







 本文提出了一种基于蜘蛛猴优化的SDN自适应多路径负载均衡算法(SMO-LBA),针对传统算法的不足,它实时感知网络状态,考虑链路实时传输,具有自适应性。通过Mininet仿真实验,算法提高了网络吞吐量和链路利用率。
本文提出了一种基于蜘蛛猴优化的SDN自适应多路径负载均衡算法(SMO-LBA),针对传统算法的不足,它实时感知网络状态,考虑链路实时传输,具有自适应性。通过Mininet仿真实验,算法提高了网络吞吐量和链路利用率。
名词解释
Equal Cost Multi-Path, ECMP:等价多路径
Global First Fit, GFF:全局首次匹配
Dynamic Load Balancing, DLB:动态负载均衡
Flow Scheduling Cost based Congestion Control Routing Algorithm, FSC-CCRA:基于流调度代价的拥塞控制路由算法
Spider Monkey Optimization, SMO:蜘蛛猴优化算法
Load Balancing Algorithm based on SMO, SMO-LBA:基于蜘蛛猴优化的SDN自适应多路径负载均衡算法
Application Programming Interface, API:北向应用程序接口
Link Layer Discovery Protocol, LLDP:链路层发现协议
“摘要:针对传统多路径负载均衡算法无法有效地感知网络的运行状态、不能综合考虑链路的实时传输状态以及大多数算法缺少自适应性的问题,基于SDN的集中控制和全网管控思想,提出一种基于蜘蛛猴优化的SDN自适应多路径负载均衡算法(SMO-LBA)。首先,利用数据中心网络的感知能力来获取多路径的实时链路状态信息;然后,利用蜘蛛猴算法的全局探索和局部开采能力将链路空闲率作为每条路径的适应度值,并引入自适应权重对路径进行动态评估及更新;最后,寻找数据中心网络中链路占用率最小的路径,确定其为最优转发路径。选用胖树拓扑在Mininet平台上进行仿真实验,实验结果表明SMO-LBA可提高数据中心网络的吞吐量和平均链路利用率,实现网络自适应负载均衡。”
0 引言
