







Unsupervised Depth Estimation from Light Field Using a Convolutional Neural Network
内容理解:
无监督深度估计,以100个视差等级,将子孔径图像warp到中心视图,计算均值和标准差,作为特征。我们知道有监督深度估计的方法中是提取特征生成代价体,这里没有使用卷积特征提取的方法。100个视差等级,200个特征通道,代价体维度相当于100×h×w×200。损失函数由两部分组成,一部分计算warp后的子孔径图像和中心视角之间的差异,另一部分计算warp后子孔径图像之间的差异。因为如果warp正确的话,两部分差异都应该最小。最后,在真实世界上验证的时候,由于缺乏gt计算损失,又提出了一种基于超分辨计算损失的方法,使用计算的视差进行超分辨,然后计算超分辨结果的损失。
摘要
基于CNN的无监督方法用于深度估计。在没有gt监督的情况下学习4D光场到视差图端到端的映射。
设计combined loss function。compliance and divergence约束。
增加深度特征提取参考view的数量,补充warping带来的损失信息。
这篇论文涉及到很多Learning-Based View Synthesis for Light Field Cameras中的内容
这项工作的主要贡献可以概括为四个方面:
1) 一种基于无监督CNN的光场显式深度估计方法,适用于通常缺乏精确真实深度的实际情况。
2) 精心设计的组合损失函数,保证网络生成准确可靠的视差图。
3) 在合成光场数据集和真实光场数据集上都优于最先进的方法。
4) 基于深度估计的光场超分辨率改进结果。
The Proposed Method
3.1 Network Architecture
我们提出的用于光场深度估计的无监督网络的流程图如图1所示。该网络首先在没有真实深度标签的光场数据集上训练,然后可以根据同一相机模型捕获的给定光场的中心视图来估计视差图。请注意,我们的网络可以生成任何视图的深度,其步骤与这里的中心视图相同.
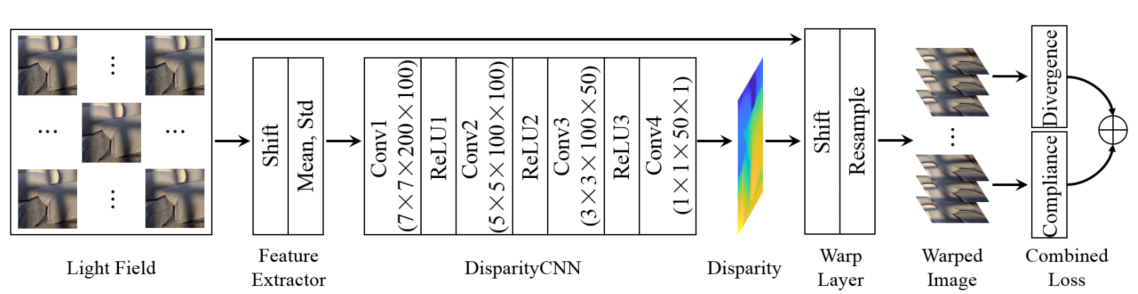
图1.我们提出的无监督网络的流程图。首先利用特征提取器从输入光场中提取深度特征,然后导入DisparityCNN进行深度估计。warp层用估计视差将子孔径图像warp到的光场中心视图。综合损失结合了从warp图像计算出的compliance and divergence,使我们的网络能够在没有gt深度标签的情况下进行训练。
给定一个用于深度估计的4D光场,第一个步骤是通过使用一组预定义的视差水平d1,····,dN将其他子孔径图像移动到中心视图来计算中心视图的深度特征,如公式1所示,
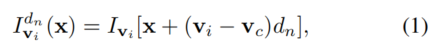

公式(1)表示的是warp后的图像可以由warp之前的图像得到,等式左边是warp后的图像。warp操作根据的视差是给定的一组视差水平,论文里作者选择的是100个视差level。
我们首先计算每个视差水平上warp的子孔径图像之间的平均值和标准差
同一视差level所有的view

