







Apple detection during different growth stages in orchards using the improved YOLO-V3 model
improved YOLO-V3 model
)
引言
果园中苹果的实时检测是判断苹果生长阶段和估计产量的重要手段之一。苹果的大小、颜色、簇密度和其他生长特性会随着苹果的生长而变化。传统的检测方法只能检测某一特定生长期的苹果,而不能适用于同一模型下不同生长期的苹果。我们提出了一种改进的yolo3模型,用于在光照波动、背景复杂、苹果重叠、枝叶交错的果园中检测不同生长阶段的苹果。年轻的苹果,膨胀的苹果和成熟的苹果的图像最初被收集。然后使用旋转变换、色彩平衡变换、亮度变换和模糊处理对这些图像进行增强。增强图像用于创建训练集。在YOLO-V3网络中,DenseNet方法被用来处理低分辨率的特征层。这有效地增强了特征传播,促进了特征重用,提高了网络性能。对模型进行训练后,在测试数据集上对训练后的模型进行性能测试。试验结果表明,所提出的yolov3稠密模型优于原yolo3模型和速度更快的R-CNN - VGG16网络模型,后者是目前最先进的水果检测模型。该模型的平均检测时间为每帧0.304 s,分辨率为30003000,可以实时检测果园中的苹果。此外,yolov3稠密模型可以有效地提供重叠苹果和遮挡条件下的苹果检测,并可应用于果园的实际环境中。
1、介绍和相关工作
如今,农场和果园的劳动力主要依靠熟练的农民。体力劳动消耗时间,增加生产成本,缺乏知识和经验的工人会犯不必要的错误。随着精准农业和信息技术的发展,作物成像已经成为收集作物生长信息的重要手段(Zhao et al., 2016)。智能农业已经成为一个流行的概念(Tyagi, 2016),图像信息可以用来准确判断作物生长和估计作物产量(Wang et al., 2013)。农业生产的自动化也使持续监测作物生长和营养状况成为可能,从而实现独立的农业管理和控制。
果园中波动的光照、复杂的背景、密集的水果分布、重叠的水果、枝叶、相机的视角、距离等因素都会对目标检测产生一定的影响。许多研究人员提供和改进了作物检测和定位的不同算法。Hamuda等(2018)利用卡尔曼滤波和匈牙利算法对田间作物进行检测。这些试验在没有重叠作物的情况下进行。图像的背景是土壤,相对简单,因此该方法不适合检测遮挡密集分布的果实。Lu和Sang(2015)提出了一种基于颜色和轮廓信息的变化冠层光照下的柑橘果实识别方法。该方法能适应复杂光照和背景的自然环境,但在柑橘图像较小的情况下,检测性能较差。Linker等(2012)提出了一种在自然光照条件下检测苹果的方法。该方法利用颜色和平滑度来检测一组高概率属于苹果的像素,并形成一个种子区域。然后,该方法根据种子区域与苹果模型的重合率来确定该区域是否包含苹果。该方法能有效地检测出含有苹果的区域,但在苹果分布密集、重叠较大的情况下,会产生较大的误差。
随着机器学习的发展,深度学习技术在农业中得到了广泛的应用。深度学习可以用于作物分类,作物图像分割,作物目标探测,还有另外任务。作物分类是作物检测的基础。Zhang等(2017)设计了13层卷积神经网络(CNN)进行水果分类,准确率为94.94%。该算法是目前最先进的水果分类方法。目标检测是指对图像进行类别分类和目标定位。基于深度学习的图像分割是目标检测的方法之一。通过对目标区域的分割,可以计算出图像中目标区域的数量和位置。Chen等(2017)使用基于全连通CNNs的blob检测器提取图像中的候选区域,分割目标区域,并使用后续的CNN计数算法计算水果的数量。Dyrmann et al. (2017)使用一个全连接的CNN自动检测杂草,当许多叶子在图像中被阻挡。为了在复杂的自然环境中更准确的分割目标区域,Dias et al. (2018)使用CNN和支持向量机(SVM)方法自动提取复杂背景下的苹果花特征;该方法得到了较为准确的苹果花区域分割结果。基于深度学习的图像分割方法在作物面积分割中取得了良好的效果。然而,这些方法不能准确地分割出每个目标在严重重叠的作物中的区域。Faster R-CNN(Ren et al., 2016)使用区域建议网络(RPN)方法检测图像中的感兴趣区域(RoI)。然后使用分类器对边界框进行分类,并使用微调对边界框进行处理。最后,可以准确地检测出目标。对作物检测、作物产量估算、作物生长判断和农业管理具有指导意义。Bargoti and Underwood (2016), Inkyu et al.
