









LDA2vec Explore Exp on AGNews Dataset
@date: 2022/07/05
@paper: Mixing Dirichlet Topic Models and Word Embeddings to Make lda2vec (Submitted to CoNLL2016)
@author: SUFEHeisenberg
@Github Url: lda2vec-pytorch
Method
LDA2vec通过混合word2vec的skip-gram架构和dirichlet优化的稀疏主题混合来构建单词和文档的表示。
v e c = w d v e c + d o c v e c = s k i p g r a m v e c + d o c w e i g h t ⊗ t o p i c m a t vec = wdvec+docvec=skipgramvec+docweight \otimes topicmat vec=wdvec+docvec=skipgramvec+docweight⊗topicmat

L = L neg + L d \mathcal{L} = \mathcal{L}^{\text{neg}}+\mathcal{L}^{d} L=Lneg+Ld, which are as followings:
Skipgram Negative Sampling Loss:
L neg = log σ ( c j ⃗ ⋅ w i ⃗ ) + ∑ l = 0 n log σ ( − c j ⃗ ⋅ w l ⃗ ) ) \mathcal{L}^{\text{neg}} = \log{\sigma(\vec{c_j}\cdot\vec{w_i})}+\sum^n_{l=0}\log{\sigma(-\vec{c_j}\cdot\vec{w_l}))} Lneg=logσ(cj⋅wi)+∑l=0nlogσ(−cj⋅wl)), where c j ⃗ = w j ⃗ + d j ⃗ \vec{c_j}=\vec{w_j}+\vec{d_j} cj=wj+dj; c j ⃗ \vec{c_j} cj cotext vector, w i ⃗ \vec{w_i} wi target word vector, w j ⃗ \vec{w_j} wj pivod word vector, w l ⃗ \vec{w_l} wl negatively-sampled word vector.
Dirichlet likelihood term:
L d = λ Σ j k ( α − 1 ) log p j k \mathcal{L}^d = \lambda\Sigma_{jk}(\alpha-1)\log{p_{jk}} Ld=λΣjk(α−1)logpjk
Dataset
AGNews 新闻文本数据集,train: #120000; test: #7600
政治/体育/财经/科技四类,样本均衡,即每个label下样本个数全相等。
Exp
w2v_emb_dim = 50;
batch_size=1024*7;
n_epochs=10;
n_Topics = 4/8/12/16
1. Topic Words
n=4

