







 本文介绍了光场图像的深度估计方法,利用光场几何特性设计了一种端到端的神经网络。通过多流网络结构,结合数据增强技术如视点移位和旋转,提高了深度估计的精度。实验结果表明,提出的EPINET模型在4D光场基准测试中表现出色,同时处理速度较快。
本文介绍了光场图像的深度估计方法,利用光场几何特性设计了一种端到端的神经网络。通过多流网络结构,结合数据增强技术如视点移位和旋转,提高了深度估计的精度。实验结果表明,提出的EPINET模型在4D光场基准测试中表现出色,同时处理速度较快。
光场深度估计比较基础的方法,需要注意的是这里的连接构成的就是代价体,只是没有经过shift。
3.算法
3.1. Epipoloar Geometry of Light Field Images 光场图像的对极几何
借鉴了前人的工作,我们设计了一个端到端的神经网络结构利用了光场几何特点来预测光场图像深度。因为光场图像有很多角度垂直和水平方向的像素,数据比立体相机多多了。当使用光场图像所有的viewpoint作为输入,尽管光场深度的结果精确,计算速度却比立体深度估计算法慢了几百倍。为了解决这一问题,一些论文提出只使用水平方向或十字方向的view算法。相似的,我们提出了深度估计管道,首先,利用视点角度之间的光场特性减少用于计算的图像数量。
4D光场图像表示为L(x,y,u,v),(x,y)是空间分辨率,(u,v)是角分辨率。中心和其他视点的光场图像关系可以表示如下:
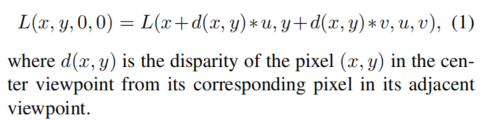
这里的x,y表示的是成像平面,u,v表示的应该是透镜阵列平面,x,y,u,v都必须是整数。
d(x,y)是与中心view相邻的view中像素(x,y)相对于中心视点对应像素的视差。
注意,d(x,y)表示的相邻view的视差,一开始没有注意到这个点,因为view与view之间的视差存在关系,所以大部分时候我们都是只给出一个相邻view的视差,横向的视差与纵向的视差之间也存在关系。
比如中心视角uv坐标为(0,0)的话,(2,0)处的view的视差就是(1,0)处的两倍,(1,1)处的横向视差与纵向视差是相等的。
对于一个角度θ (tan θ = v/u),我们可以重定义关系如下:
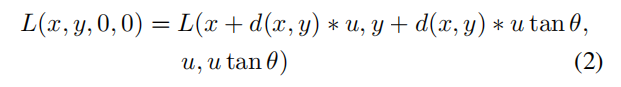
然而,视点的标号是一个整数,所以当tanθ是非整数的时候没有对应的视点。因此,我们选择选择四个方向的图像,视角θ分别是0、45、90、135假设光场图像有(2N+1)x(2N+1)的角分辨率。
3.2网络设计
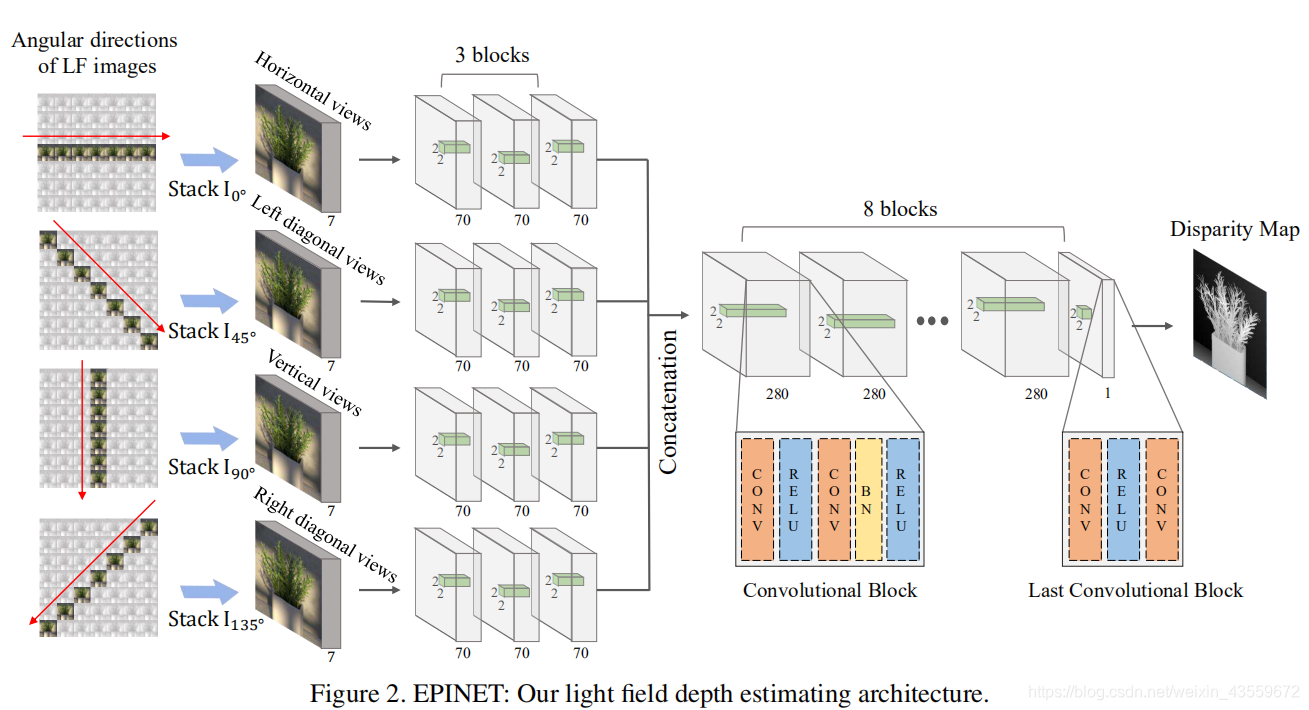
Multi-stream 网络