(2016)采用Faster R-CNN方法检测多种水果,效果良好。使用VGG16 net的Faster R-CNN (Simonyan和Zisserman, 2014)是水果检测的最新方法(Kamilaris和Prenafeta-Boldu, 2018)。然而,Faster R-CNN由两部分组成:区域建议网络(RPN)和分类网络,因此检测速度较慢,不能产生高分辨率的实时结果。
You Only Look Once (YOLO)方法(Redmon et al., 2016;Redmon和Farhadi(2017、2018)将目标分类和定位统一为一个回归问题。YOLO网络不需要RPN,直接对图像中的目标进行回归检测。网络提供了更快的检测。最新版本(YOLO-V3)不仅具有较高的检测精度和速度,而且对小目标的检测性能也很好。然而,YOLO-V3模型并没有被广泛用于水果检测。
在深度神经网络中,由于卷积和下采样操作的使用,特征图逐渐缩小。DenseNet体系结构(Huang et al., 2017)是为了更有效地利用神经网络的输入特征而提出的。在DenseNet体系结构中,每一层都使用来自前面所有层的特征映射作为输入,而它自己的特征映射用作所有后续层的输入。这些特征图通过深度连接连接起来。DenseNet的基本结构主要由两部分组成:致密块和过渡层。密集块是一组密集连接的特征图。相邻的两个密集块之间的层称为过渡层,通过卷积和池化来改变feature map的大小。DenseNet在神经网络中的应用加强了特征的传播,有效地解决了消失梯度问题,提高了神经网络的分类精度。
在观看苹果图像时,果园的光照条件是不恒定的,背景是复杂的,相机的观看距离不是固定的,苹果密集分布和重叠,无处不在的枝叶遮蔽着果实。这些问题对果园苹果的检测提出了很大的挑战。不同生长阶段苹果的大小、颜色和密度也不同。苹果很小,绿色,在年轻时密集地聚集在一起。在扩展期间,由于修剪和其他农业活动,苹果的体积变大,颜色变化,簇密度下降。在成熟阶段,苹果很大,通常是红色或红黄色,分布稀疏。传统的方法不适合在复杂多变的环境中检测不同生长阶段的苹果。在深度学习方法的准确性和实时性之间也存在权衡。为了更好的解决这些问题,本研究采用了最先进的yoloo - v3算法(Redmon and Farhadi, 2018)对苹果进行实时检测。为了提高YOLO-V3网络的检测性能,采用DenseNet对低分辨率的特征层进行优化。收集主要生长阶段的苹果图像,包括幼苹果、膨大苹果和成熟苹果,作为输入数据用于训练神经网络。将训练好的神经网络用于苹果的检测和生长阶段的识别。
论文的其余部分组织如下。第2节介绍了对图像数据集进行预处理的方法,包括图像采集、图像数据扩充和图像数据集的创建。第3节介绍了改进的YOLO-V3算法,该算法融合了DenseNet方法。第四部分介绍了相关实验,并对实验结果进行了讨论。最后,介绍了本文的研究结论和展望。
2、图像数据预处理
2.1、图像数据采集
在本研究中,在不同的生长阶段,使用分辨率为30004000像素的相机进行图像采集。果园位于中国河南灵宝。
本文使用的图像数据是在多云和晴天的苹果果园中采集的。收集时间包括上午8时。,下午1点。,下午五时三十分。照明条件包括前照明、背光、侧光和散射照明。在图像采集过程中,为了模拟前照,相机的观察方向与太阳光的照射方向平行。相机反平行于阳光照射方向,模拟背光。相机瞄准垂直于阳光照射方向,模拟侧滑。图像也在多云条件下收集,以模拟散射照明。
在三个生长阶段,从果园中分别采集了320张苹果图像。在每个生长阶段,随机选取一半的苹果图像用于训练集。考虑到相机的视角会影响检测性能,在采集图像时,会从多个视角采集一些图像。在选择的480幅图像中,在改变视角的情况下收集了94幅图像,其中包括30个幼苹果、32个膨大的苹果和32个成熟的苹果。
然后,使用数据扩充方法将这480幅图像扩展为4800幅图像,生成训练数据集。利用训练数据集训练检测模型。剩下的480张图像作为测试数据集,验证了yolov3 - density模型的检测性能。
2.2、图像数据增加
对果园苹果进行了检测,并对苹果的生长阶段进行了判断。由于白天光照的角度和强度变化很大,神经网络能否处理一天中不同时间采集的图像取决于训练数据集的完整性。为了增强实验数据集的丰富性,对采集到的图像进行了色彩、亮度、旋转、图像清晰度等预处理,并对数据集进行了扩充,如图1所示。
 图1所示。图像增强方法:(a)原始图像,(b) 90顺时针旋转,© 180顺时针旋转,(d) 270顺时针旋转,(e)水平镜面,(f)色彩平衡处理,(g-i)亮度变换,(j)模糊处理。