我们使用上述深度特征作为我们网络的输入,而不是整个光场,因为stacked子孔径图像直接估计视差需要大的感受野,因此这样更深的网络结构需要更多的训练数据,这受到当前可用光场数据集的限制。实际上,warp子孔径图像的平均值和标准差可以为后续网络的深度估计提供足够的信息。
根据[29]中的照片一致性约束,如果视差是正确的,则所有转换后的图像在每个像素处具有相同的颜色,这表示M(x)平均值与目标中心视图Ivc(x)之间的最低V(x)标准差和最高相似度。遵循此约束,利用优化策略降低初始视差图中的噪声,得到最终的视差图。与文献[29]不同的是,我们通过处理CNN中的深度特征来计算视差图。基于学习的策略可以更好地利用4D光场中的相关性。另外一个优点是,我们的网络可以产生连续的视差值,比[29]中优化的离散视差值更精确。
图1中的第二部分命名为DisparityCNN,它基于在前一层中提取的深度特征来计算视差图。DisparityCNN由四个卷积层组成,它们的核大小不断减小。除最后一层外,所有层均有修正线性单元(ReLU)。卷积后,从2N通道深度特征中 回归出单通道视差图。观察到,更多的视差水平产生更精确的视差图,但也需要更高的计算复杂度。在我们的实验中,我们通常将视差级别的数量设置为N=100,以在精确度和复杂性之间进行权衡,因此DisparityCNN中第一层的通道大小为200。一旦视差图被生成,它就被用来将子孔径图像warp到warp层中的中心视图