如图2所示,我们构建了一个multi-stream网络,为了四个有相应baseline的视点:水平,垂直和两条对角线。与传统的光流估计和立体匹配算法相似,我们在网络的开始为每一组图像分别编码。为了展示mutil-stream结构的有效性,我们定量比较了mulit-stream和single stream网络。如图3所示,即使使用同one-stream网络数量相同的参数,使用提出的方法的重构误差也低了近10%。使用这个结构,网络被限制首先生成这四个视点的有意义表示。
multi-stream部分包含三个全卷积块。因为全卷积网络以像素密集预测的有效结构而出名,我们用一系列全卷积层设计了一个基本块:‘conv-relu-conv-bn-relu’以在局部区域测量每个像素的视差。为了处理光场图像狭窄的基线,我们使用了2x2的小卷积核和大小为1的步幅来测量小的视差值(±4像素,数据集给出)。
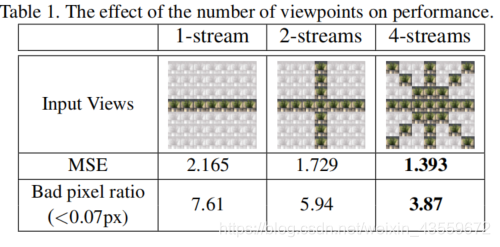
为了展示不同数量stream的效果,我们对我们的网络使用一些不同的数量的stream进行比较。使用相同的结构和几乎相同的参数数量(5.1M),我们在表1中比较了使用不同数量stream时我们网络的表现。就bad pixel ratio 和mean square error而言,四个stream的网络表现出了最好的效果。
在multi-stream之后,我们连接来自每个stream的所有特征,特征的size变成了四倍大。融合网络包含八个卷积块,卷积块寻找经过multi-stream网络的特征之间的联系。除了最后一个块,融合网络的块和multi-stream网络有同样的卷积结构。为了推断出次像素精度的视差值,我们构建最后的块是‘conv-relu-conv’。
3.3 数据增广
尽管有一些公开的数据集,其中只有很少有着和真实光场图像相似的数据。在这片论文中,我们使用了16个光场合成图像,包含不同的纹理,材料,物体,并且基线都很短。然而,16张光场图像不够训练卷积神经网络。为了防止过拟合,数据增广十分重要。因此,我们提出了一种光场图像特有的数据扩充技术,保留了子孔径图像间的几何关系。
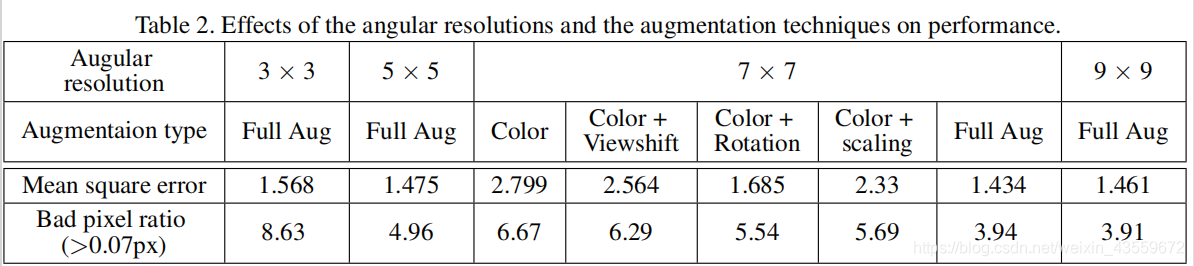
我们第一种策略是光场图像的中心view。我们使用的合成的光场数据集有9x9个view,每一个有512x512的分辨率。如图4所示,我们选择了7x7个view和中心view视差图来训练我们的网络。通过转换中心view,我们可以得到9倍的训练数据。为了验证不同视图数量和view-shifting的表现,我们比较了网络在使用 3×3, 5×5, 7×7,和9×9输入view时的表现,如表2所示,我们发现当增加输入view的数量时,表现会更好,但是使用9x9和7x7的不同是微不足道的。7x7的view在均方误差上表现的更好。这表现了view-shifting的有效性。