图1所示。图像增强方法:(a)原始图像,(b) 90顺时针旋转,© 180顺时针旋转,(d) 270顺时针旋转,(e)水平镜面,(f)色彩平衡处理,(g-i)亮度变换,(j)模糊处理。
2.2.1、数据增强:图像色彩
人类的视觉系统可以在不断变化的光线和成像条件下确定物体表面的颜色不变性,但成像设备却没有这种颜色不变性。不同的光照条件会导致图像色彩与真实色彩有一定的偏差。采用灰色世界算法(Lam, 2005)消除光照对色彩渲染的影响。灰色世界算法基于灰色世界假设,该假设认为,对于呈现大量颜色变化的图像,R、G和B分量的平均值趋于相同的灰色值。在物理上,灰色世界算法假设自然物的平均反射光通常是一个固定的值,这个值近似于灰色。将色彩平衡算法应用于训练集中的图像,消除环境光对图像的影响,得到原始图像。
2.2.2、数据增强:图像亮度
训练集中图像的亮度处理如下:从lmin到lmax中随机选取三个值,用来调整原始图像的亮度,并将这三个新的结果加入到训练集中。如果图像亮度过高或过低,在人工标注时很难绘制边界框,因为目标边缘不清晰。在训练过程中,这些训练集图像会对检测模型的性能产生不利影响。为了避免生成这样的图像,根据人工标注时目标边缘是否能够准确识别,选择合适的图像亮度变换范围,即, lmin =0.6, lmax =1.4。该方法可以模拟不同光照强度下的果园环境。这些值弥补了神经网络对图像采集时间集中所造成的各种光照强度的不鲁棒性的不足。
2.2.3、数据增强:图像旋转
为了进一步扩展图像数据集,将原始图像旋转90、180和270并进行镜像。旋转后的图像也可以提高神经网络的检测性能。
2.2.4、数据扩充:图像定义
由于相机的观看距离长、对焦不正确或相机移动,所获得的图像可能不清晰。模糊图像也会影响神经网络的检测结果。因此,本文对色彩、亮度、旋转增强后的图像进行随机模糊处理,模拟模糊图像。利用模糊图像作为样本,可以进一步增强检测模型的鲁棒性。
2.3、图像注释和数据集生成
为了更好地比较不同算法的性能,将训练集中的图像转换为PASCAL VOC格式。将训练集图像的长度调整为500像素,并相应调整宽度,以保持训练集的原始长宽比。对图像编号后进行人工标注。绘制边界框并手动对类别进行分类。为防止神经网络过拟合,未对像素区域不足或不清晰的阳性样本进行标记。在遮挡情况下,如果遮挡面积大于85%,图像边缘的目标面积小于15%,则不进行标记。完成的数据集如表1所示。
| 项目 | Value |
|---|---|
| 电脑 | $1600 |
| 手机 | $12 |
| 导管 | $1 |
Table 1
通过数据增强方法生成的图像数量
| 项目 | Original data | Color | Brightness | Rotation | Definition | Total |
|---|---|---|---|---|---|---|
| Number of young apple images | 160 | 160 | 480 | 640 | 160 | 1600 |
| Number of expanding apple images | 160 | 160 | 480 | 640 | 160 | 1600 |
| Number of ripe apple images | 160 | 160 | 480 | 640 | 160 |
3、方法
3.1、YOLO-V3
YOLO- v3 (Redmon和Farhadi, 2018)网络是由YOLO (Redmon和Farhadi, 2016)和YOLO- v2 (Redmon和Farhadi, 2017)网络演变而来的。与更快的R-CNN网络相比,YOLO网络将检测问题转化为回归问题。它不需要一个建议区域,直接通过回归生成边界框坐标和每个类的概率。这大大提高了检测速度相比更快的R-CNN。
YOLO检测模型如图2所示。网络将训练集中的每个图像分割成S*S (S = 7)个网格。如果目标地面真相的中心落在网格中,那么网格负责检测目标。每个网格预测B个边界框和它们的置信度加分数,以及C类条件概率。置信度的定义如下:
Confidence = pr (Object) × IoU{truth,pred} , pr (Object) ∈ {0, 1} (1)
当目标在网格中,则pr (Object)=1,否则为0。使用IoU{truth,pred}表示参考和预测边界框之间的重合。置信度反映了网格是否包含对象,以及预测边界框在包含对象时的准确性。当多个边界框检测到同一个目标时,YOLO使用非最大抑制(non-maximum suppression, NMS)方法来选择最佳边界框。