传统的负载均衡采用等价多路径路由算法,将数据进行哈希计算,均衡在所有等价的路径上,把流量负载平均分配在每条链路,来实现网络数据转发,但算法缺少拥塞感知机制,为考虑网络实时状态。GFF算法获取网络中所有的链路信息,选取首次满足匹配条件的路径,实现简单但不能实现全局最优;模拟退火法用概率性搜索的方法,选择了全网最优的路径转发但放弃了网络收敛性。FSC-CCRA对数据流量区分大小流,根据定义流调度代价选取路径,但自适应动态选择路径的能力不足。
1 算法设计与实现
1.1 算法实现架构
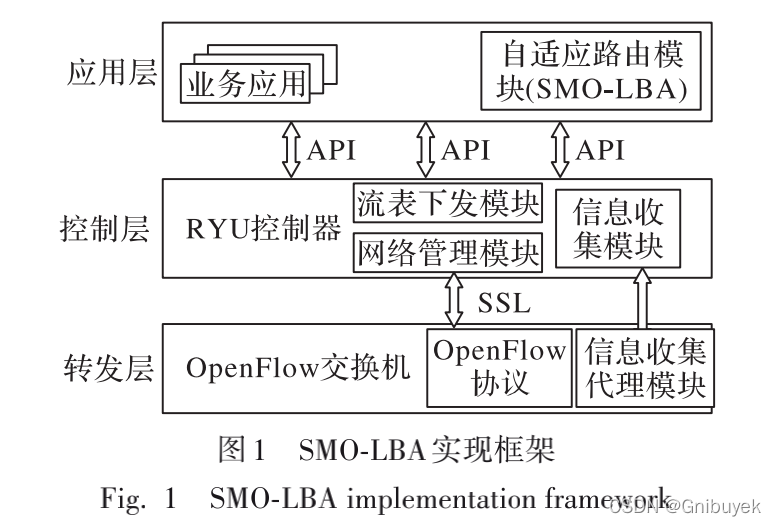
信息收集模块主要用来收集数据中心网络中的实时状态信息,探测感知网络中各节点状态信息和各路径上的链路状态信息,获取数据中心完整网络拓扑结构,建立相关路径信息监测表;通过LLDP将相关信息封装在Packet_in/Packet_out消息中,在控制器和交换机之间通信。
网络管理模块周期性监测网内各参数信息,以实现自适应动态负载均衡;通过南向OpenFlow协议获取端口统计信息,周期性获得网络流量和各转发路径负载情况,不断更新管理路径信息监测表,包括流管理、节点管理和链路管理,计算各路径负载均衡度,一旦高于设定阈值,则调用自适应路由模块,根据实时参数对路径重新评估,选择合适路径转发来降低均衡度。
自适应路由模块综合来自信息收集模块和网络管理模块的信息,基于全网路径重新选路;采用SMO-LBA对多条路径进行评估,以链路利用率作为目标函数,从局部到全局的过程进行寻优,选取适应度值最高的路径作为目的转发路径,对负载均衡度不满足条件的路径重新择路。
流表下发模块根据自适应路由模块评估最佳目的转发路径,产生对应的路由转发策略,有Ryu控制器以流表的形式下发到各个交换机节点。
1.2 算法设计思想
SMO-LBA将各个网络节点作为蜘蛛猴种群寻优的食物源,将数据流通过链路到达各个节点的过程模拟成蜘蛛猴种群在寻找最优食物所经过的路径,获取每条链路负载信息和从每个网络节点出发所有链路的链路利用率,建立网内路径转发的路径信息监测表,进行周期性的维护更新。
根据建立的路径信息监测表,获取节点以及链路的信息,得到实时链路负载均衡度 :
其中 ,