主题数较少时,能够较好地归纳总结出主题关键词。
n=8

n=12
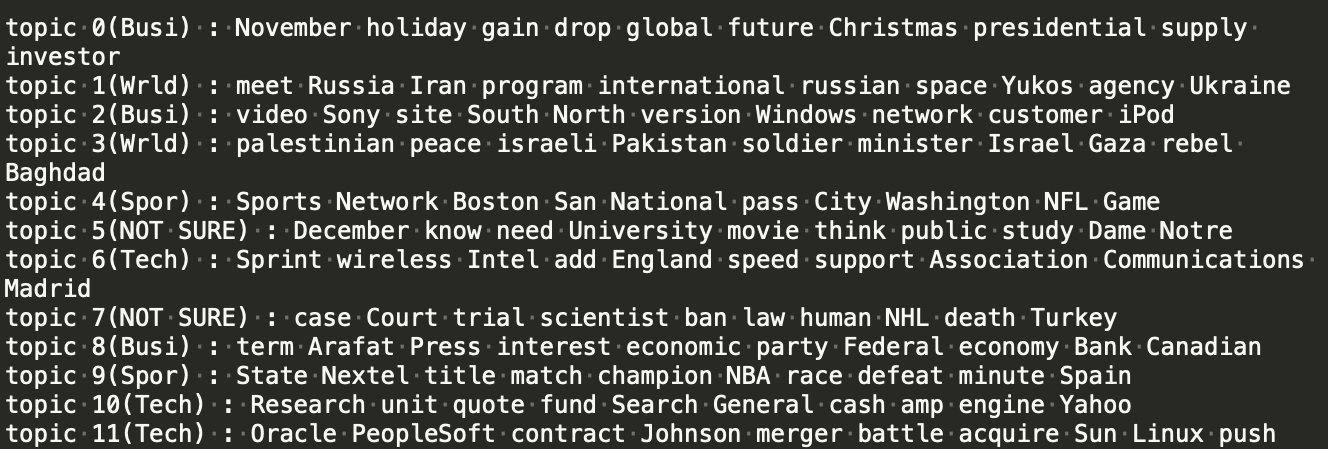
n=16

主题数目较多时,能够挖掘出的关键词总数多,但某些主题内关键词质量比较差。
2. Visualization
2.1 Vanilla LDA




vanilla LDA-4时,overlap较高;为16时,分离度明显增加。
2.2 Learned Docs Vectors

和vanilla LDA-4相比,红绿分离度增加,说明doc vectors还是能学习到整体语义的。



主题数越高分离度越高。
2.3 Learned Topic Distribution




4. Other Statistics Evaluation




3. Example Analysis
3.1 DOCUMENT:
Comets, Asteroids and Planets around a Nearby Star (SPACE.com) SPACE.com - A nearby star thought to harbor comets and asteroids now appears to be home to planets, too. The presumed worlds are smaller than Jupiter and could be as tiny as Pluto, new observations suggest.
Groundtruth: Sci/Tech
3.2 DISTRIBUTION OVER TOPICS:
n_topics=4
DISTRIBUTION OVER TOPICS:
1:0.217 2:0.230 3:0.222 4:0.330
TOP TOPICS:
topic 4 : near Baghdad american hostage outside northern death soldier capital area
topic 2 : Boston England match Yankees finish field champion career goal Sports
topic 3 : accuse step trial case settle order support member federal ask
n_topics=8
DISTRIBUTION OVER TOPICS:
1:0.125 2:0.133 3:0.133 4:0.110 5:0.108 6:0.110
7:0.169 8:0.112
TOP TOPICS:
topic 7 : bring international meet school nearly national follow despite issue WASHINGTON
topic 2 : remain place break miss fourth past series fan double little
topic 3 : remain american international bring nearly despite die fear stop mark
n_topics=12
DISTRIBUTION OVER TOPICS:
1:0.068 2:0.074 3:0.082 4:0.088 5:0.079 6:0.096
7:0.074 8:0.121 9:0.081 10:0.079 11:0.078 12:0.080
TOP TOPICS:
topic 8 : bring know number follow WASHINGTON prepare break step effort case
topic 6 : follow number know campaign result break fight tell spend step
topic 4 : american woman hostage soldier foreign worker militant international rebel Baghdad
n_topics=16
DISTRIBUTION OVER TOPICS:
1:0.059 2:0.071 3:0.066 4:0.069 5:0.057 6:0.073
7:0.054 8:0.055 9:0.053 10:0.072 11:0.059 12:0.058
13:0.057 14:0.060 15:0.077 16:0.060
TOP TOPICS:
topic 15 : support aim site use step allow campaign follow result provide
topic 6 : follow step number fail need result fight WASHINGTON accuse federal
topic 10 : number site move grow follow key step need target use
4. CLF Report
利用Learned doc vectors接线性全连接层 linear classifier:

Best Result:
accu:
0.5720462219052607
clf_report:
precision recall f1-score support
World 0.5876 0.6317 0.6088 22479
Sports 0.7256 0.8036 0.7626 22466
Business 0.4604 0.3730 0.4121 22420
Sci/Tech 0.4759 0.4791 0.4775 22376
accuracy 0.5720 89741
macro avg 0.5623 0.5718 0.5653 89741
weighted avg 0.5625 0.5720 0.5654 89741
confusion_matrix:
[[14199 2840 3025 2415]
[ 1795 18054 1166 1451]
[ 3975 2140 8362 7943]
[ 4197 1848 5610 10721]]















 4640
4640











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