虽然YOLO提供了比RCNN更快的速度,但是它有很大的检测误差。为了解决这个问题,YOLO-V2引入了快速R-CNN中锚框的思想,并使用k-means聚类方法生成合适的先验边界框。因此,在联合(IoU)结果上实现相同交集所需的锚盒数量减少了。YOLO- v2改进了网络结构,使用卷积层代替YOLO输出层中的全连接层。YOLO- v2还引入了批量归一化、高分辨率分类器、维聚类、直接定位预测、细粒度特征、多尺度训练等方法,大大提高了与YOLO相比的检测精度。
YOLO-V3是YOLO-V2的改进版本。它采用多尺度预测来检测最终目标,其网络结构比YOLO-V2更复杂。YOLO-V3可以预测不同尺度上的边界盒,多尺度预测使得YOLO-V3比YOLO-V2更有效地检测小目标。
3.2、密集连接神经网络
在神经网络训练过程中,由于卷积和下采样的原因,使特征图减少,在传输过程中丢失了特征信息。DenseNet的提出是为了更有效地利用特征信息(Huang et al., 2017).它在前馈模式下将每一层与其他层连接起来,因此l层接收前一层的所有特征映射x0,x1,…,xl-1作为输入。
xl= Hl [x0, x1,… ,xl1] (2)
其中[x0, x1,…,xl1]是x0 ,x1, …,xl-1层的特征映射的拼接,Hl是用来处理拼接的特征映射的函数。这使得DenseNet能够减缓梯度消失,增强特征传播,促进特征重用,并大大减少参数的数量。
3.3、使用的算法
图3展示了如何使用yoloo - v3的Darknet-53架构作为基本的网络架构,使用DenseNet代替低分辨率的原始传输层来增强特征传播,促进特征重用和融合。