和
用来表示路径上的节点位置,
是节点表示的路径集合,
表示当前转发路径的链路负载,把该路径上各节点间最大的负载作为链路负载;
是该条路径的实际带宽,
,
为当前转发路径的链路数目,
表示每条转发路径的实时带宽情况;
是数据中心网络的所有数据流量,即所要处理的整体网络负载;
是建设时总的网络带宽,表示为
,
为总的传输链路条数,
为链路的最大传输带宽。文章假设满足触发条件的最大负载均衡阈值
为75%。
SMO-LBA机制的原理:首先初始化网络中的数据流,将其分为多个小组来尽量减少竞争的压力,以提高寻优效率和寻找最佳转发路径;对于各小组,将寻优过程分为本地领导者阶段和全局领导者阶段,从局部到全局的顺序不断反馈更新器在组内的最优结果;最后全局领导者根据反馈结果更新至最优值,若结果未达到预先设定的阈值,则将组分为更小的组,重复执行上述步骤,直到找到最优的转发路径。
构造数量为的蜘蛛猴种群,
是一个
维变量,代表种群中的第
只蜘蛛猴,即作为被优化问题的潜在解,对其进行初始化:
其中 是第
只蜘蛛猴的第
维分量;
和
是第
维上的边界;
是
上的随机数。
在本地领导者阶段,每个根据本地领导者和小组信息更新在网络中的节点位置,计算新节点位置相应的适应度值
:
其中 表示当前路径的链路利用率,值越小说明此路径的占用程度越小,更易被选择为解决负载问题需要的转发路径,计算出的适应度相应变高,在位置更新过程中,新位置的适应度值高于原位置,则更新位置。
引入基于目标函数的动态自适应惯性权重为,由
表示在每次更新中,新位置对于原位置信息继承的程度,通常取0到1之间的常数。文章将链路利用率作为目标函数引入自适应惯性权重中,即把优化问题与蜘蛛猴个体的适应度建立映射关系,当随着各负载链路情况发生变化,其所对应的适应度也相应变化。首先计算
:
其中 为更新次数;
为第
只猴子第
次更新相应位置的目标函数值;
为第
次更新的 最优蜘蛛猴相应的目标函数值。根据
得到对应的
:
此处当 时,取
,
用来衡量惯性权重
变化的平滑程度。
本地领导者阶段的位置更新公式为:
其中 和
分布表示第
组内本地领导者和第
只蜘蛛猴的第
维分量,
可以随机选取。
