0.9,2.1],[3.1,0.3,0.6,0.01]])
In [4]: a
Out[4]:
array([[0.1 , 0.2 , 0.3 , 0.4 ],
[0.4 , 1.3 , 0.9 , 2.1 ],
[3.1 , 0.3 , 0.6 , 0.01]])
In [5]: c=np.array([0.5,0.5,0.5,0.5]) #c_1 = 1/sqrt(dim=4) = 1/2
In [6]: c
Out[6]: array([0.5, 0.5, 0.5, 0.5])
In [7]: a[0].dot(c.T).sum()
Out[7]: 0.5
In [9]: a[1].dot(c.T).sum()
Out[9]: 2.35
In [10]: a[2].dot(c.T).sum()
Out[10]: 2.005
In [12]: isotropy = 0.5/2.35
In [13]: isotropy
Out[13]: 0.2127659574468085
是否可以借鉴统计学中变异系数的概念。 c v = σ μ c_v = \frac{\sigma}{\mu} cv=μσ。
变异系数和极差、标准差和方差一样,都是反映数据离散程度的绝对值。其数据大小不仅受变量值离散程度的影响,而且还受变量值平均水平大小的影响,没有量纲的影响。
此例中
iso = z_c.std()/z_c.mean()= 0.49633
但是要枚举出所有任意的单位向量是不可能的,实际取值:
I
(
{
v
(
w
)
}
)
≈
min
c
∈
C
Z
(
c
)
max
c
∈
C
Z
(
c
)
I(\{v(w)\}) \approx \frac{\min _{c \in C} Z(c)}{\max _{c \in C} Z(c)}
I({v(w)})≈maxc∈CZ(c)minc∈CZ(c)
其中
C
C
C是
V
T
V
V^TV
VTV的特征向量。(特征值分解中能够保证特征向量时unit vector)
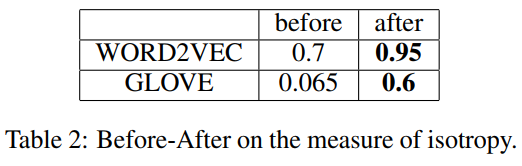
后处理之后iso基本都大幅提升。
3. Experiments
3.1单词相似度任务

单词相似度任务测试表征在多大程度上捕获了两个词之间的相似度,平均提高了2.3%
3.2 概念分类任务
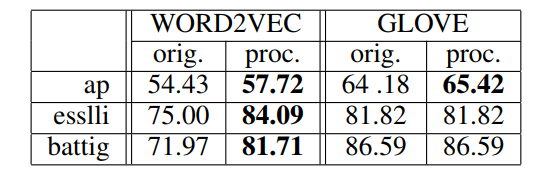
文本聚类数据集。然后根据纯度即正确分类的对象总数的比例来评估聚类性能,平均提高了2.5%
3.3 类比构词法
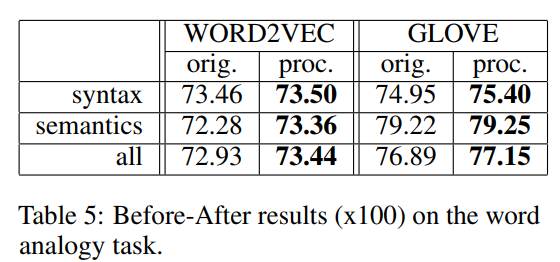
类比任务测试词的表征在多大程度上可以编码一对词之间的潜在语言关系。例如北京对中国如同华盛顿对美国。
3.4 语义文本相似度

预测任务。测试算法在多大程度上可以捕获两个句子之间的语义等价。对于每一对句子,算法需要衡量这两个句子的相似程度。平均提升4%。
3.5 文本分类
原文中前四个任务都是无监督的,得到文本表示就可以得到最终output;文本分类是单独拿做一章的

每组向量调节超参 D ∈ [ 0 , 4 ] D\in[0,4] D∈[0,4],设置组别分别抽去D列数据,得到最好的一组实验。CNN上面提升的最高平均提升了2.32%。
4. Discussion
所有的神经网络结构在每个节点上实现隐藏/输入状态向量的线性处理,所以文本提出的postprocess操作原则上可以由神经网络自动学习,只要这种内部学习与端到端训练示例一致。然而,在实践中,由于优化程序(SGD)和样本噪声的限制,这是复杂的。















 1747
1747











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