我们也提出了一种旋转扩充方法。正如使用深度学习的深度估计和光流估计,图像在空间维度的旋转已经被广泛用于数据扩充。然而,传统的旋转方法不能直接使用,因为没有考虑光场图像的直接特征。在我们网络的multi-stream部分,我们提取特征为了视点集合的极线性质。为了保留这个光场性质,我们首先在空间上旋转了子孔径图像,然后从新安排了视点集合和streams之间的关系,如图5所示。重新安排是有要的因为旋转改变了集合性质。比如,在3.1部分提到的,垂直方向的像素与垂直方向的view紧密相连。如果我们将垂直视角的子孔径图像旋转90度,水平视图网络stream就会有垂直特性。因此,旋转后的子孔径图像应该被输入到垂直view stream。
我们此外还使用了整体扩充技术,比如说缩放和翻转。当图像缩放时,视差值也应该相应的缩放。我们同时调整图像和视差的尺度到原来的1/N,(N=1,2,3,4)。翻转光场图像时,视差的符号会被反转。使用这些扩充技术:view-shifting,旋转[90,180,270],缩放[0.25,1],颜色缩放[0.5,2],将颜色从[0,1]随机转换为灰度,gamma值[0.8,1,2]和翻转,我们可以将训练数据扩充到原始的288倍。
我们验证了光场图像独特扩充的有效性。如表2所示,当使用旋转和翻转时表现有很大提升。我们同样观察到缩放扩充方式允许覆盖不同的视差范围。这对实际上有狭窄基线的真实光场图像是很有用的。通过数据增广,我们减少了超过40%的视差误差。
3.4 Details of learning
我们通过从16幅合成光场图像中随机采集23×23大小的灰度块,利用了分块训练[14]。为了提高训练速度,层中的所有卷积都是在没有零填充的情况下进行的。我们排除了一些包含反射和折射区域的训练数据,如玻璃、金属和无纹理区域,这些区域会导致不正确的对应。在图6中,反射和折射区域被手动屏蔽。我们还删除了无纹理区域,这些无纹理区域是指其中一个中心像素和其他像素之间的平均绝对差值小于0.02。

损失函数,我们使用了平均绝对值 损失(MAE),对异常值具有鲁棒性。我们使用Rmsprop[32]优化器并将批大小设置为16。The learning rate started at 1e-5 and is decreased to 1e-6.Our network takes 5∼6 days to train on a NVIDIA GTX 1080TI and is implemented in TensorFlow [5].