yolov3 - density的具体网络参数如图4所示。为了更好的处理高分辨率的图像,首先将输入图像调整为512×512像素,将原始图像调整为256×256像素。然后将改进网络中的32×32和16×16降采样层替换为DenseNet结构。在本文中,传递函数Hl使用函数BN-ReLU-Conv(1×1)-BN-ReLU-Conv(3×3),它是批量归一化(BN)、整流线性单元(ReLU)和卷积(Conv)的组合。BN-ReLU-Conv(3 * 3),它是批量归一化(BN)、整流线性单元(ReLU)和卷积(Conv)的组合。Hl提供了x0, x1, xl 1层的非线性变换。xi由64个特征层组成,每个特征层具有32 * 32的分辨率。H1对x0进行BN-ReLU-Conv(1* 1)非线性运算,然后对结果进行BN-ReLU-Conv(3 * 3)运算。H2对[x0, x1]形成的feature map进行相同的操作。 将结果x2和[x0, x1]拼接到[x0, x1, x2]中,作为H3的输入。结果x3和[x0, x1, x2]被剪接成intox [x0, x1, x2,x3]作为H4的输入。最终,特征层[x0, x1, x2, x3, x4]继续向前传播。在16×16分辨率的层中,同样进行特征传播和特征层拼接。最后,将特征层拼接成16×16×1024,向前传播。
在训练过程中,当图像的特征被传输到低分辨率层时,后一层特征将接收到DenseNet中它前面所有特征层的特征,从而减少了特征的丢失。这样,在低分辨率的卷积层之间可以重用特征;提高了特征使用率,提高了特征的使用效果。
最后,本文提出的yolov3 - density模型可以预测64×64、32×32和16×16三种不同尺度的边界盒。它还可以对目标类别进行分类,以提供apple检测。
4.、实验和讨论
使用Darknet框架对本研究中使用的yolov3致密检测模型进行了修正(Redmon和Farhadi, 2018)。检测模型在NVIDIA Tesla V100服务器上进行了训练和测试。网络初始化参数如表2所示。
| Size of input | images | Batch Momentum Initial | learning rate | Decay Training | steps |
|---|---|---|---|---|---|
| 512× 512 | 8 | 0.9 | 0.001 | 0.0005 | 70,000 |
为了提高模型的检测精度,适应Darknet框架所需的输入,将输入图像调整为512×512像素。考虑到服务器的内存限制,本文将批处理大小设置为8。使用了70 000个训练步骤,以便更好地分析训练过程。动量、初始学习率、权值衰减正则化等参数是指YOLO-V3模型中的原始参数。确定训练参数后,对模型进行训练。学习速度在4万步后下降到0.0001,在5万步后下降到0.00001。
本文针对训练后的yolov3稠密模型,利用测试图像进行了一系列实验,验证了算法的性能。使用分辨率为3000×3000的图像进行测试。评价神经网络模型有效性的相关指标如下:
A.精确度、召回率和F1分数
对于二分类问题,根据学习者的真类和预测类的组合,样本可分为四类:真阳性(TP)、假阳性(FP)、真阴性(TN)和假阴性(FN)。分类结果的混淆矩阵如表3所示。
| Labeled | Predicted | Confusion matrix |
|---|---|---|
| Positive | Positive | TP |
| Positive | Negative | FN |
| Negative | Positive | FP |
| Negative | Negative | TN |
P和召回率R定义如下:
P=TP/(TP+FP)
R=TP/(TP+FN)
将查全率作为纵轴,查全率作为横轴,可以得到查全率-查全率曲线,简称P-R曲线。F1分数也被用来评估模型的性能。F1成绩的定义如下:
F1=2PR/(P+R)
b .损失函数损失函数是评价模型性能的一个标准。YOLO中的损失函数定义如下: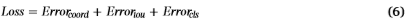
坐标预测误差Error(coord)定义如下:
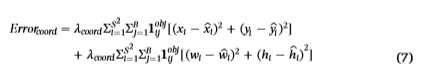
λcoord坐标误差的重量,S2是输入图像的网格数量,和B是每个网格生成的边界框的数量。指原始YOLOV3模型中的参数,λcoord = 5, S = 7, B = 9被选在这个研究。1{obj,ij} =1表示该对象落入网格i的第j个边界框,否则1{obj,ij} = 0。(xi, yi, wi, hi)是预测边界框的中心坐标、高度和宽度的值。(xi, yi, wi, hi)是真值。
IoU错误Erroriou定义如下:
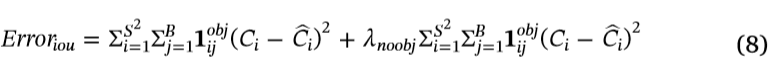
在参数λnoobj借据的重量误差。指原YOLO-V3模型的参数,选择λnoobj = 0.5。Ci 是 预测 confidence, Ci 才是 真正的confidence分类错误Errorcls定义如下:
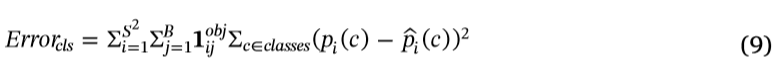
其中c表示被检测到的目标所属的类。π©是指真正的概率网格中的对象所属的类c i .π̂©的预测价值。网格i的Errorcls是网格中所有对象的分类错误的总和。
c .IOU
IoU是定义目标目标检测精度的标准。IoU通过计算预测边界盒与真实边界盒的重叠率来评估模型的性能,具体如下:

其中Soverlap为预测边界框与真实边界框的交点面积。Sunion是两个边界框的并集的面积。
检测时间
本文比较了几种深度学习模型的平均检测时间,并分析了这些模型的实时性。
4.1、数据类别的影响
为了比较数据类别对检测结果的影响,我们使用yolov3稠密神经网络分别训练了幼苹果、膨胀苹果和成熟苹果的图像。这三个时期的苹果图像也被结合起来,用来训练模型。模型训练后的PR曲线如图5所示。对应模型的F1得分如表4所示。


为了更好地观察边界框,分别使用1、2和3来标记年轻的、扩展的和成熟的苹果。模型计算结果如图6所示。

从以上检测结果可以看出,使用apple图像训练的模型在一个生长期的F1分数要高于组合图像训练的模型。在一个生长阶段使用苹果图像训练的模型可以更好地检测一些严重遮挡和重叠的苹果。这说明输入类的数量会影响模型的检测能力。由于幼苹果果实体积较小,彼此交叠较密,所以对幼苹果的检测结果不如膨大苹果和成熟苹果。该模型由于颜色特征更明显、个体体积更大、重叠更少,因此对成熟苹果的检测性能最好。
4.2、不同算法的比较
为了验证本文提出的模型的性能,图像的苹果三个增长阶段作为训练集,该模型与YOLO-V2相比,YOLOV3,和更快的R-CNN VGG16净,这是先进的水果检测模型来说明我们提出YOLOV-3密度模型的优越性。
yolov - v2、yolov - v3、yolov3在训练过程中的损失如图7所示。

试验过程中各模型的P-R曲线如图8所示。
模型F1得分、IoU、平均检测时间如表5所示。

不同生长阶段模型的检测结果如图9和表6所示。


从以上结果可以看出,YOLO-V3在训练过程中比YOLO-V2收敛速度更快,收敛效果更好。YOLO-V2的最终损失约为3.95,而YOLO-V3的最终损失约为1.53。yolov3模型的损失约为0.54,比原yolov3模型的损失约低0.99。这表明,该模型的性能得到了显著提高。YOLO-V3的损失曲线在3000步训练后开始饱和。但是,yolov3的损失继续收敛到45000步,之后不再下降。在检测性能方面,所提出的YOLO-V3稠密模型优于速度更快的R-CNN VGG16 net、YOLO-V3、YOLO-V2模型。yolov3 - density的F1得分为0.817,高于其他三种模型。这说明yolov3 -浓密模型的综合召回性能和召回精度优于其他三种模型。yolov3 -浓密的IoU值为0.896,高于其他三种模型。结果表明,yolov3 - density算法检测边界盒的精度高于其他三种模型。使用VGG16 net时,yolov3稠密体的平均检测时间比R-CNN快2.116s,与yolov3模型基本相同。它可以在高分辨率的图像中实时检测苹果。在检测过程中,yolov3 - density模型的准确率和置信度明显高于其他三种模型,体现了yolov3 - density检测模型的优越性。
4.3、实验数据量的影响
在本节中,我们将分析图像数据集的大小对yolov3稠密模型的影响。从三个生长阶段各随机选取10、50、200、400、800、1200、1600张苹果图像,形成30、150、600、1200、2400、3600、4800张图像的训练集。不同规模训练集对应模型的P-R曲线和F1得分如图10和表7所示。