完成本地领导者的寻优过程后,进入到全局领导者阶段,在此阶段蜘蛛猴通过全局领导者和本地小组信息更新在全局层面的位置。全局领导者阶段的位置更新公式为:
其中 为全局领导者的第
维分量,且
随机选择。
在全局领导者阶段,蜘蛛猴种群对于全局的搜索能力变差,需要增大它对于全局的开发能力,通过适应度值再得到一个概率计算公式,用来获得更大的开发几率:
通过本地领导者阶段和全局领导者阶段的位置更新过程,最终获取在分组情况下全网中最优转发路径,对超过负载阈值的数据流选择最佳转发路径,通过控制器下发流表的形式,形成新的流表转发策略,由流表下发模块匹配转发。
2 仿真与性能评估
仿真实验设置:Mininet 2.3.0、Ryu开源控制器、K=4胖树拓扑、蜘蛛猴种群规模N=50
2.2 对比分析
使用Iperf流量工具模拟,设置链路带宽为100Mb/s,控制器监控周期为5s,逐步增大负载。
性能指标:节点过载次数、传输时延、平均链路利用率
算法对比:SMO-LBA、FSC-CCRA、ECMP
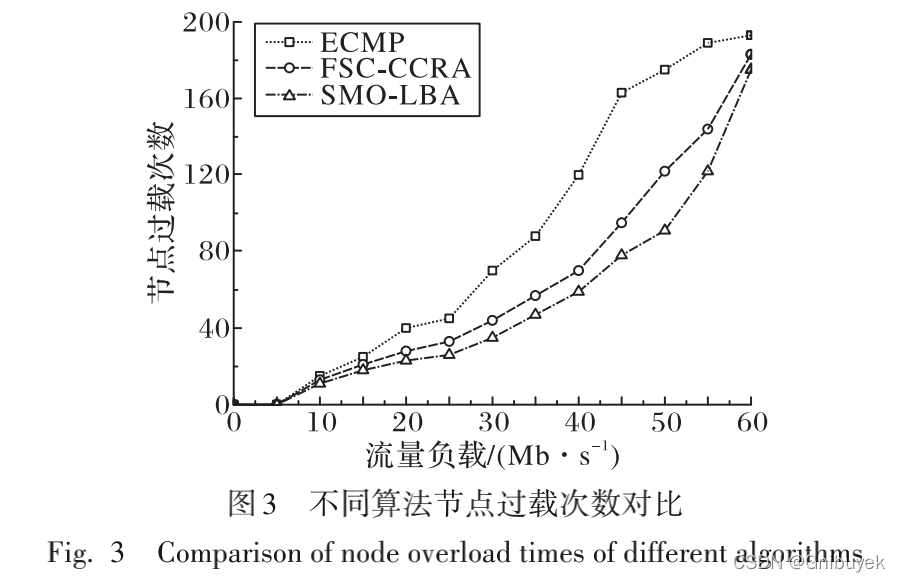
(1)节点过载次数
SMO-LBA实现的效果最优,针对负载过大的路径自适应重新选路,动态调整转发路径,避免节点过载情况发生,但当系统流量达到饱和时,网络处理负载的能力受到限制,最终各算法节点过载次数趋近相同。
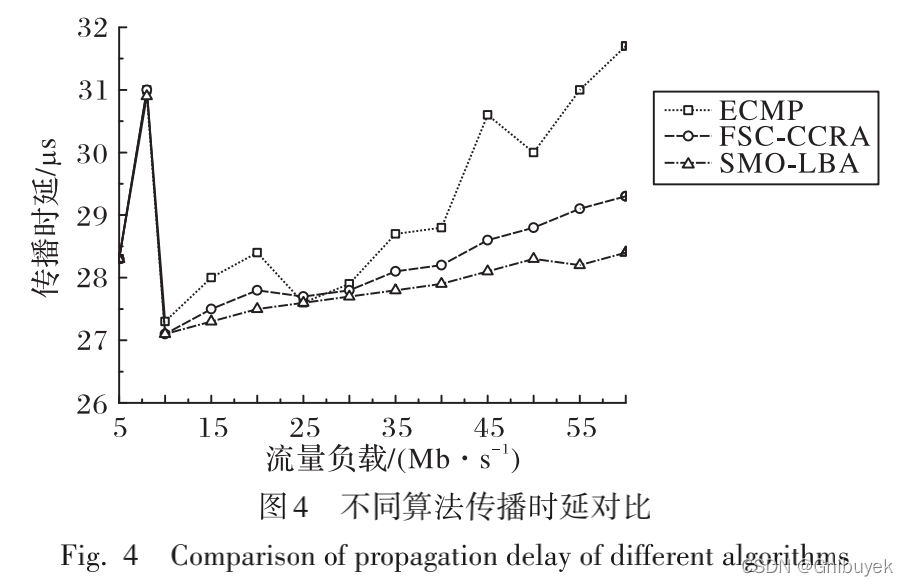
(2)传播时延
SMO-LBA传播时延虽然也有抖动现象,但基本平稳且传播时延低于FSC-CCRA。
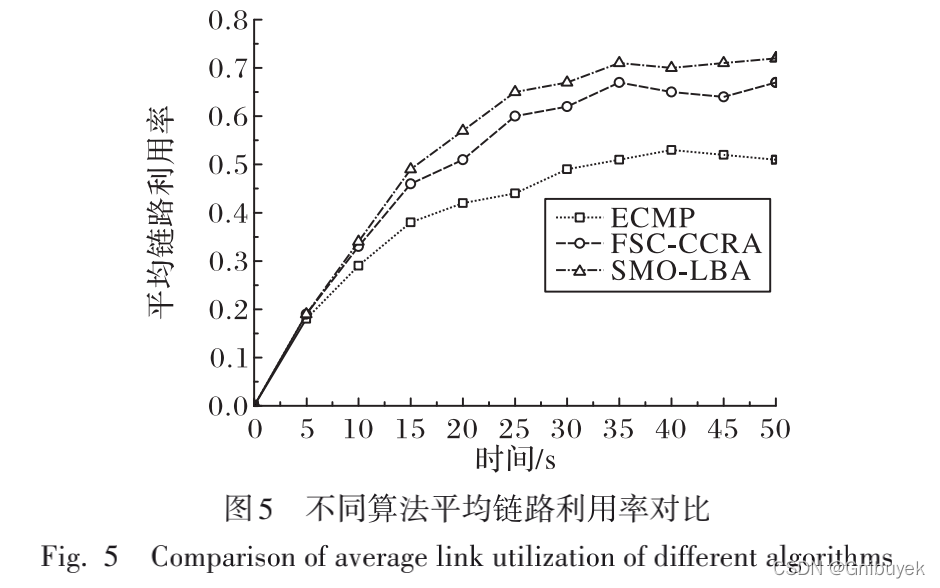
(3)平均链路利用率
取所有链路利用率的平均值,表示为网络运行时所有链路的占用带宽与总带宽之比:
其中 表示在
时刻,数据在第
条路径第
条链路的传输带宽;
为总的传输链路条数;
为链路的最大传输带宽。
SMO-LBA综合考虑了局部和全局的寻优,基于网络实时链路负载,选取全网最优转发路径,因此其平均链路利用率呈现一定的优越性。
3 结语
实际的网络传输场景要远比胖树网络拓扑复杂得多。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