3.2 Combined Loss
为了实现无监督学习,损失函数不能用真实深度导出,我们根据[29]中的照片一致性约束设计了一个组合损失。这种新的损失函数包含两个项:compliance和divergence,利用4D光场中的空间和角度相关性来约束网络。
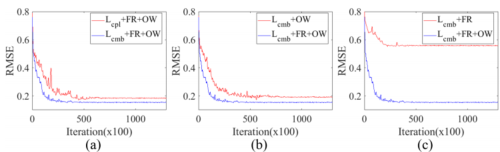
图2.(a)不同损失函数训练网络的比较(b) 不同参考视图数目训练网络的比较(c) 有无优化warping训练网络的比较。
compliance表征了warped子孔径图像的平均值与中心视图之间的差异,其可导出为
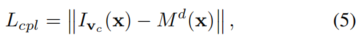
其中d是训练期间的视差图。compliance规定,如果子孔径图像以正确的视差warp,则子孔径图像应尽可能与中心视图相似。
divergence表征了warped子孔径图像之间的方差,其可导出为
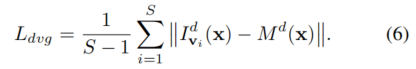
divergence规定,如果子孔径图像以正确的视差warp,则子孔径图像应尽可能相似。
综合损失定义为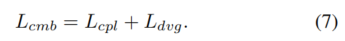
我们将不同视点的view warp到同一位置,中心位置。因为这个位置的view是确定的,所以我们可以根据和中心位置实际图像的相似程度判断我们warp的正确程度,即视差的正确性。另外,不同视点的view warp到同一位置,他们得到的图像也应该相同,根据这点也可以判断我们得到视差图的正确性,即divergence。
我们通过实验验证了组合损失(combined loss)的有效性。训练和测试阶段的设置详见第4节。这里我们先报告一些中间结果。这两项损失都不能单独用于优化我们的网络性能。从图2(a)中的收敛曲线和表1中的定量结果可以看出,如果只使用Lcpl,网络的性能低于使用Lcmb的网络。前者表明,在训练过程中,用Lcmb训练的均方根误差(RMSE)曲线比用Lcpl训练的曲线平坦。后者表明,使用Lcmb训练的网络性能比使用Lcpl训练的网络平均提高了20%左右。从而验证了divergence项的必要性。另一方面,如果只使用Ldvg,损失将被最小化到一个非常小的值,即warped的子孔径图像都是黑色的,相应的视差图往往是难以置信的大。如果没有compliance项的限制,网络不会收敛到一个有意义的值。
3.3 Full Referenced Views
我们还研究了用于深度特征提取的参考视图数量对网络性能的影响。在视图合成工作[12]中,由于任务是在稀疏采样光场中合成新视图,因此参考视图的数量仅限于四个校正者。虽然视差可以用这种方法进行隐式估计,但是受限的参考视图可能会影响深度估计的性能。使用更多的参考视图可以得到更可靠的深度特征,有利于深度估计。为此,我们在两种设置下训练我们的网络,一种是从输入光场的所有子孔径图像中提取深度特征,另一种是从四个角视图中提取深度特征。收敛曲线如图2(b)所示,定量结果如表1所示。这验证了在深度特征提取中增加参考视图的数量有利于深度估计。在数值上,与使用稀疏参考视图相比,使用全部的参考视图可以为我们的网络带来近25%的改进。
3.4 Optimized Warping
对于光场图像处理,warp是指从偏移的子孔径图像中重新采样以生成新的子孔径图像的过程。由于子孔径图像在重采样前使用视差图进行偏移,因此warped图像的边界附近存在零值,这可能导致损失函数的计算出现问题。实验发现,这种缺失的信息将对网络的训练过程和最终性能产生显著影响。由于网络实际上是用分解的图像块而不是整个图像来训练的,因此不适当的warp对网络的影响更为严重。为了解决这个问题,我们采用了一种优化的warping策略来补充丢失的信息。具体地说,我们首先利用视差图对子孔径图像进行稍微大一点的warp,然后裁剪warped图像的边界以满足计算损失函数的要求。通过这种方式,warped图像的边界就有了来自光场图像的信息。验证结果如表1和图2(c)所示。通过使用优化的warping策略,在测试场景中的平均RMSE下降了73%左右,解决不合适warping问题的必要性和重要性。
总之, the optimized warping, full referenced views, and combined loss一起保证我们的网络收敛到一个stage,产生一个准确和健壮的视差图。
视差图可以对提取的特征做卷积操作实现。作者通过构建combined loss function,最小化损失训练网络,得到了可靠的视差图。
Light Field Super-Resolution
由于现实世界中的光场图像没有背景真实深度,因此很难给出深度估计准确的定量评估。作为代替,我们建议使用光场的估计视差进行光场超分辨,并根据超分辨率结果评估我们的方法。在光场SR的不同技术中,我们选择了简单的基于投影的方法[21,3,16],该方法需要明确的视差信息,以便将其他子孔径图像投影到目标视图,以便进行更密集的采样,以获得更高分辨率的图像。如[34]所述,对于基于投影的方法,更精确的视差对应更高的SR性能,因此使用SR结果作为定量指标来评估真实光场图像深度估计的保真度是合理的。
我们首先对原始光场图像进行3倍的下采样,然后使用Accurate、Occlusion、ViewSyn和我们的SR方法估计的视差。几个测试场景的定量结果如表4所示。结果表明,对于所有测试场景,我们的方法都优于其他方法。由于Accurate、Occlusion对光场的空间分辨率和图像亮度非常敏感,因此它们仅对低分辨率、低光场图像进行粗略的视差估计,这会影响SR的性能。相比之下,我们的方法对空间分辨率和图像亮度更为敏感。另一方面,由于ViewSyn最初是为视图合成而设计的,因此来自网络的隐式估计深度没有充分利用4D光场中的相关性,因此与我们提出的方法相比,留下了很大的改进空间。
Zero-Shot Depth Estimation From Light Field Using A Convolutional Neural Network
论文理解:
与上一篇文章相比,主要有两点改进,一个是不再使用手工提取的特征,使用cnn提取特征,发现两者差距甚小。另一个是将无监督与零次学习进行了比较。
事实上,我们的网络可以在无监督或零炮学习方式。在前一种情况[上面一种]中,网络在大量没有背景真值深度标签的光场图像上进行训练,并在训练集中不包含的其他光场图像上进行测试。在后一种情况下,仅在输入光场本身上优化网络。具体来说,它首先通过FeatureCNN提取特征,然后通过DisparityCNN计算粗略的视差。扭曲层利用产生的视差将子孔径图像扭曲到中心视图,并导出组合损失以更新FeatureCNN和DisparityCNN中的参数。
我们在之前的工作[31]中通过使用CNN提取的特征替换中手工制作的特征来改进网络体系结构,这有助于以端到端的方式对网络工作进行培训。我们还研究了不同网络结构和不同视差水平对深度估计性能的影响。
什么是 zero shot https://zhuanlan.zhihu.com/p/34656727
利用训练集数据训练模型,使得模型能够对测试集的对象进行分类,但是训练集类别和测试集类别之间没有交集;期间需要借助类别的描述,来建立训练集和测试集之间的联系,从而使得模型有效。
我们提出了第一种基于zero-shot学习的光场深度估计方法,该方法不需要任何额外的训练数据。与现有的基于学习的方法(包括我们之前的工作[31])相比,该特性带来了一个显著的优势,即所提出的方法可以很好地推广到由任意相机模型捕获的各种光场图像,同时避免了严重的domain shift效应。因此,零拍学习极大地提高了光场深度估计的鲁棒性。
domain shift : 不同数据集上数据分布不一致的问题,在一个数据集的上表现很好的模型,在另一个数据集上可能表现的很差,也就是说使用合成数据集训练出来的结果在真实世界的表现可能不是很好。
我们之前的工作设计了一种无监督CNN,该CNN专门用于深度估计,具有显著的改进性能[31]。由于无监督网络可以在不需要地面真实深度作为标签的情况下进行训练,因此与有监督学习相比,无监督网络在处理真实场景时更加可行。然而,仍然需要额外的训练数据集,这使得无监督学习受到潜在的领域转移效应的影响。
网络结构



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