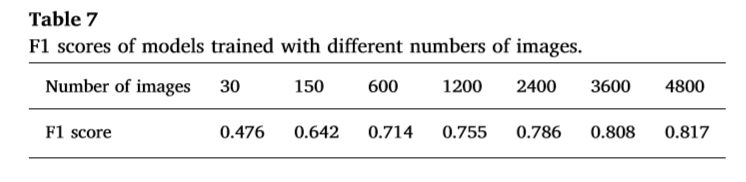
从这些实验中,我们可以得出结论,yolov3稠密模型的性能随着训练集的增大而提高。如果训练集包含的图像少于1500张,那么随着训练集的增长,性能会迅速提高。当训练集的大小超过1500时,随着图像量的增加,增强速度逐渐降低。当图像量超过3000时,训练集的大小对模型的性能没有进一步的显著影响。
4.4、数据扩充方法的影响
使用颜色、亮度、旋转变换和模糊处理来增强图像。为了验证四种变换方法对训练模型的影响,我们利用控制变量法每次去除一种数据扩充方法,得到IoU值和F1分数。多角度的影响在图像采集过程中,还考虑了视景方法对检测性能的影响。数据增加后,多角度观看法获得的图像数量增加到880张。结果如表8所示。

从实验结果可以看出,多角度图像的采集对于模拟多角度图像的检测有很大的帮助。去掉这种方法后,检测模型的F1分数降低了0.033,IoU降低了0.058,表明模型的性能明显下降。因此,多角度图像观看方法有利于提高模型的性能。
色彩平衡变换对提高检测有很大的帮助。去掉色彩平衡变换会降低检测精度。
亮度变换有利于模型适应全天的光照情况。去除亮度变换后的模型检测结果比完整数据集的模型检测结果差。
旋转变换对训练模型的影响有限,去除旋转变换后的训练模型的性能略低于完整数据集。
模糊处理有利于提高模型的鲁棒性。与未经模糊处理的数据集相比,经过完整数据集训练的模型具有更高的检测精度。
4.5、在咬合和重叠条件下的苹果检测
在果园中,树枝和叶子的部分堵塞以及苹果之间的重叠是常见的。这将对苹果的检测产生一定的影响。在本节中,我们分析了封闭和重叠的yolov3稠密模型的IoU值和F1分数。结果如表9和图11所示。


从以上实验可以看出,遮挡和重叠的苹果会导致检测不准确。然而,该模型可以用来检测大部分遮挡和重叠的苹果,这说明了本文提出的模型的实际意义。
4.6在没有苹果的环境中进行检测
在真实环境中,相机也可以捕捉不包含苹果的图像。本文收集了50幅不包含苹果的图像,在真实场景中测试了检测模型的性能。其中,10幅图像只包含天空,10幅图像只包含地面,10幅图像只包含没有苹果的树,20幅图像包含这三种可能的背景。使用yolov3 - density模型对这50幅图像进行了测试。检测结果显示,在这50幅图像中没有检测到苹果。
从实验结果可以看出,yolov3 - density detection model可以很好的识别出背景。实际上,在培训期间,在手动标注期间没有被框起来的区域将被默认标记为背景。因此,在训练过程中,实际输入包括4类,包括背景和三个生长阶段的苹果。实验结果进一步证明,YOLOV3稠密检测模型能够提供较高的分类精度。
5. 结论
本研究将DenseNet方法应用于果园主要生长期苹果的检测,对现有的yolo3检测模型进行了改进。这个模型可以用来检测年轻的苹果、膨胀的苹果和成熟的苹果。本文提出的yolov3模型使用DenseNet对yolov3模型中分辨率较低的特征层进行优化,增强特征传播,促进特征重用,提高网络性能。实验结果表明,与YOLOV3模型相比,本文提出的YOLOV3稠密模型具有更好的性能,并优于目前最先进的水果检测模型——基于VGG16 net的快速R-CNN模型。yolov3密度模型还可以实时检测被遮挡和重叠的苹果。
未来的工作将集中于应用现有的模型来检测视频中的苹果,产量估计和其他实际任务。本文将分析未涉及的苹果在不同生长阶段的环境特性和特性。此外,还将对数据扩充方法和检测模型进行优化,进一步提高检测精度。















 1246
1246











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