4. 实验
使用了合成数据集4D light field benchmark和真实世界数据集。benchmark角分辨率9x9,空间分辨率512x512。
4.1 Quantitative Evaluation
为了进行定量评估,我们使用4D光场基准点中的测试集来估计分布图[14]。计算了12幅光场测试图像的坏像素比和均方误差。为了更好地评估算法在复杂场景中的性能,采用了三个阈值(0.01、0.03和0.07像素)作为坏像素比。
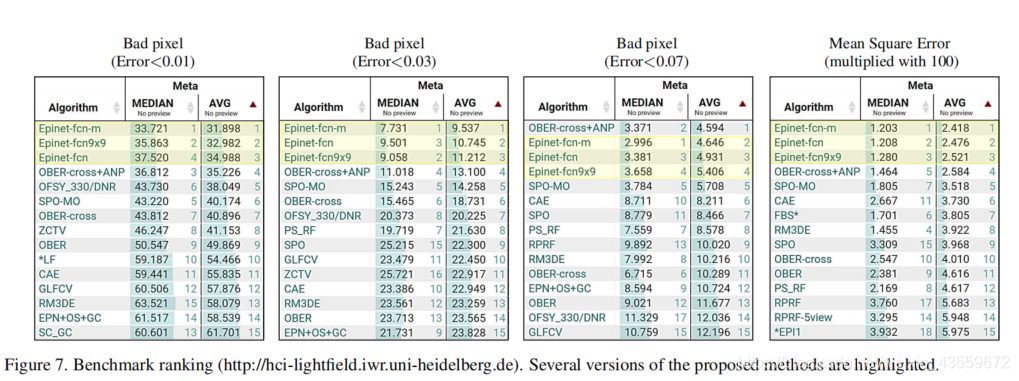
在图7中,我们直接参考了发布在基准网站上的排名表。我们的EPINET在四个指标中有三个表现最好。Epinet-fcn是我们的Epinet模型,使用垂直、水平、左对角线和右对角线的视点作为输入,Epinet-fcn9x9是一个使用所有9×9视点的模型。Epinet-fcn-m是我们Epinet-fcn的一个改进版本。Epinet-fcn-m通过翻转和旋转(90、180、270度)给定的光场来预测多个视差图。最后的估计是估计出的奇偶校验映射的平均值,从而降低了匹配模糊度。除了精度,EPINET是最先进的方法中最快的算法,如图8所示。我们的计算时间仅次于MVCMv0,但其深度精度在基准中是最后的。
定性结果(棉花、盒子和圆点)如图10所示。棉花场景包含平滑曲面,盒子场景由具有深度不连续遮挡的倾斜对象组成。从样本可以看出,我们的EPINET重建光滑的表面和锐利的深度不连续性优于以往的方法。EPINET通过网络中的回归部分推断出准确的视差值,因为我们的完全卷积层可以精确区分EPI斜率的细微差异。圆点场景受到图像噪声的影响,其噪声水平随空间变化。再次,由于2×2核具有抑制噪声影响的作用,因此该方法在这种噪声环境下取得了最佳的性能。
EPINET和其他最先进的基于深度学习的方法[12,13]之间的直接比较可以在表3和图9中找到。我们在[12,13]作者提供的250 LF图像上训练EPINET,这些图像的基线是(-25,5)像素。EPINET仍优于[12,13]中的作品。我们的多流策略可以重新解决方向匹配的模糊性,从而能够覆盖像飞机机翼和玩具头部这样的尖锐物体边界。性能更好的另一个原因是,与HCI数据集相比,[12,13]的LF图像包含高度纹理的区域,噪声较少。
4.2. Real-world results
在图11中,我们使用输入视图点7×7和9×9比较了来自EPINET的视差预测。虽然两个EPINET在合成数据中的性能相似,但在现实世界中,两者之间存在明显的性能差异。在[37]中,已经表明,从光场估计深度的精度随着更多的视点而提高,因为它们代表了所有输入视点的一致性。因此,我们使用9×9输入视点的EPINET进行实际实验。我们还使用传统的加权中值滤波器[23]仅对真实数据集消除了稀疏离散性误差。
5. Conclusion
我们的方法还有改进的余地。第一,改进基于CNN的方法的最简单方法是增加真实数据集的数量。第二,我们的网络无法推断反射和无纹理区域的准确差异。为了解决这个问题,我们认为在未来的工作中可以包括诸如物体材料[35]之类的先验知识。我们还期望我们的网络模型可以通过融合光度提示[31]或深度边界提示[34]来改进。

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









